Doc2vec实现原理
1、Doc2vec概述
Doc2vec 和熟知的 Word2vec 类似,只不过 Word2vec 是训练词向量,而 Doc2vec 可以训练句子,段落,文档的向量表示。
Doc2vec 将文本向量化的应用解决了几个问题:
1)解决了文本中词之间的顺序问题
2)解决了文本中词的语义问题
3)解决了文本向量化后的高稀疏高维度的问题
4)解决了文本长度不均的问题,可以转变成等长的向量,适用于句子,段落和文本。
利用 Doc2vec 可以极大地提高在文本分类,情感分析等问题上的准确率
2、Doc2vec模型
Doc2vec 中的两个模型都是受到 word2vec 激发的。在 word2vec 中的CBOW模型是利用上下文的词预测中心词。其具体模型图如下:
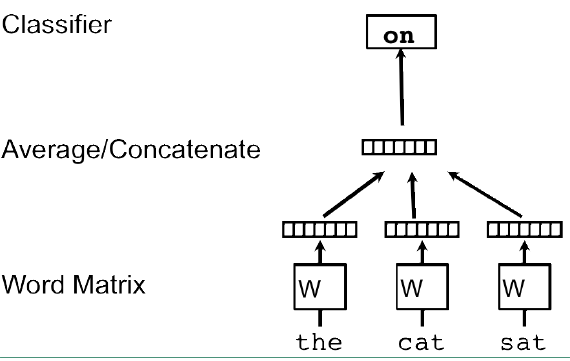
而在 Doc2vec 有个类似的模型,称为 Distributed Memory Model of Paragraph Vectors (PV-DM)。其具体模型结构如下图:
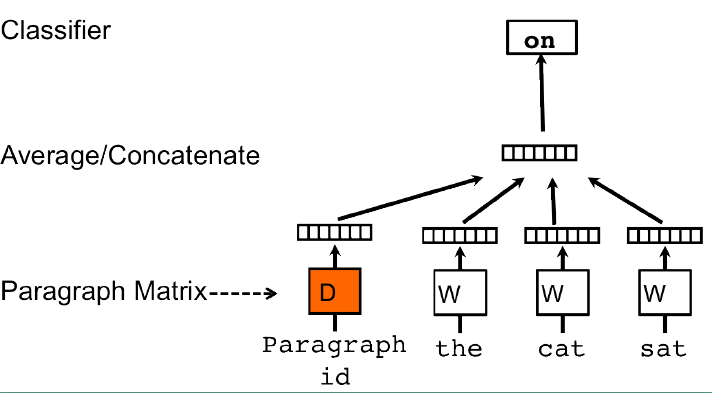
PV-DM 模型较 CBOW 的不同点就是引入了段落作为输入值。假设在我们的语料库中有 N 个段落、M 个词,段落映射后的向量长度为p,词映射后的向量长度为q。则整个模型的参数就是 N × p + M × q 。
而在输入值也是采用固定的滑动窗口来输入的。但是在这里段落该怎么处理呢?原文中是这么说的(不是很明确意思,各位自己理解):
The contexts are fixed-length and sampled from a sliding window over the paragraph. The paragraph vector is shared across all contexts generated from the same paragraph but not across paragraphs. The word vector matrix W, however, is shared across paragraphs. I.e., the vector for “powerful” is the same for all paragraphs。
对于这段话我的理解是,段落与段落之间是相互独立的,而词在所有段落之间是共享的。
在预测新的段落(不在语料库中)的向量时,固定词向量W 和 softmax时的权重 U 和偏置 b。将新的段落加入到矩阵D中,然后梯度下降求新段落的向量。
除了PV-DM 模型之外,还有一个 PV-DBOW (Distributed Bag ofWords version of Paragraph Vector)模型(该模型有点类似于skip-gram 模型)。具体的模型结构如下:
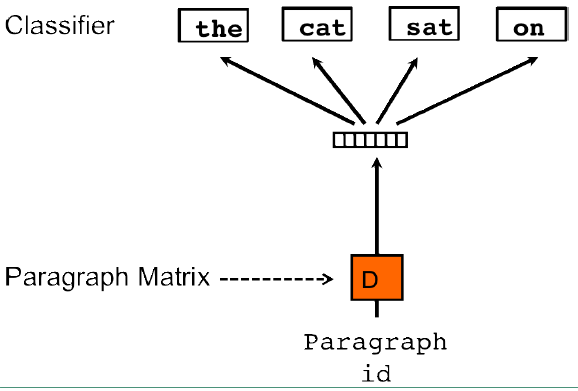
PV-DBOW 模型是一种忽略了上下文的方法。这个模型输入时段落矩阵,输出是从段落中随机采样的词,而且在每次梯度下降迭代时都会重新采样,以此来训练段落向量。
一般来说 PV-DM 模型就可以获得很好的结果,但是将 PV-DM 和 PV-DBOW 两个模型生成的向量结合起来的效果会更好。所以更推荐后者。
Doc2vec实现原理的更多相关文章
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用了CBOW(Continuous B ...
- Gensim进阶教程:训练word2vec与doc2vec模型
本篇博客是Gensim的进阶教程,主要介绍用于词向量建模的word2vec模型和用于长文本向量建模的doc2vec模型在Gensim中的实现. Word2vec Word2vec并不是一个模型--它其 ...
- 【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
环境 Python3, gensim,jieba,numpy ,pandas 原理:文章转成向量,然后在计算两个向量的余弦值. Gensim gensim是一个python的自然语言处理库,能够将文档 ...
- 基于Doc2vec训练句子向量
目录 一.Doc2vec原理 二.代码实现 三.总结 一.Doc2vec原理 前文总结了Word2vec训练词向量的细节,讲解了一个词是如何通过word2vec模型训练出唯一的向量来表示的.那接着 ...
- 奇异值分解(SVD)原理与在降维中的应用
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- 线性判别分析LDA原理总结
在主成分分析(PCA)原理总结中,我们对降维算法PCA做了总结.这里我们就对另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 以下简称LDA)做一个总结. ...
- [原] KVM 虚拟化原理探究(1)— overview
KVM 虚拟化原理探究- overview 标签(空格分隔): KVM 写在前面的话 本文不介绍kvm和qemu的基本安装操作,希望读者具有一定的KVM实践经验.同时希望借此系列博客,能够对KVM底层 ...
随机推荐
- Java高并发--线程安全策略
Java高并发--线程安全策略 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 不可变对象 发布不可变对象可保证线程安全. 实现不可变对象有哪些要注意的地方?比如JDK ...
- Java中枚举的使用
Java中枚举其实就是静态常量,今天发现枚举里面其实还能加方法,学习了下, 代码如下: package org.pine.test; import java.util.HashMap; import ...
- 封装个 Android 的高斯模糊组件
本篇文章已授权微信公众号 hongyangAndroid (鸿洋)独家发布 最近基于 Android StackBlur 开源库,根据自己碰到的需求场景,封装了个高斯模糊组件,顺便记录一下. 为什么要 ...
- Android为TV端助力 最详细的动画大全,包括如何在代码和在XML中使用
一.动画类型 Android的animation由四种类型组成:alpha.scale.translate.rotate XML配置文件中 alpha 渐变透明度动画效果 scale 渐变尺寸伸缩动画 ...
- Android为TV端助力 遥控器的映射
第一编写kl文件时先在盒子上输入getevent -v查看设备信息,设备信息里有vendor.product.version, 假如分别是xxxx,yyyy,zzzz,那么你的文件名就要命名为Vend ...
- Android 内存管理中的 Shallow heap Retained heap
所有包含Heap Profling功能的工具(MAT,Yourkit,JProfiler,TPTP等)都会使用到两个名词,一个是Shallow heap Size,另一个是 Retained heap ...
- android 圆角背景
<?xml version="1.0" encoding="utf-8"?> <shape xmlns:android="http: ...
- OneAPM大讲堂 | 提高JavaScript性能的30个技巧
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 您是网站管理员还是网页开发人员?想创建超快速的网站吗? 今天我们来看看 JavaScript,这项神奇而又复杂的技术.它使网站内容 ...
- weblogic系列漏洞整理 -- 5. weblogic SSRF 漏洞 UDDI Explorer对外开放 (CVE-2014-4210)
目录 五. weblogic SSRF 漏洞 UDDI Explorer对外开放 (CVE-2014-4210) 1. 利用过程 2. 修复建议 一.weblogic安装 http://www.cnb ...
- SQL 中常用存储过程xp_cmdshell运行cmd命令
目的: 使用SQL语句,在D盘创建一个文件夹myfile 首先查询系统配置 SELECT * FROM sys.configurations WHERE name='xp_cmdshell' OR n ...