python爬虫系列之初识爬虫
前言
我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握爬虫的基础知识,做网络爬虫还是需要基本的前端的知识的,下面我们进行我们的爬虫讲解
在进行实战之前,我们先给大家看下爬虫的一般讨论,方便大家看懂下面的实例

一、爬汽车之家
汽车之家这个网站没有做任何的防爬虫的限制,所以最适合我们来练手
1、导入我们要用到的模块
import requests
from bs4 import BeautifulSoup
2、利用requests模块伪造浏览器请求
# 通过代码伪造浏览器请求
res = requests.get("https://www.autohome.com.cn/news/")
3、设置解码的方式,python是utf-8,但是汽车之家是用gbk编码的,所以这里要设置一下解码的方式
# 设置解码的方式
res.encoding = "gbk"
4、把请求返回的对象,传递一个bs4模块,生成一个BeautifulSoup对象
soup = BeautifulSoup(res.text,"html.parser")
5、这样,我们就可以使用BeautifulSoup给我们提供的方法,如下是查找一个div标签,且这个div标签的id属性为auto-channel-lazyload-atricle
# find是找到相匹配的第一个标签
div = soup.find(name="div",attrs={"id":"auto-channel-lazyload-article"})
# 这个div是一个标签对象
6、findall方法,是超找符合条件的所有的标签,下面是在步骤5的div标签内查找所有的li标签
li_list = div.find_all(name="li")
7、查找li标签中的不同条件的标签
li_list = div.find_all(name="li")
for li in li_list:
title = li.find(name="h3")
neirong = li.find(name="p")
href = li.find(name="a")
img = li.find(name="img")
if not title:
continue
8、获取标签的属性
# print(title, title.text, sep="标题-->")
# print(neirong, neirong.text, sep="内容-->")
# print(href, href.attrs["href"], sep="超链接-->") # 获取标签对接的属性
# print(img.attrs["src"])
# ret = requests.get(img_src)
9、如果我们下载一个文件,则需要requests.get这个文件,然后调用这个文件对象的content方法
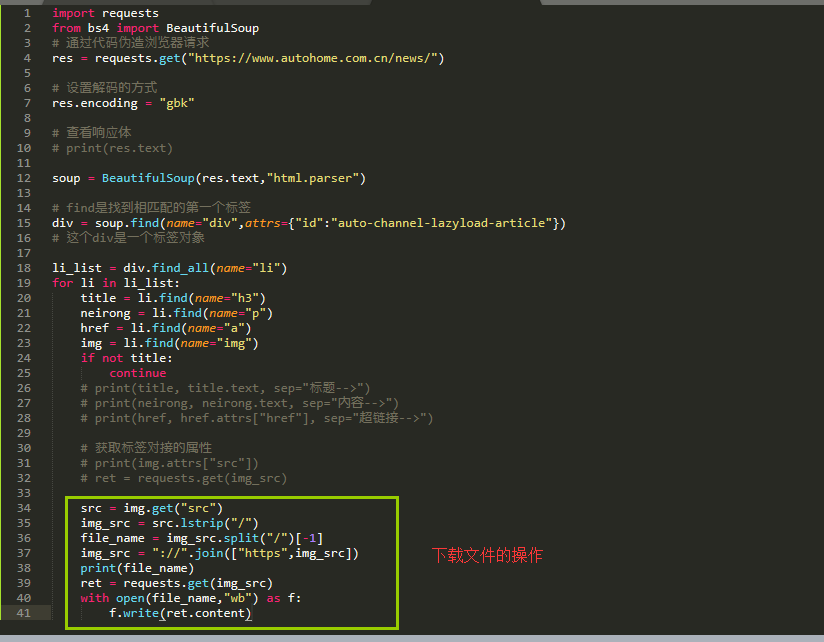
src = img.get("src")
img_src = src.lstrip("/")
file_name = img_src.split("/")[-1]
img_src = "://".join(["https",img_src])
print(file_name)
ret = requests.get(img_src)
with open(file_name,"wb") as f:
f.write(ret.content)
10、整体的代码如下
二、爬抽屉
这里我们看下如何爬抽屉
1、首先抽屉有做防爬虫的机制,我们在访问的时候必须要加一个请求头
# 实例1:爬取数据,这个网址有做防爬虫机制,所以需要带一个请求头信息,才能让服务端以为我们是浏览器,不然服务端会把我们的请求当做爬虫行为进行拦截
# 设置一个请求头
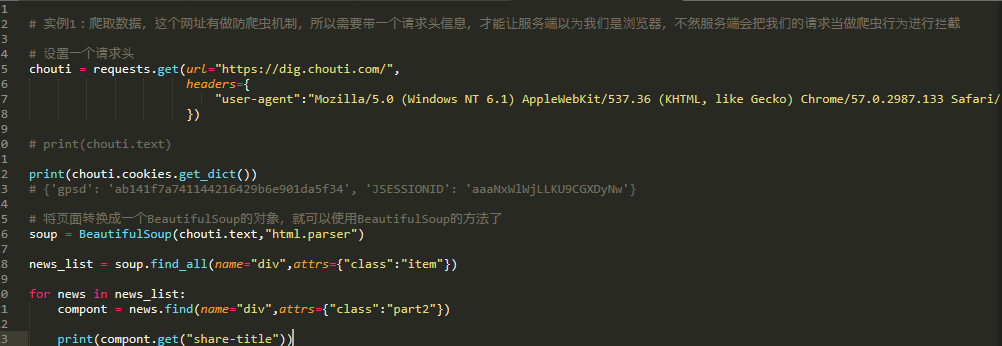
chouti = requests.get(url="https://dig.chouti.com/",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
})
2、这个请求网站会返回一个cookies,通过下面的方法获取cookies
print(chouti.cookies.get_dict())
# {'gpsd': 'ab141f7a741144216429b6e901da5f34', 'JSESSIONID': 'aaaNxWlWjLLKU9CGXDyNw'}
3、转换页面为一个BeautifulSoup对象
# 将页面转换成一个BeautifulSoup的对象,就可以使用BeautifulSoup的方法了
soup = BeautifulSoup(chouti.text,"html.parser") news_list = soup.find_all(name="div",attrs={"class":"item"}) for news in news_list:
compont = news.find(name="div",attrs={"class":"part2"}) print(compont.get("share-title"))
4、下面我们看下如何登陆抽屉
首先我们先通过get方式访问主页
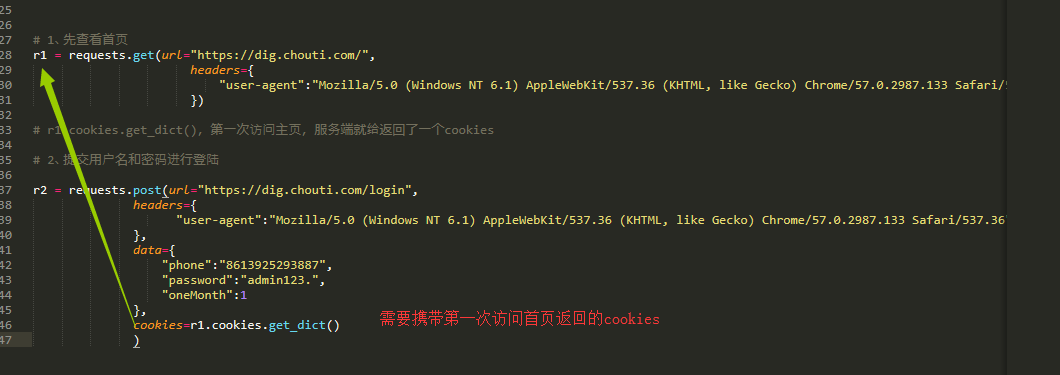
# 1、先查看首页
r1 = requests.get(url="https://dig.chouti.com/",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
})
然后我们通过post方式进行登陆,
# 2、提交用户名和密码进行登陆 r2 = requests.post(url="https://dig.chouti.com/login",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
},
data={
"phone":"86139252938822",
"password":"admin",
"oneMonth":1
},
cookies=r1.cookies.get_dict()
)
最后登陆成功后,我们来实现一个点赞的操作,这里要注意
# 第二次登陆的时候把第一次返回的cookies带上,这个是抽屉这个网站的套路,同样这次登陆也会返回一个cookies,但是登陆这次返回的cookies其实是个迷惑我们的cookies,没有用
# print(r2.text)
# 登陆失败返回的信息:{"result":{"code":"21101", "message":"手机号或密码错误", "data":{}}}
# 登陆成功返回的信息:{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_53218132468"}}} # 如果登陆成功,通过下面的方法就可以把服务端返回的cookies拿到,以后在发请求,带着cookies去就可以了
print(r2.cookies.get_dict())
# {'puid': 'b11ec95d3b515ae2677a01f6abd5b916', 'gpid': '01cff9a184bd427789429d1dd556f4d2'} r3 = requests.post(url="https://dig.chouti.com/link/vote?linksId=25461201",
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
},
# cookies=r2.cookies.get_dict(),
cookies=r1.cookies.get_dict(),
# 破解抽屉coookies套路
)
# 这次点赞,我们同样带的cookies是第一次登陆主页返回的cookies,而不是登陆成功后返回的cookies
# print(r3.text)

爬抽屉所有的代码如下
# 实例1:爬取数据,这个网址有做防爬虫机制,所以需要带一个请求头信息,才能让服务端以为我们是浏览器,不然服务端会把我们的请求当做爬虫行为进行拦截 # 设置一个请求头
chouti = requests.get(url="https://dig.chouti.com/",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
}) # print(chouti.text) print(chouti.cookies.get_dict())
# {'gpsd': 'ab141f7a741144216429b6e901da5f34', 'JSESSIONID': 'aaaNxWlWjLLKU9CGXDyNw'} # 将页面转换成一个BeautifulSoup的对象,就可以使用BeautifulSoup的方法了
soup = BeautifulSoup(chouti.text,"html.parser") news_list = soup.find_all(name="div",attrs={"class":"item"}) for news in news_list:
compont = news.find(name="div",attrs={"class":"part2"}) print(compont.get("share-title")) # 1、先查看首页
r1 = requests.get(url="https://dig.chouti.com/",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
}) # r1.cookies.get_dict(),第一次访问主页,服务端就给返回了一个cookies # 2、提交用户名和密码进行登陆 r2 = requests.post(url="https://dig.chouti.com/login",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
},
data={
"phone":"8613925293887",
"password":"admin123.",
"oneMonth":1
},
cookies=r1.cookies.get_dict()
) # 第二次登陆的时候把第一次返回的cookies带上,这个是抽屉这个网站的套路,同样这次登陆也会返回一个cookies,但是登陆这次返回的cookies其实是个迷惑我们的cookies,没有用
# print(r2.text)
# 登陆失败返回的信息:{"result":{"code":"21101", "message":"手机号或密码错误", "data":{}}}
# 登陆成功返回的信息:{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_53218132468"}}} # 如果登陆成功,通过下面的方法就可以把服务端返回的cookies拿到,以后在发请求,带着cookies去就可以了
print(r2.cookies.get_dict())
# {'puid': 'b11ec95d3b515ae2677a01f6abd5b916', 'gpid': '01cff9a184bd427789429d1dd556f4d2'} r3 = requests.post(url="https://dig.chouti.com/link/vote?linksId=25461201",
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
},
# cookies=r2.cookies.get_dict(),
cookies=r1.cookies.get_dict(),
# 破解抽屉coookies套路
)
# 这次点赞,我们同样带的cookies是第一次登陆主页返回的cookies,而不是登陆成功后返回的cookies
# print(r3.text)
三、爬github
github的登陆是form表单做的,所以我们在登陆github的时候需要把cookies和crsf_token都带上
1、访问github的首页
# 1、GET,访问登陆页面 r1 = requests.get(url="https://github.com/",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
}
)
# print(r1.cookies.get_dict())
2、访问登陆页面,需要在隐藏的input标签中找到token,然后获取到
r2 = requests.get(url="https://github.com/login",
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
}
) login_obj = BeautifulSoup(r2.text,"html.parser") token = login_obj.find(name="form",attrs={"action":"/session"}).find(name="input",attrs={"name":"authenticity_token"}).get("value")

3、post方式访问登陆页面,携带上用户名和密码,token和cookies
# 2、发送post请求,发送用户名和密码,发送的数据要不仅有用户名和密码,还要带上csrf token和cookie,浏览器发什么,我们就发什么
r3 = requests.post(url="https://github.com/session",
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
},
data={
"login":"admin",
"password":"admin",
"authenticity_token":token
},
cookies=r2.cookies.get_dict()
)
4、以后就可以携带r3这个请求访问的cookies进行登陆github后的操作了
obj = BeautifulSoup(r3.text,"html.parser")
# print(obj.find_all(name="img",attrs={"alt":"@admin"}))
# 3、发送get请求,访问这个路径:https://github.com/settings/profile
r4 = requests.get(url="https://github.com/settings/profile",
cookies=r3.cookies.get_dict()
)
print(r4.text)
爬github的所有的代码如下

四、爬拉钩网
最后我们来爬一下拉勾网
1、首先get方式访问拉勾网的首页
import requests
from bs4 import BeautifulSoup # 如果遇到登陆的密码被加密了有两种解决办法
# 1、获取他的加密方式,然后手动破解
# 2、直接抓包把加密后的数据发过去就可以了 # 1、访问登陆页面
l1 = requests.get(url="https://passport.lagou.com/login/login.html",
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
}) # print(l1.text)
2、登陆拉钩网,他的请求头稍微有点特殊
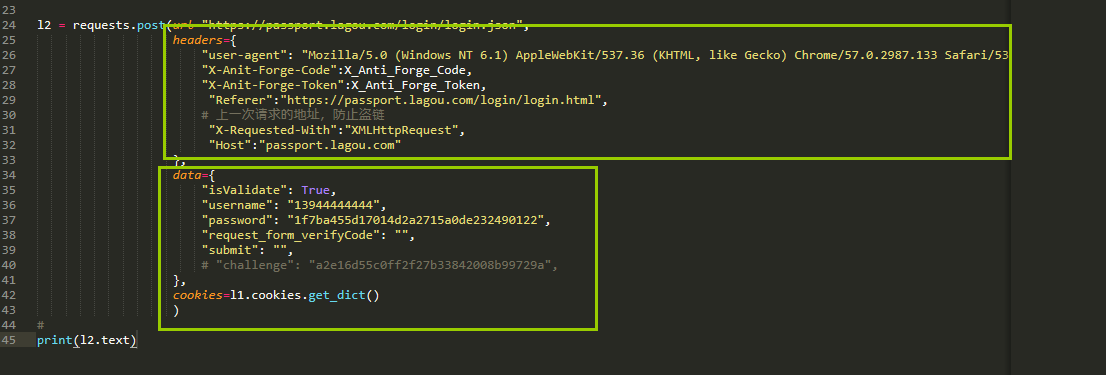
data很简单,我们直接抓包就可以拿到
主要是请求头中的数据是怎么来的,下面这2个是在我们请求登陆的页面中返回的,由于这2项在script标签中,我们只能通过正则表达式来匹配获取
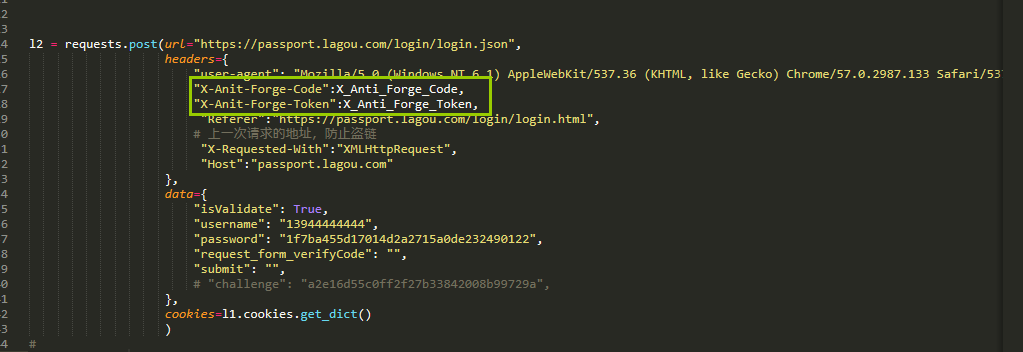
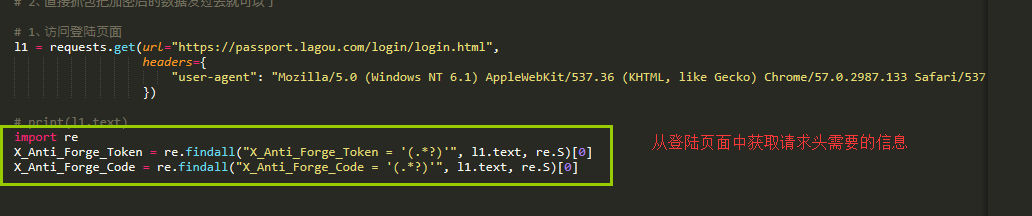

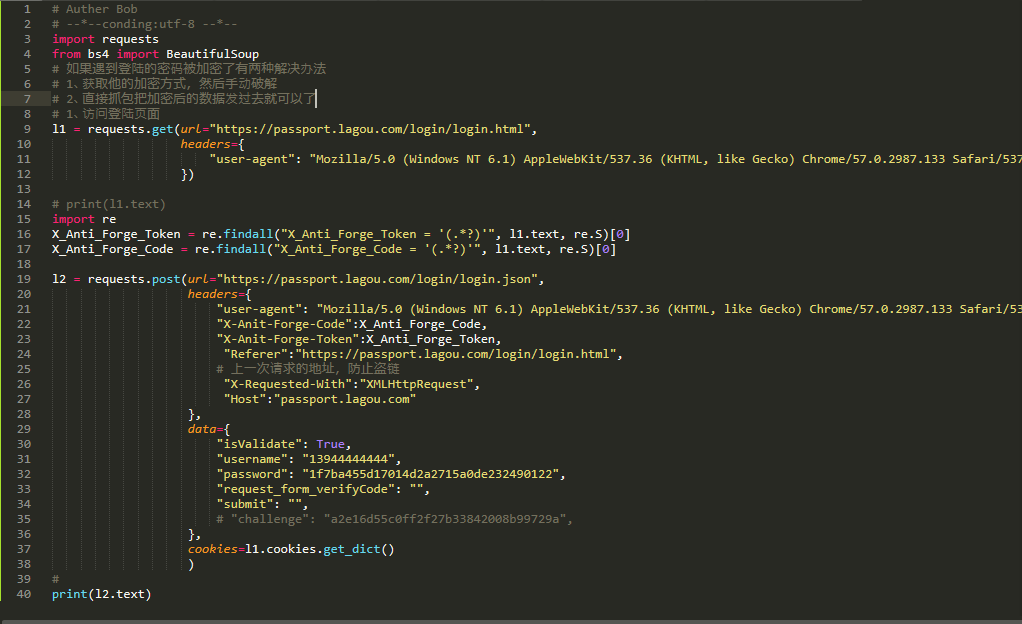
最后是爬拉勾网的所有的代码
python爬虫系列之初识爬虫的更多相关文章
- python爬虫之路——初识爬虫原理
爬虫主要做两件事 ①模拟计算机对服务器发起Request请求 ②接收服务器端的Response内容并解析,提取所需的信息 互联网页面错综复杂,一次请求不能获取全部信息.就需要设计爬虫的流程. 本书主要 ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- python 爬虫系列03--职位爬虫
职位爬虫 import requests from lxml import etree cookie = { 'Cookie':'user_trace_token=20181015184304-692 ...
- python爬虫之路——初识爬虫三大库,requests,lxml,beautiful.
三大库:requests,lxml,beautifulSoup. Request库作用:请求网站获取网页数据. get()的基本使用方法 #导入库 import requests #向网站发送请求,获 ...
- python 爬虫系列07-天气爬虫
看天气 import requests from bs4 import BeautifulSoup ALL_DATA = [] def parse_page(url): headers = { 'Us ...
- 爬虫系列(三) urllib的基本使用
一.urllib 简介 urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门 urllib 中包含四个模块,分别是 request:请求处理模 ...
- 爬虫系列(九) xpath的基本使用
一.xpath 简介 究竟什么是 xpath 呢?简单来说,xpath 就是一种在 XML 文档中查找信息的语言 而 XML 文档就是由一系列节点构成的树,例如,下面是一份简单的 XML 文档: &l ...
- 爬虫系列(五) re的基本使用
1.简介 究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括: 正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹 ...
- 爬虫系列(七) requests的基本使用
一.requests 简介 requests 是一个功能强大.简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装 下面我们将会介绍 requests 中常用 ...
随机推荐
- freemarker数据类型
基本数据类型: 字符串 数字 布尔值 日期/时间 (日期,时间或日期时间) 数据结构: 哈希表 序列 注意一点:freemarker里面并没有对象这一数据类型!!!. 在freemarker中对象仅仅 ...
- c#+CAD动态移动效果
public class MoveRotateScaleJig : DrawJig { public static List<Entity> entities = new List< ...
- 通过SQLServer的数据库邮件来发送邮件
前段时间需要做一个发送邮件的功能,于是就花了一点时间研究了一下.发现通过SQLServer就可以发送邮件,只需要配置一下就可以了,而且配置过程很简单.下面来说一下配置过程: 1.启用Database ...
- LinkedHashMap和TreeMap的有序性
做一个数组的多属性动态排序的功能,使用map时发现有序性问题. LinkedHashMap会存储数据的插入顺序,是进入时有序:TreeMap则是默认key升序,是进入后有序(hashMap .hash ...
- oracle数据库的权限系统
oracle数据库的权限系统分为系统权限与对象权限.系统权限( database system privilege )可以让用户执行特定的命令集.例如,create table权限允许用户创建表,gr ...
- request.getRealPath为什么会被代替
以及前两天在网上看到的“不是工程的物理路径封装在Session里 是工程的路径被封装在了ServletContext中的问题” 很抱歉没有找到答案. 只能怪鄙人才识短浅. 在通过这次学习的过程中使我懂 ...
- azkaban使用--schedule定时任务
1.schedule azkaban的schedule内部就是集成的quartz,而 quartz语法就是沿用linux crontab,crontab可照本文第2点 此处以此project(azka ...
- Delphi中Chrome Chromium、Cef3学习笔记(六)
原文 http://blog.csdn.net/xtfnpgy/article/details/71703317 一.CEF加载网页时空白 chrm1.Load(‘你的网址’); 出现空白,跟 ...
- 用phpstudy配置网站遇到的一些问题
第一次是配置在我本机,总是连不上数据库,后来查看到mysql.ini配置文件里面端口号有一个不是3306,更改之后就好了. 第二次是配置在笔记本电脑上,安装的时候比较顺利,也就遇到80端口被占用还有缺 ...
- dev: `webpack-dev-server --inline --progress --config build/webpack.dev.conf.js` vue启动报错解决
这是因为webpack-dev-server版本和vue版本不一样,需要将webpack-dev-server卸载了,安装对应版本 查看vue版本是 vue -V 注意:V是大写 卸载npm unin ...