AI学习---基于TensorFlow的案例[实现线性回归的训练]
- 线性回归原理复习
1)构建模型
|_> y = w1x1 + w2x2 + …… + wnxn + b
2)构造损失函数
|_> 均方误差
3)优化损失
|_> 梯度下降

- 实现线性回归的训练
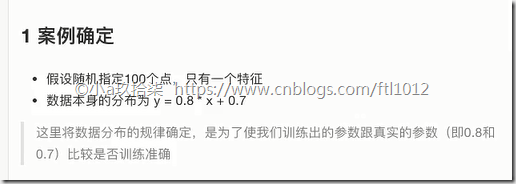
准备真实数据
100样本
x 特征值 形状 (100, 1) 100行1列
y_true 目标值 (100, 1)
y_true = 0.8x + 0.7 假设特征值和目标值直接的线性关系
假定x 和 y 之间的关系 满足
y = kx + b
k ≈ 0.8 b ≈ 0.7
流程分析:
(100, 1) * (1, 1) = (100, 1)
y_predict = x * weights(1, 1) + bias(1, 1)
1)构建模型: 矩阵:matmul
y_predict = tf.matmul(x, weights) + bias
2)构造损失函数: 平均:reduce_mean 平方: square
error = tf.reduce_mean(tf.square(y_predict - y_true))
3)优化损失: 梯度下降的评估器GradientDescentOptimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error)
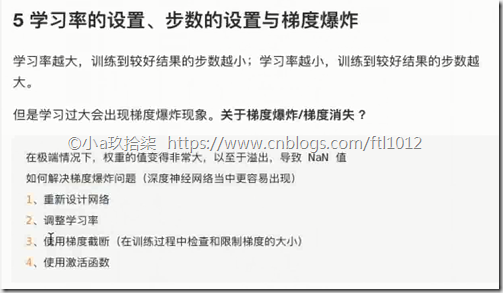
5 学习率的设置、步数的设置与梯度爆炸
- 案例确定
- API

- 步骤分析
demo:
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' def linear_regression():
"""
自实现一个线性回归
:return:
"""
# 1)准备数据
with tf.variable_scope(name_or_scope='prepare_data'):
X = tf.random_normal(shape=[100, 1], mean=2)
y_true = tf.matmul(X, [[0.8]]) + 0.7 # [[0.8]] 定义了一个一行一列 # 2)构造模型
# 定义模型参数 用 变量
with tf.variable_scope("create_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) # 随机产生一个一行一列
bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) # 随机产生一个一行一列
y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数: 均方误差
with tf.variable_scope("loss_function"):
error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失
with tf.variable_scope("optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 默认0.01 # 显式地初始化变量
init = tf.global_variables_initializer() with tf.Session() as sess: # 初始化变量
sess.run(init)
# 查看初始化模型参数之后的值
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval()))
# 开始训练
for i in range(10):
sess.run(optimizer)
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) if __name__ == "__main__":
linear_regression()
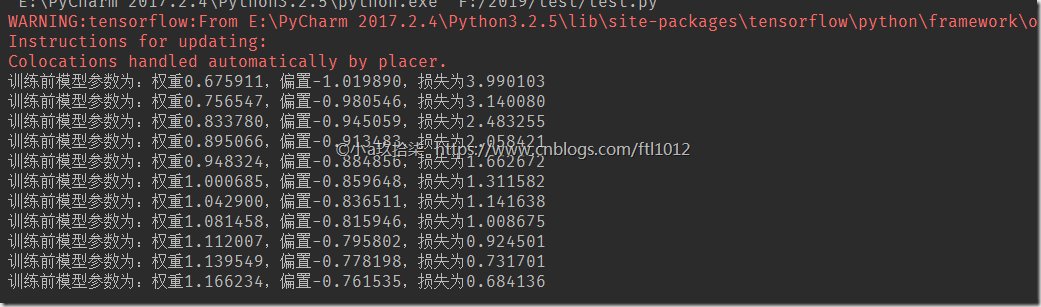
经过上面的训练我们可以发现,在学习率不变的情况下,迭代的次数越多,则效果越好。同理在迭代次数一定的情况下,学习率越高效果越好,但也是有一定限制的。
- 学习率的设置、步数的设置与梯度爆炸
- 变量的trainable设置观察

增加TensorBoard显示
1)创建事件文件
2)收集变量
3)合并变量
4)每次迭代运行一次合并变量
5)每次迭代将summary对象写入事件文件

变量dashboard显示demo:
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' def linear_regression():
"""
自实现一个线性回归
:return:
"""
# 第一步:
# 1)准备数据
X = tf.random_normal(shape=[100, 1], mean=2)
y_true = tf.matmul(X, [[0.8]]) + 0.7 # [[0.8]] 定义了一个一行一列 # 2)构造模型
# 定义模型参数 用 变量
# trainable=False,的时候则后面的权重会不变,导致损失也不会变化太久,默认True
weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), trainable=True) # 随机产生一个一行一列
bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) # 随机产生一个一行一列
y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数: 均方误差
error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 显式地初始化变量
init = tf.global_variables_initializer() # 第二步:收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias) # 第三步:合并变量
merged = tf.summary.merge_all() with tf.Session() as sess: # 初始化变量
sess.run(init) # 1_创建事件文件
file_writer = tf.summary.FileWriter("./tmp/", graph=sess.graph) # 查看初始化模型参数之后的值
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval()))
# 开始训练
for i in range(100):
sess.run(optimizer)
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 运行合并变量操作
summary = sess.run(merged)
# 将每次迭代后的变量写入事件文件
file_writer.add_summary(summary, i) # i是迭代次数 if __name__ == "__main__":
linear_regression()
Tensorboard的可视化:http://ftl2018:6006/#graphs&run=.(火狐浏览器)

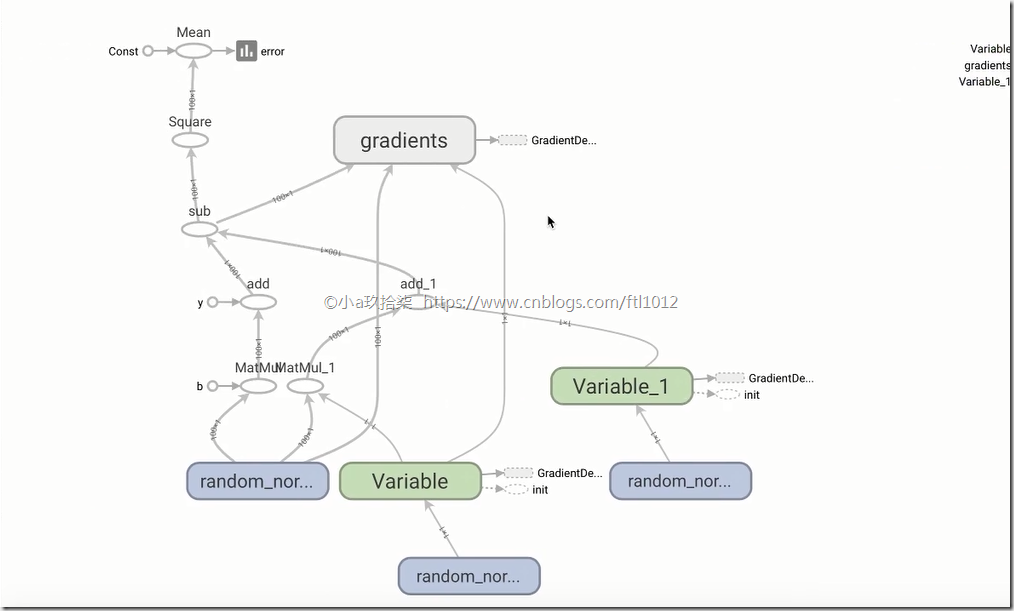
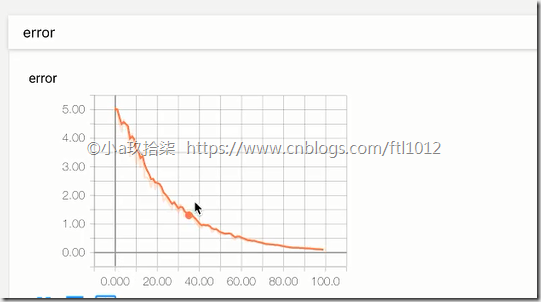
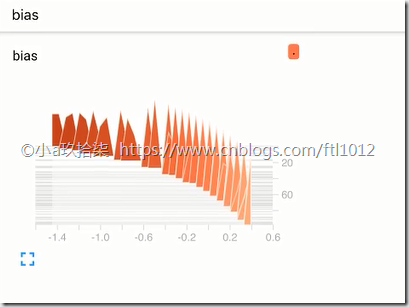
- 增加命名空间
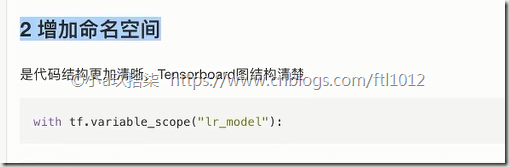
增加命名空间demo
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' def linear_regression():
"""
自实现一个线性回归
:return:
"""
# 第一步:
# 1)准备数据
with tf.variable_scope(name_or_scope='prepare_data'):
X = tf.random_normal(shape=[100, 1], mean=2, name='feature')
y_true = tf.matmul(X, [[0.8]]) + 0.7 # [[0.8]] 定义了一个一行一列 # 2)构造模型
# 定义模型参数 用 变量
# trainable=False,的时候则后面的权重会不变,导致损失也不会变化太久,默认True
with tf.variable_scope("create_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), trainable=True, name='weights') # 随机产生一个一行一列
bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name='bias') # 随机产生一个一行一列
y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数: 均方误差
with tf.variable_scope("loss_function"):
error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失
with tf.variable_scope("optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 显式地初始化变量
init = tf.global_variables_initializer() # 第二步:收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias) # 第三步:合并变量
merged = tf.summary.merge_all() with tf.Session() as sess: # 初始化变量
sess.run(init) # 1_创建事件文件
file_writer = tf.summary.FileWriter("./tmp/", graph=sess.graph) # 查看初始化模型参数之后的值
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval()))
# 开始训练
for i in range(100):
sess.run(optimizer)
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 运行合并变量操作
summary = sess.run(merged)
# 将每次迭代后的变量写入事件文件
file_writer.add_summary(summary, i) # i是迭代次数 if __name__ == "__main__":
linear_regression()

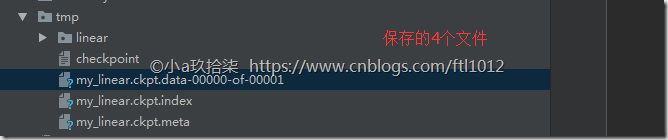
- 模型保存于加载
saver = tf.train.Saver(var_list=None,max_to_keep=5)
1)实例化Saver
2)保存
saver.save(sess, path)
3)加载
saver.restore(sess, path)
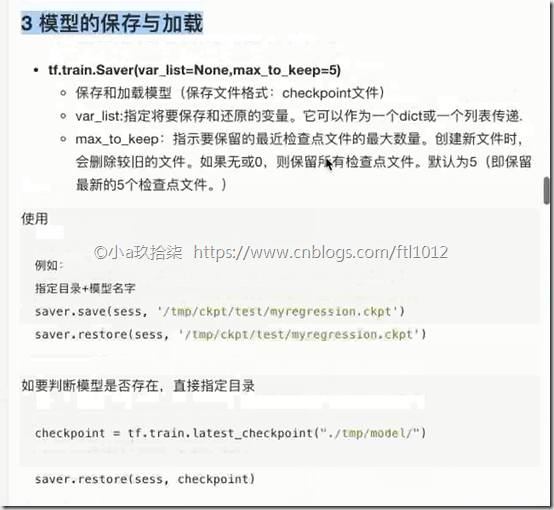
模型保存(需要提前准备好目录)与加载demo
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' def linear_regression():
"""
自实现一个线性回归
:return:
"""
# 第一步:
# 1)准备数据
with tf.variable_scope(name_or_scope='prepare_data'):
X = tf.random_normal(shape=[100, 1], mean=2, name='feature')
y_true = tf.matmul(X, [[0.8]]) + 0.7 # [[0.8]] 定义了一个一行一列 # 2)构造模型
# 定义模型参数 用 变量
# trainable=False,的时候则后面的权重会不变,导致损失也不会变化太久,默认True
with tf.variable_scope("create_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), trainable=True, name='weights') # 随机产生一个一行一列
bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name='bias') # 随机产生一个一行一列
y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数: 均方误差
with tf.variable_scope("loss_function"):
error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失
with tf.variable_scope("optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 显式地初始化变量
init = tf.global_variables_initializer() # 第二步:收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias) # 第三步:合并变量
merged = tf.summary.merge_all() # 保存模型:创建Saver对象
saver = tf.train.Saver(max_to_keep=5) with tf.Session() as sess: # 初始化变量
sess.run(init) # 1_创建事件文件
file_writer = tf.summary.FileWriter("./tmp/", graph=sess.graph) # 查看初始化模型参数之后的值
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval()))
# 开始训练
for i in range(100):
sess.run(optimizer)
print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 运行合并变量操作
summary = sess.run(merged)
# 将每次迭代后的变量写入事件文件
file_writer.add_summary(summary, i) # i是迭代次数 # 保存模型(保存模型参数,而参数在会话中)--》路径需要先创建好
if i % 10 == 0:
saver.save(sess, "./tmp/my_linear.ckpt")
# # 加载模型
# if os.path.exists("./tmp/model/checkpoint"):
# saver.restore(sess, "./tmp/model/my_linear.ckpt") if __name__ == "__main__":
linear_regression()
- 命令行参数设置
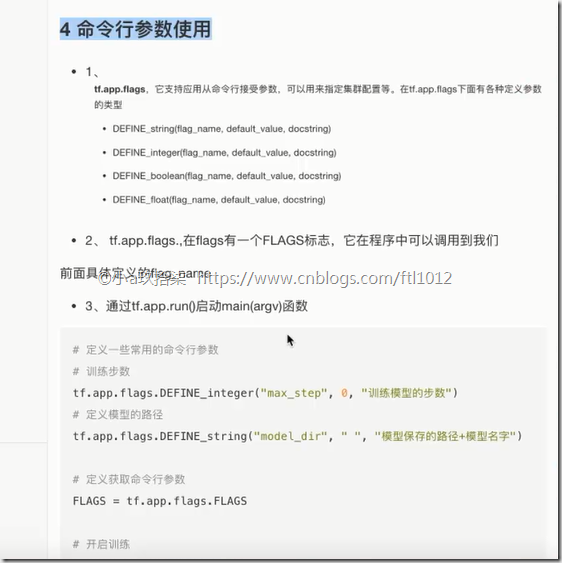
命令行参数使用
1)tf.app.flags
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
2)FLAGS = tf.app.flags.FLAGS
通过FLAGS.max_step调用命令行中传过来的参数
3、通过tf.app.run()启动main(argv)函数

具体调用:
命令行demo
import tensorflow as tf
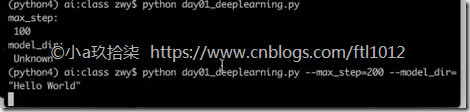
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 1)定义命令行参数
tf.app.flags.DEFINE_integer("max_step", 100, "训练模型的步数")
tf.app.flags.DEFINE_string("model_dir", "Unknown", "模型保存的路径+模型名字") # 2)简化变量名
FLAGS = tf.app.flags.FLAGS def command_demo():
"""
命令行参数演示
:return:
"""
print("max_step:\n", FLAGS.max_step)
print("model_dir:\n", FLAGS.model_dir) return None def main(argv):
print("code start", argv)
return None if __name__ == "__main__":
# 命令行参数演示
# command_demo()
tf.app.run()
AI学习---基于TensorFlow的案例[实现线性回归的训练]的更多相关文章
- AI学习---深度学习&TensorFlow安装
深度学习 深度学习学习目标: 1. TensorFlow框架的使用 2. 数据读取(解决大数据下的IO操作) + 神经网络基础 3. 卷积神经网络的学习 + 验证码识别的案例 机器学习与深度学 ...
- 基于TensorFlow Serving的深度学习在线预估
一.前言 随着深度学习在图像.语言.广告点击率预估等各个领域不断发展,很多团队开始探索深度学习技术在业务层面的实践与应用.而在广告CTR预估方面,新模型也是层出不穷: Wide and Deep[1] ...
- (第一章第六部分)TensorFlow框架之实现线性回归小案例
系列博客链接: (一)TensorFlow框架介绍:https://www.cnblogs.com/kongweisi/p/11038395.html (二)TensorFlow框架之图与Tensor ...
- 基于TensorFlow的深度学习系列教程 2——常量Constant
前面介绍过了Tensorflow的基本概念,比如如何使用tensorboard查看计算图.本篇则着重介绍和整理下Constant相关的内容. 基于TensorFlow的深度学习系列教程 1--Hell ...
- 基于TensorFlow的深度学习系列教程 1——Hello World!
最近看到一份不错的深度学习资源--Stanford中的CS20SI:<TensorFlow for Deep Learning Research>,正好跟着学习一下TensorFlow的基 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- 数十种TensorFlow实现案例汇集:代码+笔记(转)
转:https://www.jiqizhixin.com/articles/30dc6dd9-39cd-406b-9f9e-041f5cbf1d14 这是使用 TensorFlow 实现流行的机器学习 ...
- AI 学习路线
[导读] 本文由知名开源平台,AI技术平台以及领域专家:Datawhale,ApacheCN,AI有道和黄海广博士联合整理贡献,内容涵盖AI入门基础知识.数据分析挖掘.机器学习.深度学习.强化学习.前 ...
随机推荐
- 第4章 DHCP服务
基础服务类系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html DHCP前身是BOOTP,在Linux的网卡配置中也能看到显示的是BOOTP,D ...
- vsphere 虚拟机的迁移,冷迁移,vmotion(热迁移)
备注:(理论部分参考王春海老师的课程) 一.概述 1.vsphere数据中心当处于某种目的进行维护时,需要将某台主机上运行或关闭的虚拟机,迁移到其他主机上,这个时候就需要使用迁移 2.可以使用冷迁移或 ...
- LeetCode-63. 不同路径 II
最近英文版的访问特别慢,转战中文吧 和上一题一样,递归会超时 //63 不同路径2,递归解法 int uniquePaths2(vector<vector<int>>& ...
- 用 pyinstaller 打包含xpinyin 库的Python程序
在文章用 pyinstaller 打包含有 pinyin 库的程序中,给出了如何使用pyinstaller 打包含xpinyin 库的Python程序的方法,能生成可运行的exe文件.本文将会给出 ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- c# nginx 配置
listen ; #端口 server_name localhost; #域名可以有多个 用空格隔开 #charset koi8-r; #access_log logs/host.access.log ...
- Elastic-Job-分布式调度解决方案
Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成. Elastic-Job-Lite定位为轻量级无中心化解 ...
- confidence interval
95%置信区间.置信区间的两端被称为置信极限.对一个给定情形的估计来说,置信水平越高,所对应的置信区间就会越大. 对置信区间的计算通常要求对估计过程的假设(因此属于参数统计),比如说假设估计的误差是成 ...
- 汇编语言--微机CPU的指令系统(五)(移位操作指令)
(5) 移位操作指令 移位操作指令是一组经常使用的指令,它包括算术移位.逻辑移位.双精度移位.循环移位和带进位的循环移位等五大类. 移位指令都有指定移动二进制位数的操作数,该操作数可以是立即数或CL的 ...
- TS学习随笔(一)->安装和基本数据类型
去年学过一段时间的TS,但由于在工作中不常用.就生疏了,最近项目要求用TS,那我就再回去搞搞TS,写一篇记录一下自己学习TS的进度以及TS知识点 首先,关于TS的定义我就不在这描述了,想看百度一下你就 ...