利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询。
安装
在进行今天的任务之前我们需要安装二个框架,分别是Scrapy (1.1.0)和pymongo (3.2.2).
scrapy
如果你运行的的系统是osx或者linux,可以直接通过pip进行安装,而windows需要另外安装一些依赖,因为电脑的原因不对此进行讲解。
$ pip install Scrapy
一旦安装完成之后你可以直接在python shell当中输入下面的命令,倘若没有出现错误的话,说明已安装完成
>>> import scrapy
>>>
安装PyMongo和mongodb
因为系统是osx的,所以直接通过下面的语句就可以安装。
brew install mongodb
运行mongodb同样特别的简单,只需要在终端下面输入下面的语法:
mongod --dbpath=.
--dbpath是指定数据库存放的路径,运行之后会在该路径下面生成一些文件
 

下一步我们就需要安装PyMongo,同样采用pip的方式
$ pip install pymongo
Scrapy 项目
我们来创建一个新的scrapy的项目,在终端输入下面的语法
$ scrapy startproject stack
 

一旦上面的命令完成之后,scrapy会直接创建相应的文件,这些文件包含了基本的信息,便于你来修改相应的内容。
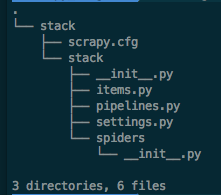 

定义数据
items.py文件用于我们定义需要抓取对象的存储的“容器“
有关StackItem()预定义时并让其继承于scrapy.Item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
这里我们需要在里面添加两个字段,分别用来存放抓取到的标题以及链接
from scrapy.item import Item,Field
class StackItem(Item):
# define the fields for your item here like:
title=Field()
url=Field()
创建爬虫
我们需要在spider文件夹下面创建一个stack_spider.py的文件,这个里面包容我们爬虫进行抓取时的行为。就是告诉爬虫我们需要抓取哪些内容以及内容的来源。
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name="stack"
allowed_domains=['stackoverflow.com']
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
- name 是定义爬虫的名称
- allowed_domains 指定爬虫进行爬取的域地址
- start_urls 定义爬虫需要抓取的网页的url地址
XPath 选择
scrapy使用XPath来进行匹配相应的数据的来源,html是一种标记的语法,里面定义了很多的标签和属性,比如说我们定义一个下面的这样的一个标签,这里我们就可以通过'//div[@class="content"]'来找到这个标记,找到之后我们可以取出其中的属性或者它的子节点
<div class='content'>
下面我们通过chrome来讲解如果找到xpath的路径 ,在进行操作之前我们需要打开开发者工具,可以点击菜单栏上面的视图->开发者->开发者工具来打进入开发者模式,或者可以根据快捷捷来进行打开。
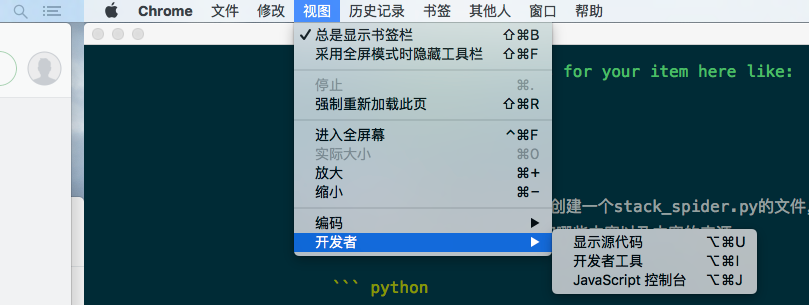 

打开之后我们在需要的内容上面点击右击会弹出一个菜单,这里我们可以选择检查来找到当前的内容在html相应的位置
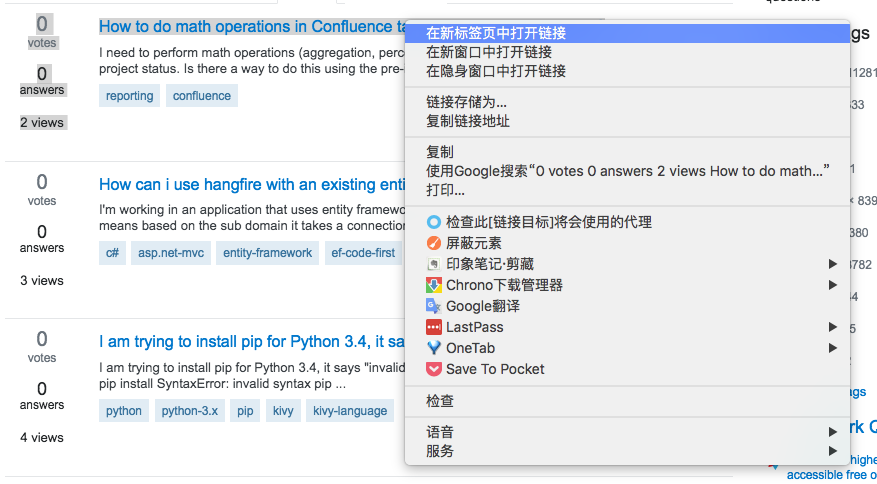 

这里chrome会自动帮助我们找到相应的位置,通过下面的分析,我们知道标题的路径是包含在一个
 

现在我们来更新相应的stack_spider.py脚本
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name="stack"
allowed_domains=['stackoverflow.com']
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self,response):
questions=Selector(response).xpath('//div[@class="summary"]/h3')
提取数据
创建抓取的规约之后,我们需要与刚才创建的items实体进行关联,我们继续修改stack_spider.py文件
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name="stack"
allowed_domains=['stackoverflow.com']
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self,response):
questions=Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item=StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
通过遍历所有的符合//div[@class="summary"]/h3的元素,并且从中找到我们真正需要爬取的元素内容
测试
现在我们进行测试,只要在项目的目录下面运行以下的脚本就可以进行测试 。
scrapy crawl stack
现在我们需要将爬取到的所有的信息保存到一个文件当中,可以在后面添加二个参数-o和-t
scrapy crawl stack -o items.json -t json
下面是实际保存的文件的内容分别包含了title和url
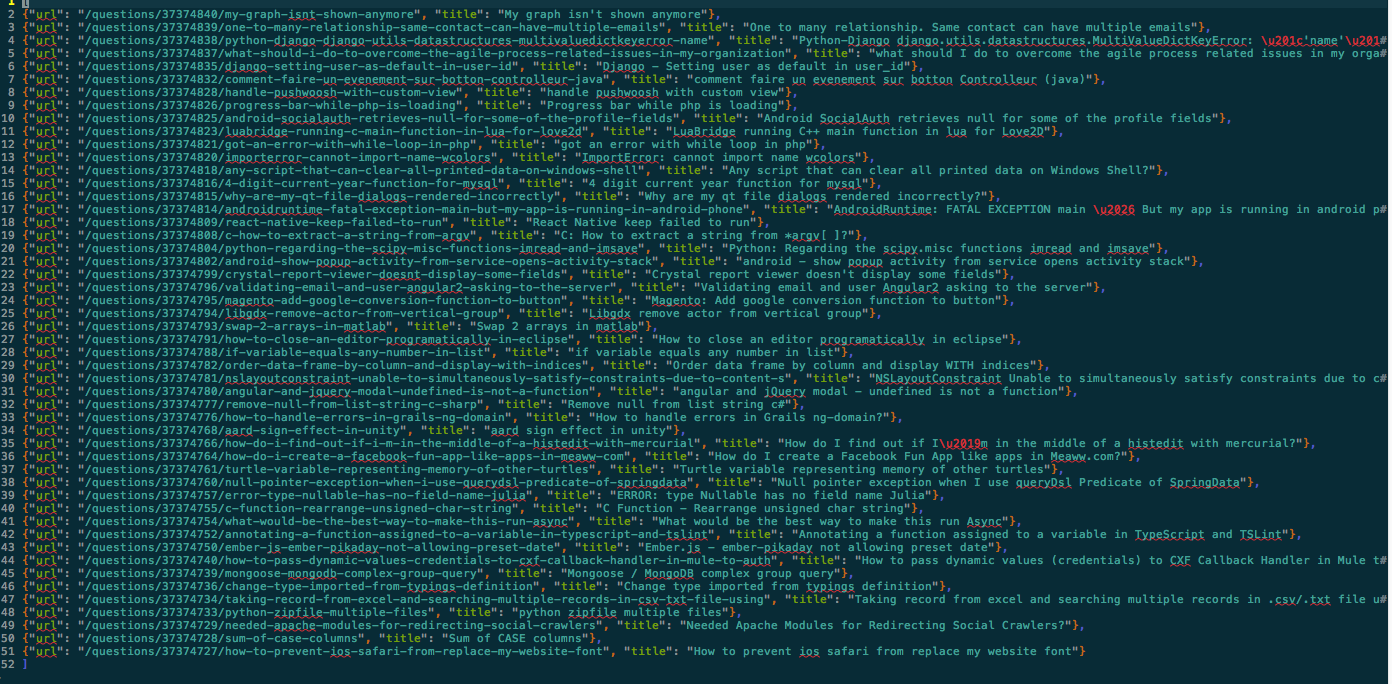 

将元素存放入MongoDB
这里我们需要将所有的元素保存到Mongodb collection当中。
在进行操作之前我们需要在setinngs.py指定相应的pipeline和添加一些数据库的参数
ITEM_PIPELINES = {
'stack.pipelines.MongoDBPipeline': 300,
}
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
pipeline 管理
在之前的步骤里面我们分别已经完成了对html的解析,以及指定数据的存储。但是这时所有的信息都在内存当中,我们需要将这些爬取到数据存储到数据库当中,这里就轮到pipelines.py上场了,这玩意就负责对数据的存储的。
在上面我们已经定义了数据库的参数,现在我们终于派上用场了。
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection=pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db=connection[settings['MONGODB_DB']]
self.collection=db[settings['MONGODB_COLLECTION']]
上面的代码是我们创建了一个MongoDBPipeline()的类,以及定义初始化函数,用来读取刚才的参数来创建一个Mongo的连接。
数据处理
下一步我们需要定义一个函数来处理解析的数据
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection=pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db=connection[settings['MONGODB_DB']]
self.collection=db[settings['MONGODB_COLLECTION']]
def process_item(self,item,spider):
valid=True
for data in item:
if not data:
valid=False
raise DropItem('Missing{0}!'.format(data))
if valid:
self.collection.insert(dict(item))
log.msg('question added to mongodb database!',
level=log.DEBUG,spider=spider)
return item
上面已经完成了对数据的连接,以及相应数据的存储
测试
我们同样在stack目录当中运行下面的命令
$ scrapy crawl stack
当内容执行完成之后没有出现任何的错误的提示,恭喜你已经将数据正确的存入到mongodb当中。
这里我们通过Robomongo来访问数据库的时候发现创建了一个stackoverflow的数据库,下面已经成功创建了一个名为questions的Collections.并且已经存入了相应的数据了。
 

利用scrapy和MongoDB来开发一个爬虫的更多相关文章
- python scrapy 入门,10分钟完成一个爬虫
在TensorFlow热起来之前,很多人学习python的原因是因为想写爬虫.的确,有着丰富第三方库的python很适合干这种工作. Scrapy是一个易学易用的爬虫框架,尽管因为互联网多变的复杂性仍 ...
- 如何利用scrapy新建爬虫项目
抓取豆瓣top250电影数据,并将数据保存为csv.json和存储到monogo数据库中,目标站点:https://movie.douban.com/top250 一.新建项目 打开cmd命令窗口,输 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- 利用scrapy抓取网易新闻并将其存储在mongoDB
好久没有写爬虫了,写一个scrapy的小爬爬来抓取网易新闻,代码原型是github上的一个爬虫,近期也看了一点mongoDB.顺便小用一下.体验一下NoSQL是什么感觉.言归正传啊.scrapy爬虫主 ...
- webmagic的设计机制及原理-如何开发一个Java爬虫
之前就有网友在博客里留言,觉得webmagic的实现比较有意思,想要借此研究一下爬虫.最近终于集中精力,花了三天时间,终于写完了这篇文章.之前垂直爬虫写了一年多,webmagic框架写了一个多月,这方 ...
- python爬虫实战:利用scrapy,短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题 ...
- Python下用Scrapy和MongoDB构建爬虫系统(1)
本文由 伯乐在线 - 木羊 翻译,xianhu 校稿.未经许可,禁止转载!英文出处:realpython.com.欢迎加入翻译小组. 这篇文章将根据真实的兼职需求编写一个爬虫,用户想要一个Python ...
- webmagic的设计机制及原理-如何开发一个Java爬虫 转
此文章是webmagic 0.1.0版的设计手册,后续版本的入门及用户手册请看这里:https://github.com/code4craft/webmagic/blob/master/user-ma ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
随机推荐
- js原生跨域--用script标签实现
刚刚从培训班学习完,总想写一下东西,自从进入了这个院子,每次出现问题,总是能找到一些答案,给我一些帮助. 作为新手,就写一下简单的吧,院子里面有很多大牛, 说句实话,他们的很多代码我都看不懂. 我就写 ...
- JavaScript 数据属性和访问器属性
在JavaScript中对象被定义为"无序属性的集合,其属性可以包含基本值.对象或函数."通俗点讲,我们可以把对象理解为一组一组的名值对,其中值可以是数据或函数. 创建自定义对象通 ...
- css和@import区别用法
css和@import都是调用外部样式表的方法. 一.用法 (1)link: <link rel="stylesheet" type="text/css" ...
- Android系统属性简介
查看Android源码你会发现,代码中大量存在:SystemProperties.set()/SystemProperties.get():通过这两个接口可以对系统的属性进行读取/设置,顾名思义系统属 ...
- React Native 之 组件化开发
前言 学习本系列内容需要具备一定 HTML 开发基础,没有基础的朋友可以先转至 HTML快速入门(一) 学习 本人接触 React Native 时间并不是特别长,所以对其中的内容和性质了解可能会有所 ...
- 【代码笔记】iOS-账号,密码记住
一,效果图. 二,工程图. 三,代码. RegisViewController.h #import <UIKit/UIKit.h> @interface RegisViewControll ...
- java代码走查审查规范
分类 重要性 检查项 备注 命名 重要 命名规则是否与所采用的规范保持一致? 成员变量,方法参数等需要使用首字母小写,其余单词首字母大写的命名方式,禁止使用下划线(_)数字等方式命名不 ...
- 简历生成平台项目开发-STEP3第一次项目例会探讨
时间:2016.7.13周三7点半 地点:图书馆 讨论主题:项目需求和功能分析.第一次任务分配 内容:按照之前的讨论,我们认为简历生成功能,不仅要适应学生求职的需求,更多的是要在格式和内容上满足HR的 ...
- 在Windows中玩转Docker Toolbox
最近在研究虚拟化,容器和大数据,所以从Docker入手,下面介绍一下在Windows下怎么玩转Docker. Docker本身在Windows下有两个软件,一个就是Docker,另一个是Docker ...
- Login控件尝试
新建web项目,添加default.aspx.Register.aspx.Login.aspx. default.aspx中添加LoginName.LoginStatus,LoginName的Form ...