数据库之mysql篇(3)—— mysql创建/修改数据表/操作表数据
创建数据表:create table 数据表名
1.创建表规范
create table 表名(
列名 数据类型 是否为空 自动排序/默认值 主键/外键/唯一键,
列名 数据类型 是否为空 默认值 外键/唯一键
) ENGINE=InnoDB default charset=utf8;
强制创建数据库:create database if not exists 数据库名;
数据类型不用再说了
是否为空 not null/null
- not null:表示不能为空
- null:表示可以为空
默认值 default
default XX:表示此列的数据默认为XX
自动排序 auto_increment:表示根据列插入数据的先后顺序自动排序
注意:自动排序和默认值不能同时设定在一个列上,并且自动排序必须是主键/唯一键其中一个
主键:primary key
一张表只能有一个主键,主键是唯一不重复,并且不能为null,所以一般直接把自动排序列设置为主键
唯一键:unique key
唯一键,顾名思义,唯一不重复,但可以为null,但一张表可以有多个唯一键
外键:foreign key
如果一张表中有一个非主键的字段指向了别一张表中的主键,就将该字段叫做外键。
一张表中可以有多个外键,用于将当前表以设定的该列联系其他数据表

1)创建外键
首先需要两张表,先创建一个part部门表,此时的部门表暂且认定为主表

插入一些数据得:
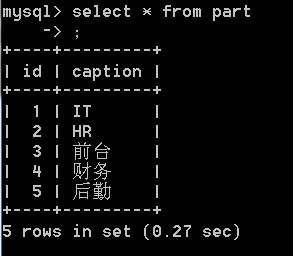
再创建一个user员工表,此时的员工表设定为从表,在创建员工表时,把part_id作为foreign key,以此作为部门表的联系。
注意:外键设置都设置在从表上,子表(从表)的外键必须和父表(主表)的关联主键类型一致,不然报错
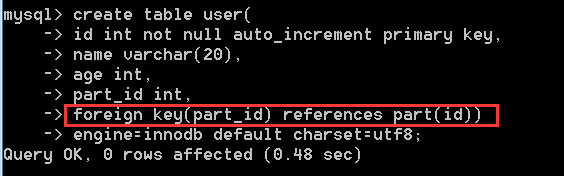
插入数据,如果插入的数据不在外键约束好的数据内,则会报错:

这就是外键的功效。具体在什么时候使用呢?就是在表与表之间有联系且不能有差异时,可以使用外键
2)删除外键:先删除外键名,再删外键字段
3)删除带有外键的数据表:先删除从表,再删除主表
4)外键约束操作:

cascade创建:当父表的id某字段删除时,子表也跟着删除
mysql> create table users1(
-> id smallint unsigned primary key auto_increment,
-> username varchar(20) not null,
-> pid smallint unsigned,
-> foreign key (pid) references provinces(id) on delete cascade #依据provinces表的外键约束方式cascade
5)约束:
主键,唯一键,外键,默认值的功效都是约束的作用

ENGINE
就是数据库引擎,mysql默认支持的数据引擎:INNODB,BERKLEY,ISAM,MYISAM,HEAP
最常用的就InnoDB和Myisam
- Myisam:支持全文索引,查询数据时老快了
- Innodb:支持事物,原子性操作
原子性操作:设置和修改数据只有两种结果,要嘛成功要嘛不成功,设置中途如果出错,所有相关数据会回滚到之前未操作的状态
default charset = utf8:创建表时设定此表的字符编码为utf8
查看当期数据表的编码等信息:show create table 表名;/show full columns from 表名;
2.范例
1)一般创建法

2)也可以设置好后在后面插入,并且主键可以设置复合键,处的id和name复合在一起同属一个主键
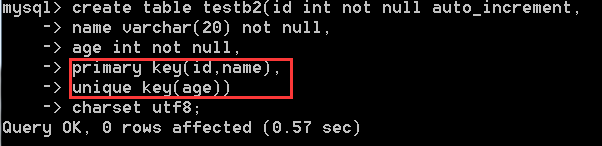
注意:在创建表时最后一行不加逗号,不然报错
插入数据:

注意:当设置有自动排序时,插入数据不需要再给定列名和数据,它会自动生成
3.删除数据表:drop table 数据表名

4.查看数据
1)数据表信息:show columns from 数据表名;
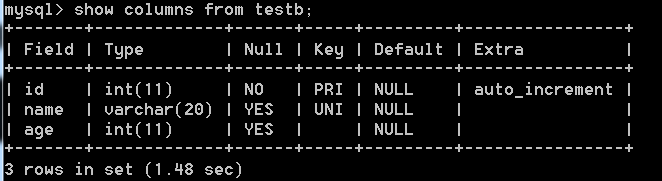
2)查看表数据:select × from 表名;
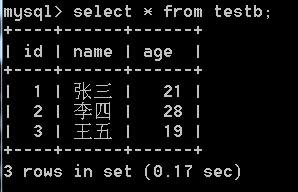
如果数据很多,加上‘\G’表示以网格的形态呈现索引:

5.修改表:alter table 数据表名
1).添加
1)添加列: alter table 表名 add 列名 数据类型;
2)添加主键:alter table 表名 add primary key(列名);
3)添加外键:alter table 表名 add constraint 外键名称(随意,注意顾名思义) foreign key 从表(外键字段) references 主表(主键字段)
4)修改数据库编码:alter database 库名 character set=utf8;
5)修改数据表编码:alter table 表名 charset= utf8;
2).重设
1)重设默认值:alter table 表名 alter 字段 set default 值;
2)重设列:
alter table 表名 modify column 列名 类型; -- 类型alter table 表名 change 原列名 新列名 类型; -- 列名,类型
注意:当把数据类型由大类型改为小类型,有可能数据会丢失
3).删除
1)删除列:alter table 表名 drop 列名
2)删除多列:aler table 表名 drop 列名,列名,列名
3)删除外键:alter table 表名 modify 列名
4)删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
5)删除的同时新增一列:注意用逗号隔开就行

6)删除主键:
注意:一个表只能有个一个主键,所以删除主键时可以不用给列名。
修改列名时,如果列名是主键约束并且自动排列,直接修改会报错:

原因在于mysql不能单独定义两个主键
正确步骤:
a.先删除自增长(此时可以改名)

b.再删除主键:

c.再重新设置列定义:

此时的unsigned表示无符号的意思,也就是非负数,只用于整型
6.更新数据:updata table 表名 set 列名 = 值
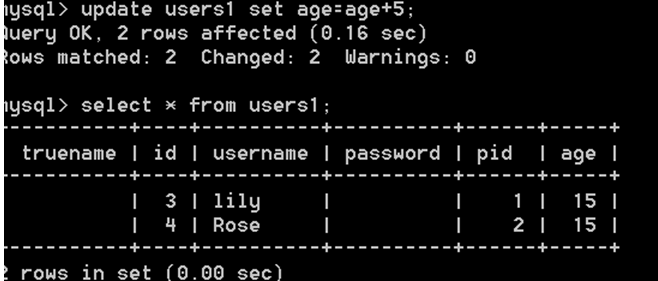
表数据操作
1.清空表数据:
- delete from 数据表名,逐条删除(速度较慢)
- truncate table 数据表名,整体删除(速度较快)
- DELETE FROM 数据表名 WHERE……,删除某一列满足条件的数据
2.对表数据增删改查:
1)增:
insert into 表 (列名,列名...) values (值,值,值...)【插入单条数据】
insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...)【插入多条数据】
insert into 表 (列名,列名...) select (列名,列名...) from 表【把查询到的其他表数据插入】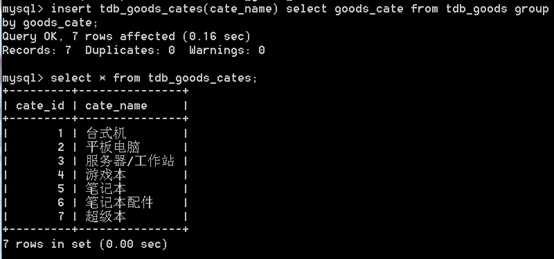
delete from 表【删除/清空数据】
delete from 表 where id=1 and name='字段' 【删除某一段符合条件的数据】update 表 set 列名与字段关系(如name ='test') where 列名与字段关系(如id >4)
select * from 表【查询表的所有数据】
select * from 表 where ... 【查询满足条件的字段数据】select 列名 as .. from 表 ... 【查询满足条件的表中所有数据】a、条件 where
select * from 表 where id > 1 and name != 'alex' and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表)b、通配符 * select * from 表 where name like 'ale%' - ale开头的所有(多个字符串) select * from 表 where name like 'ale_' - ale开头的所有(一个字符)c、限制 limit select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行d、排序 order by select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序e、分组 group by /having使用having,必须保证分组条件为聚合函数或者这个字段必须出现在当前select语句中
聚合函数:max,min,average,sum,count等永远只有一个返回结果的函数
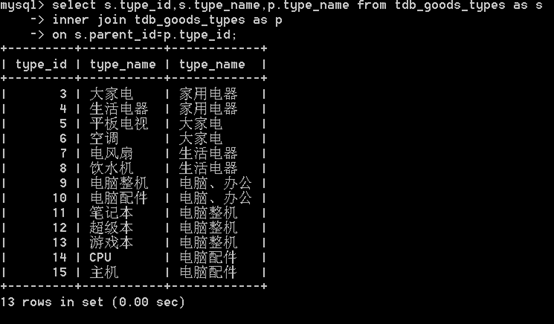
select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前f、连表 
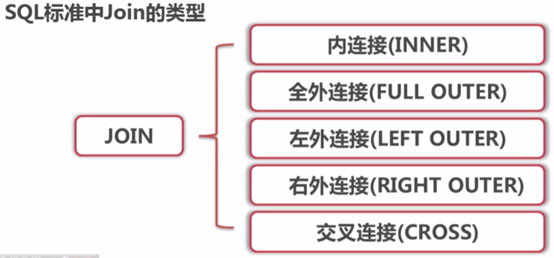

内连接:
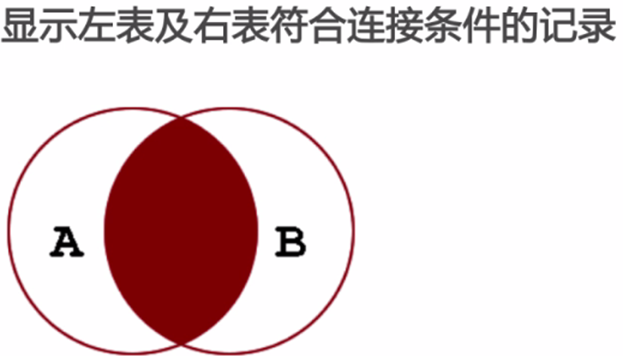

左外连接:
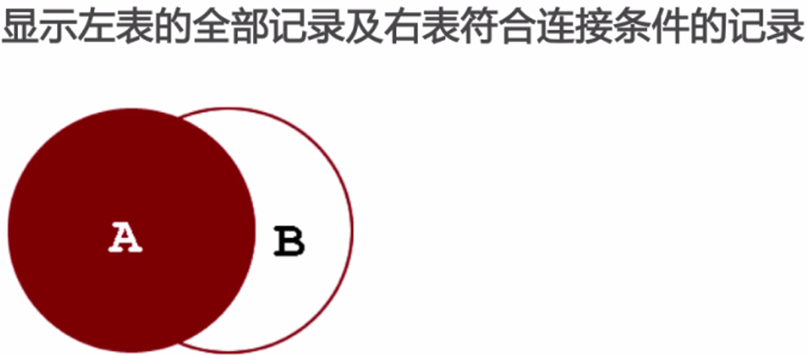
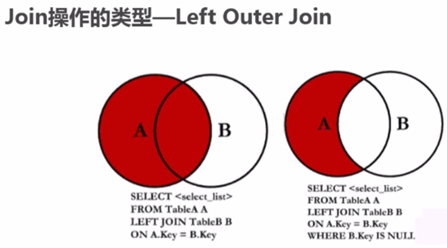
右外连接:

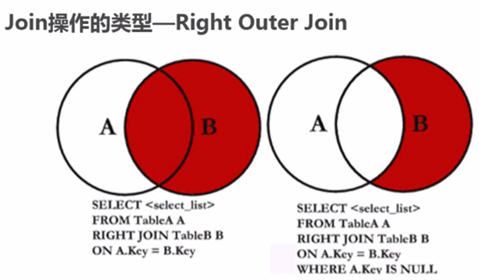
全连接,左右连接合集:
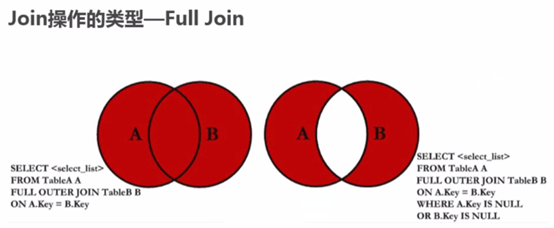
外连接:


自连接:同一个数据表对自身连接,但必须有一个别名区分
多表删除:

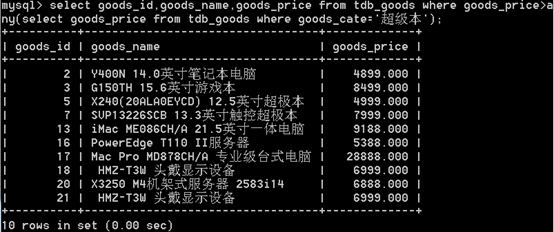
无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid 无对应关系则不显示 select A.num, A.name, B.name from A inner join B on A.nid = B.nid A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nidg、组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B6.使用any,some,all,in,not in,exists,not exists关键词操作

使用any参数:
7.mysql也支持比较运算符
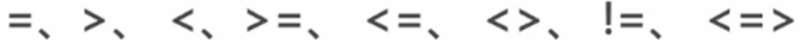
参考自:http://www.cnblogs.com/wupeiqi/articles/5713315.html
数据库之mysql篇(3)—— mysql创建/修改数据表/操作表数据的更多相关文章
- MySQL之终端(Terminal)管理数据库、数据表、数据的基本操作(转)
MySQL有很多的可视化管理工具,比如“mysql-workbench”和“sequel-pro-”. 现在我写MySQL的终端命令操作的文章,是想强化一下自己对于MySQL的理解,总会比使用图形化的 ...
- MySQL 数据库、数据表、数据的基本操作
1.数据库(database)管理 1.1 create 创建数据库 create database firstDB; 1.2 show 查看所有数据库 mysql> show database ...
- MySQL如果频繁的修改一个表的数据,那么这么表会被锁死。造成假死现象。
MySQL如果频繁的修改一个表的数据,那么这么表会被锁死.造成假死现象. 比如用Navicat等连接工具操作,Navicat会直接未响应,只能强制关闭软件,但是重启后依然无效. 解决办法: 首先执行: ...
- MySQL查询数据表中数据记录(包括多表查询)
MySQL查询数据表中数据记录(包括多表查询) 在MySQL中创建数据库的目的是为了使用其中的数据. 使用select查询语句可以从数据库中把数据查询出来. select语句的语法格式如下: sele ...
- oracle11g创建修改删除表
oracle11g创建修改删除表 我的数据库名字: ORCL 密码:123456 1.模式 2.创建表 3.表约束 4.修改表 5.删除表 1.模式 set oracle_sid=OR ...
- MySQL进阶11--DDL数据库定义语言--库创建/修改/删除--表的创建/修改/删除/复制
/*进阶 11 DDL 数据库定义语言 库和表的管理 一:库的管理:创建/修改/删除 二:表的管理:创建/修改/删除 创建: CREATE DATABASE [IF NOT EXISTS] 库名; 修 ...
- MySQL的数据库,数据表,数据的操作
数据库简介 概念 什么是数据库?简单来说,数据库就是存储数据的"仓库", 但是,光有数据还不行,还要管理数据的工具,我们称之为数据库管理系统! 数据库系统 = 数据库管理系统 + ...
- mysql 基本语法学习1(数据库、数据表、数据列的操作)
今天学习了一下mysql语法,并记录下来 1.mysql的数据库操作 /***1.操作数据库的语法 ***/ -- 1)显示所有数据库 -- show databases; -- 2)创建数据库 -- ...
- MySQL数据库 、数据表、数据的增删改查简版
数据库操作 # 增 CREATE(DATABASE | SCHEMA)[IF NOT EXISTS] db_name [[DEFAULT] CHARACTER SET[=]charset_name] ...
随机推荐
- 自动生成实体类和xml
1 首先eclipse需要安装一个插件 2 两个配置文件 1 generator.properties 2 generator.xml <?xml version="1.0" ...
- Python转页爬取某铝业网站上的数据
天行健,君子以自强不息:地势坤,君子以厚德载物! 好了废话不多说,正式进入主题,前段时间应朋友的请求,爬取了某铝业网站上的数据.刚开始呢,还是挺不愿意的(主要是自己没有完整的爬取过网上的数据哎,即是不 ...
- Jmeter连接Redis,获取Redis数据集
Redis(REmote DIctionary Server)是一个开源的内存数据结构存储,用作数据库,缓存和消息代理. 本博文是分享jmeter怎么连接使用Redis数据库. 安装Redis数据集J ...
- Perl:写POD文档
官方手册:https://perldoc.perl.org/perlpod.html POD文档是perl的man文档,可以用perldoc输出,也可以直接用man输出.在开始下面的文章之前,请先粗略 ...
- 使用sublime text3编写vuejs项目需要安装的一些插件
最近使用webstorm开发vuejs项目的时候经常出现卡顿的现象,感觉还是sublime text3比较轻巧便捷,但是使用sublime text3需要安装一些插件- 1. 让vue文件高亮: 安装 ...
- [译]如何在.NET Core中使用System.Drawing?
你大概知道System.Drawing,它是一个执行图形相关任务的流行的API,同时它也不属于.NET Core的一部分.最初是把.NET Core作为云端框架设计的,它不包含非云端相关API.另一方 ...
- [转]比特币测试链——Testnet介绍
本文转自:https://blog.csdn.net/wkb342814892/article/details/80796398 testnet使用详解需求需要搭建一个简单的交易测试场景,用于生成可查 ...
- 数据库 'xxxx' 的事务日志已满。若要查明无法重用日志中的空间的原因
一.出现的背景: 在SQL server中执行SQL语句出现如下图: 二.出现的原因: 我到数据库的服务器看了一下硬盘空间发现此数据库所在的D盘空间几乎已经用尽.如图: 三.解决方法: 第一种方法:直 ...
- 27.QT-QProgressBar动态实现多彩进度条(详解)
如下图所示: 效果如下: (gif录制的动画效果不好,所以颜色有间隙) 介绍 通过qss实现,只需要一个多彩背景图,通过QImage获取颜色,然后来设置进度条,便可以实现动态多彩进度条(根据图片设定颜 ...
- openjudge------ 日期的种类题目
描述TXT is a vegetable chicken,so 出题什么的完全不会啊! 干脆直接从网络上copy一题下来吧. 小明正在整理一批历史文献.这些历史文献中出现了很多日期.小明知道这些日期都 ...