python3+selenium入门04-元素定位
我们在对浏览界面做操作时,比如点击按钮,搜索框输入内容。都需要把鼠标挪过去,然后再点击,或者输入内容。在selenium操作时也是一样的。需要先对元素进行定位,然后才能进行操作。可以借助浏览器的开发者工具(浏览器F12打开)来查看网页对应的html代码。然后进行定位。可以稍微学习HTML基础,更容易理解。
定位方式有八种,这八种各有两个方法,一个是find_element_by_方式,这是定位单个元素的。一个是find_elements_by_方式,这是用来定位多个元素的。
使用name属性定位
打开谷歌浏览器,打开百度首页,F12呼出开发者工具
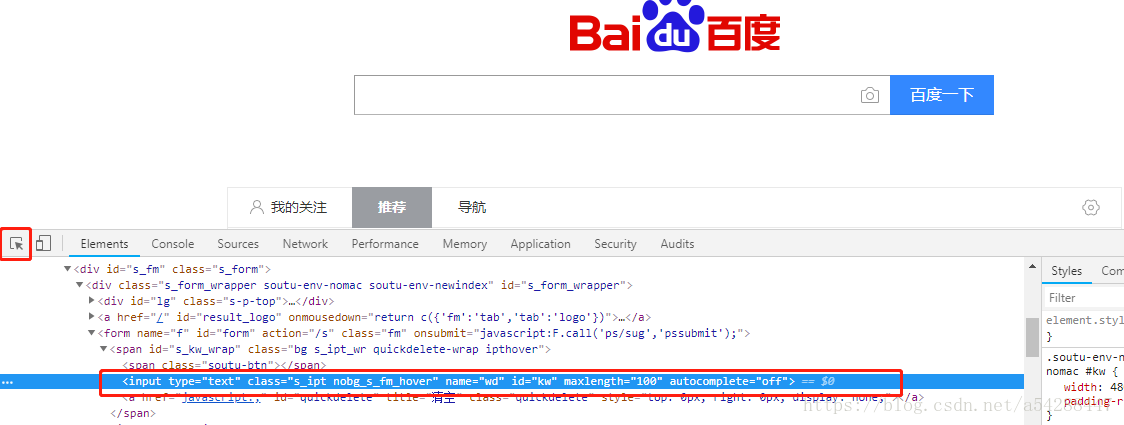
使用左边这个按钮,点击百度搜索框,会自动显示对应HTML代码,可以看到name=‘wd’
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_name('wd')#通过name属性定位输入框
test.send_keys('测试一下')#输入测试一下
使用id属性定位
还是以上面百度搜索框为例,id=‘kw’
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_id('kw')#通过id属性定位输入框
test.send_keys('测试一下')#输入测试一下
通过id和name是比较常用和容易的定位方式。因为一般id和name元素在一个HTML文件中基本是唯一的。不过有时候前端开发也可能不写这两个属性。
使用class定位
还是使用百度搜索框,class='s_ipt'
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_class_name('s_ipt')#通过classname属性定位输入框
test.send_keys('测试一下')#输入测试一下
使用tagname定位

tagname其实就是HTML的标签。不过一个HTML文件里面相同的标签肯定很多,一般很少用到。基本都是定位父元素,然后父元素定位下面所有tagname元素。再根绝其他条件去操作。比如表格啥的。
使用link_text定位
这是用来定位文字超链接的,可以通过文字链接部分的文字描述,定位百度首页上的新闻按钮

from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_link_text('新闻')#通过link_text定位新闻跳转按钮
test.click()#点击按钮
使用partial_link_text定位
这个也是用来定位文字超链接的,和link_text区别在于,这个相当于模糊搜索,只输入部分文字描述就可以了
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_partial_link_text('新')#通过partial_link_text定位新闻跳转按钮
test.click()#点击按钮
使用xpath定位
这个百分百可以定位到,通过层级来的,感兴趣可以学习下xpath的语法,不会也没关系。还是以百度搜索框为例

对着直接右键copy-copy xpath
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_xpath('//*[@id="kw"]')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下
使用css定位
和xpath一样,拷贝的时候选上面的copy-selector就行
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_css_selector('#kw')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下
python3+selenium入门04-元素定位的更多相关文章
- selenium+java二元素定位
页面元素定位是自动化中最重要的事情, selenium Webdriver 提供了很多种元素定位的方法. 测试人员应该熟练掌握各种定位方法. 使用最简单,最稳定的定位方法. 自动化测试步骤 定位元素 ...
- selenium自动化之元素定位方法
在使用selenium webdriver进行元素定位时,有8种基本元素定位方法(注意:并非只有8种,总共来说,有16种). 分别介绍如下: 1.name定位 (注意:必须确保name属性值在当前ht ...
- Python3-Selenium自动化测试框架(二)之selenium使用和元素定位
Selenium自动化测试框架(二)之selenium使用和元素定位 (一)selenium的简单使用 1.导包 from selenium import webdriver 2.初始化浏览器 # 驱 ...
- selenium webdriver python 元素定位
总结 定位查找时,返回查找到的第一个match的元素.如果找不到,则 raise NoSuchElementException 单个元素定位: find_element_by_idfind_e ...
- python3+selenium入门10-表单切换
当元素在ifarm或farm中时,需要先进入到表单中,然后才能定位元素进行操作.直接对元素定位.会提示元素无法找到. <!DOCTYPE html> <html> <he ...
- python3+selenium入门07-元素等待
在使用selenium进行操作时,有时候在定位元素时会报错.这可能是因为元素还没有来得及加载导致的.可以等过元素等待,等待元素出现.有强制等待,显式等待,隐式等待. 强制等待 就是之前文章中的time ...
- python3+selenium入门05-元素操作及常用方法
学习了元素定位之后,来看一些元素的操作,还有一些常用的方法 clear()清空输入框内容 click()点击 send_keys()键盘输入 import time from selenium imp ...
- Selenium之WebDriver元素定位方法
Selenium WebDriver 只是 Python 的一个第三方框架, 和 Djangoweb 开发框架属于一个性质. webdriver 提供了八种元素定位方法,python语言中也有对应的方 ...
- 【Selenium专题】元素定位之CssSelector
CssSelector是我最喜欢的元素定位方法,Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因是CSS locator比XPath loc ...
随机推荐
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- Bootstrap框架介绍
Bootstrap框架介绍 一.Bootstarp环境部署 1>.什么是Bootstartp框架 Bootstrap是Twitter开源的基于HTML.CSS.JavaScript的前端框架.它 ...
- curator操作zookeeper
使用zookeeper原生API实现一些复杂的东西比较麻烦.所以,出现了两款比较好的开源客户端,对zookeeper的原生API进行了包装:zkClient和curator.后者是Netflix出版的 ...
- 阿里RocketMq(TCP模式)
针对公司业务逻辑,向阿里云MQ发送指定数据,消费端根据数据来做具体的业务,分两个项目,一个生产端(Producer).一个消费端(Consumer) 生产端通过定时任务执行sql向阿里云MQ发送数据, ...
- Linux记录-安装LAMP和R环境
2.2 Apache httpd2.2.1 执行命令进行安装:yum install -y httpd2.2.2 开启服务:service httpd start2.2.3 设置开机自启动:chkco ...
- shop++之language
shop++商城改造此次感悟最深的就是封装.有些东西要整明白就得花点时间. 代码中经常用到这种,我照葫芦画瓢竟然没有用. 天啦,竟然是自己没有定义,还以为是什么高级自动的玩意呢? 文件结构如下: 后面 ...
- java中数组、集合、字符串之间的转换,以及用加强for循环遍历
java中数组.集合.字符串之间的转换,以及用加强for循环遍历: @Test public void testDemo5() { ArrayList<String> list = new ...
- ZooKeeper基础CRUD操作
==============================Curator Java 客户端 CRUD 使用==============================Curator 是 Apache ...
- spring注解第01课 @Configuration、@Bean
一.原始的 xml配置方式 1.Spring pom 依赖 <dependency> <groupId>org.springframework</groupId> ...
- ****** 二十八 ******、软设笔记【数据库】-分布式数据库、特点、数据存储、DBMS组成
分布式数据库 一.分布式数据库 分布式数据库由一组数据组成,这些数据物理上分布在计算机网络的不同结点(场地)上,逻辑上是属于同一个系统.每个结点可以执行局部应用,也能通过网络通信子 ...