Solr7.4的学习与使用
学习的原因:
17年的时候有学习使用过lucene和solr,但是后来也遗忘了,最近公司有个项目需要使用到全文检索,正好也顺便跟着学习一下,使用的版本是Solr7.4的,下载地址:http://archive.apache.org/dist/lucene/solr/7.4.0/
solr解压之后的目录结构:
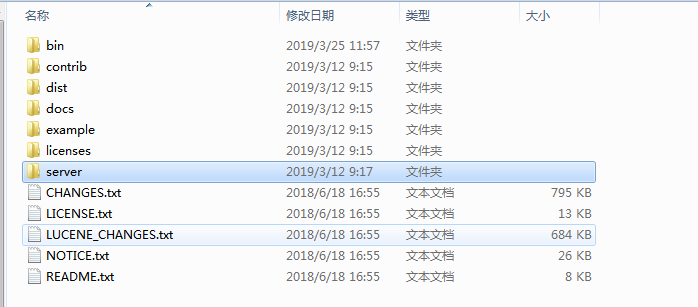
各文件夹里面的内容: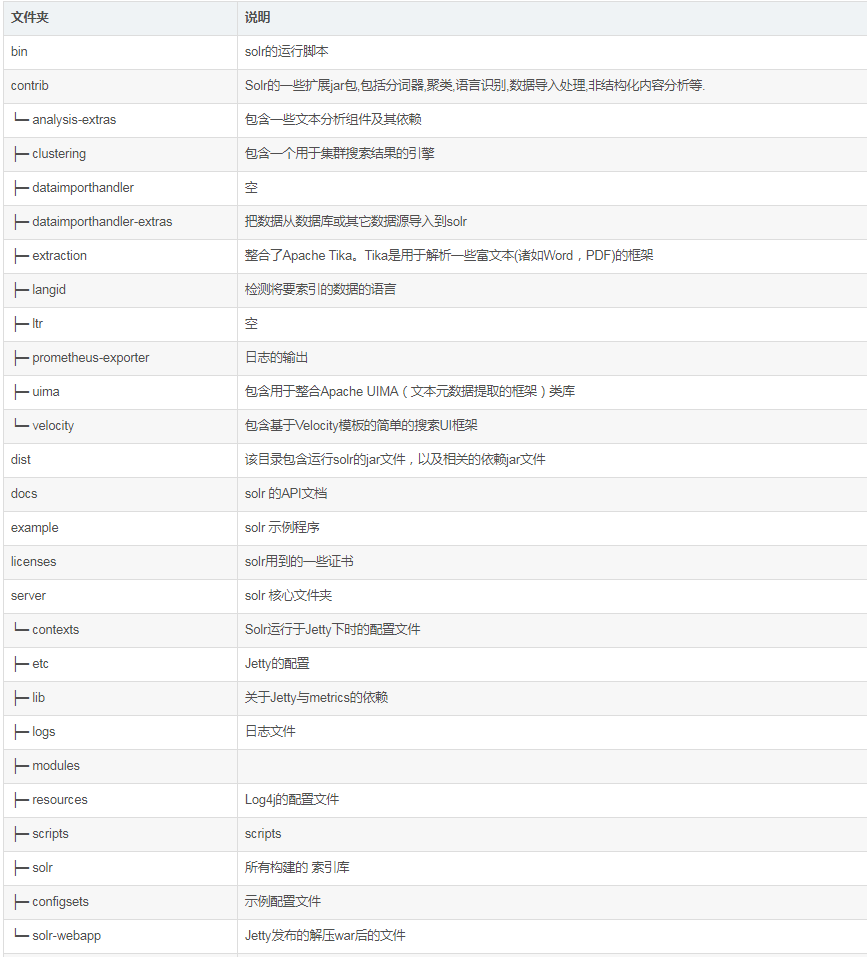
solr从5版本之后不再需要tomcat,使用内置的jetty启动。
下面开始正式开始学习使用Solr:
1、启动solr
因为现在solr使用的内置服务器,我们只需要通过命令启动就可以了。切换到bin目录。
shift+右键 ,出现黑窗口,输入solr start
,出现黑窗口,输入solr start


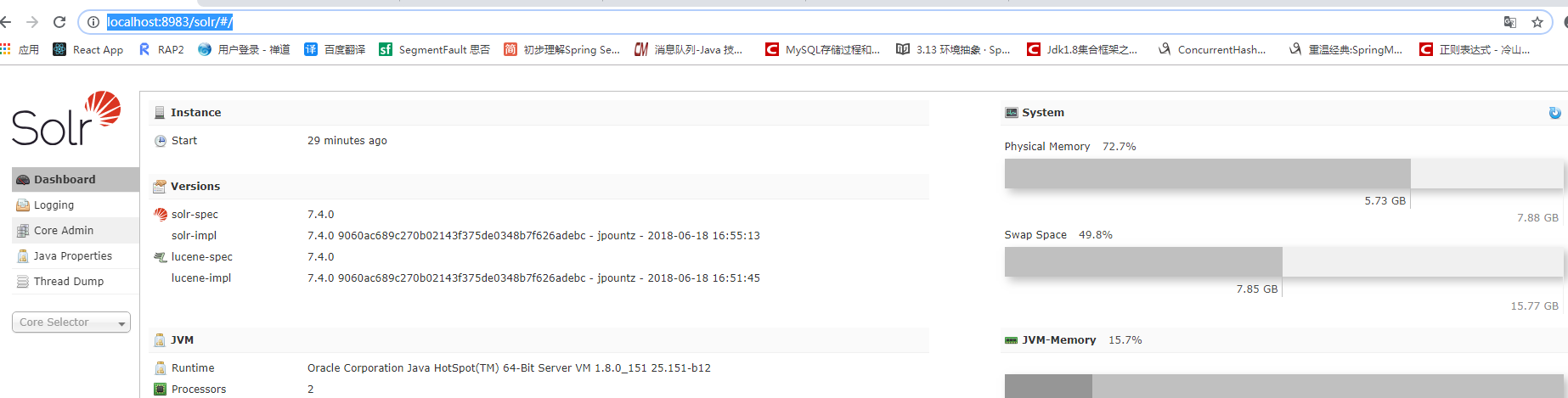
出现截图这样的就是启动成功了,中间有日志报错不用管他。访问:http://localhost:8983/solr/#/,就可以看到solrAdmin页面了
2、配置Solr核心(可以理解为solr的数据库)
配置core有两种方式一种是官方推荐的,一种是在admin页面创建
(1)通过Core Admin创建
。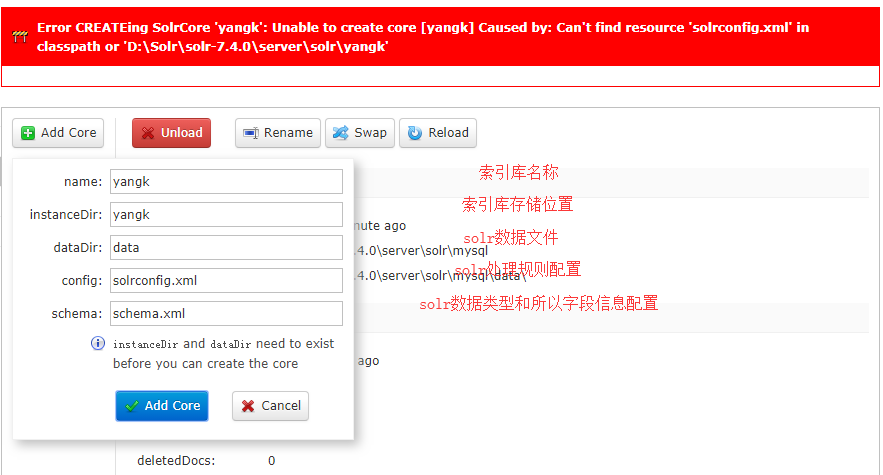
这样创建会报错。可以看到错误提示 无法找打solrconfig.xml文件。这里注意下:创建的instanceDir和dataDir 需存在,就是我们需在solr-7.4.0\server\solr 目录下先去创建目录
此目录下的conf文件我们可从server\solr\configsets\sample_techproducts_configs中复制
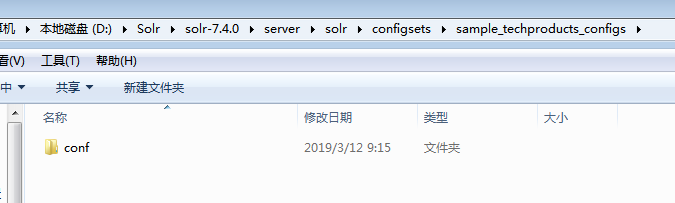
这样再去新增就可以了
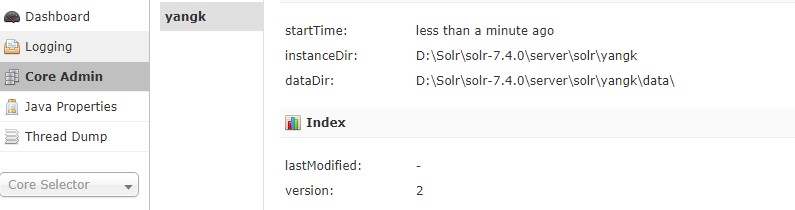
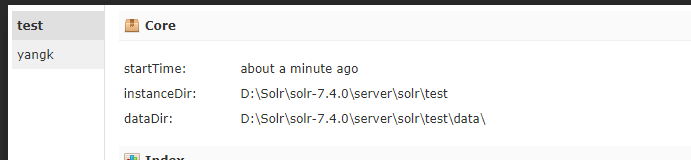
(2)官方推荐
使用命令 solr create -c test

3、配置IK分词器
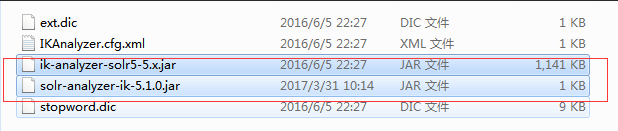
将标记的jar复制到\server\solr-webapp\webapp\WEB-INF\lib
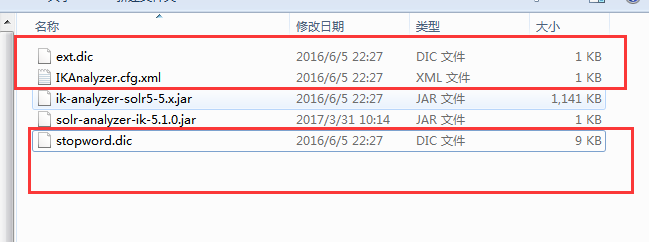
然后在server\solr-webapp\webapp\WEB-INF文件夹下面创建一个classes文件夹将上面标记的复制进去
找到刚刚创建的Core(yangk)下面的conf打开managed-schema添加如下代码:
<fieldType name="yangk_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" /></fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema
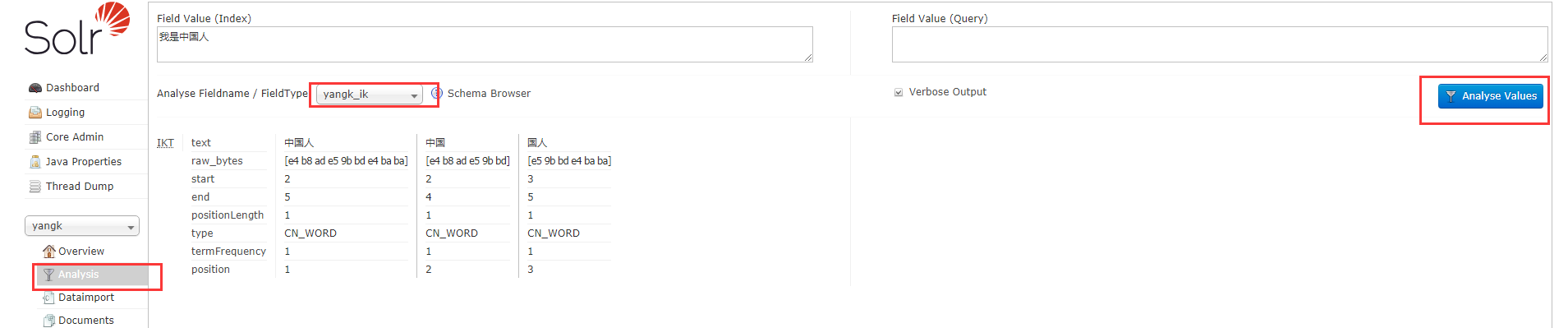
这里想要看到配置的分词器,需要重启下solr 命令:solr restart –p 端口号 重启solr服务
4、Solr整合Mysql
整合Mysql肯定需要Mysql的包,这里使用的是8.0的,将mysql的包放到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib下面

然后到solr-7.4.0\dist文件下下面找到

将这两个包也放到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib下面
为了区分,我从新创建一个croe取名mysql,然后找到solr-7.4.0\example\example-DIH\solr\db文件夹

将solr-7.4.0\example\example-DIH\solr\db文件里面的内容复制到mysql文件夹里面
进入conf里面找到db-data-config.xml修改配置文件,改为自己的数据库信息
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC" user="root" password="root" />
<document>
<entity name="item" query="select id,name from sys_area">
<field column="id" name="id" />
<field column="name" name="name" />
</entity>
</document>
</dataConfig>
DataSource:数据库连接信息 Entity:对应数据库的数据表 Field:数据库字段,对应于solr的schema.xml中的 field 字段。其中 column 表示数据库字段名,name 表示 field 的 name。
然后在找到solrconfig.xml配置requestHandler

然后找到managed-schema,配置分词器和索引字段

注意:field节点对应db-data-import.xml中的field节点 其中他们的name属性保持一致。如果查询想使用Ik的话,可以把type属性设置为mysql_ik类型。但是因为managed-schema已经存在了id和name的field,所以我配置的时候报错了。如果managed-schema已有的就不需要配置了。只要配置没有的字段就行了。
这个时候配置成功了就可以导入索引
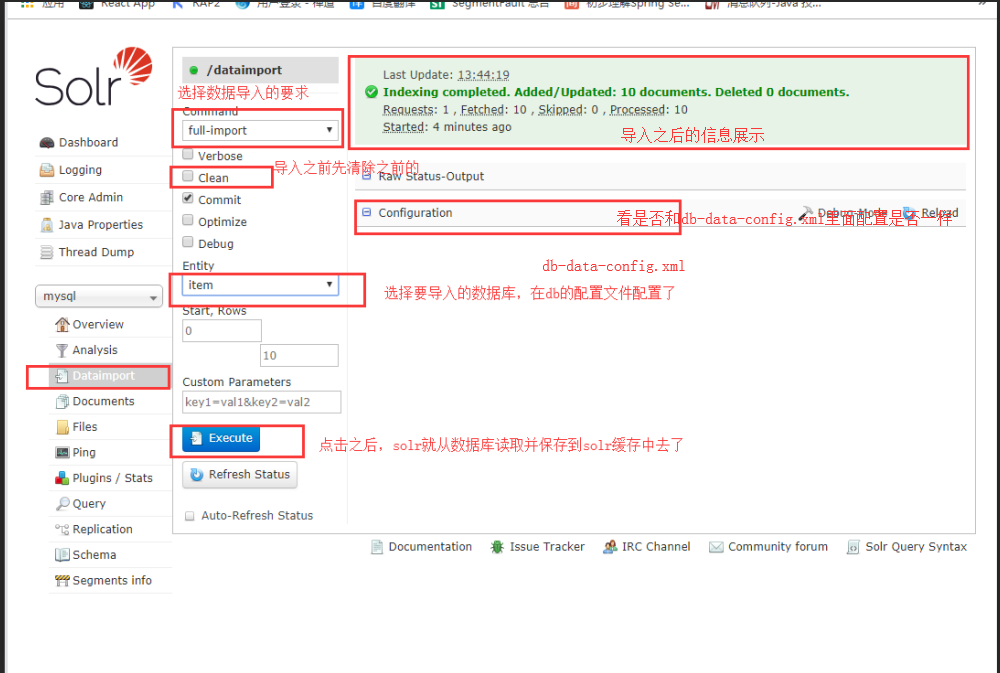
这个时候索引库就导入成功
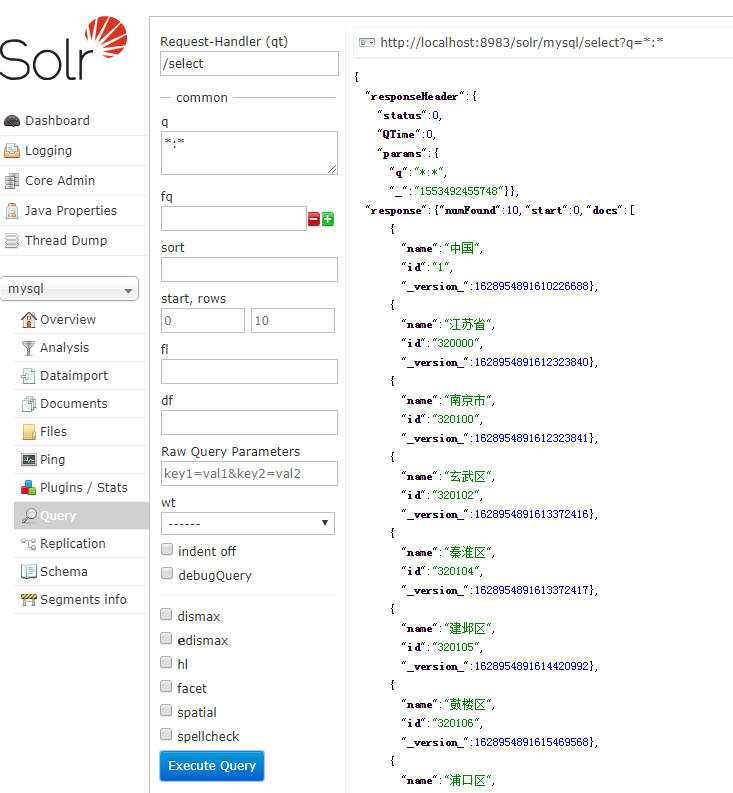
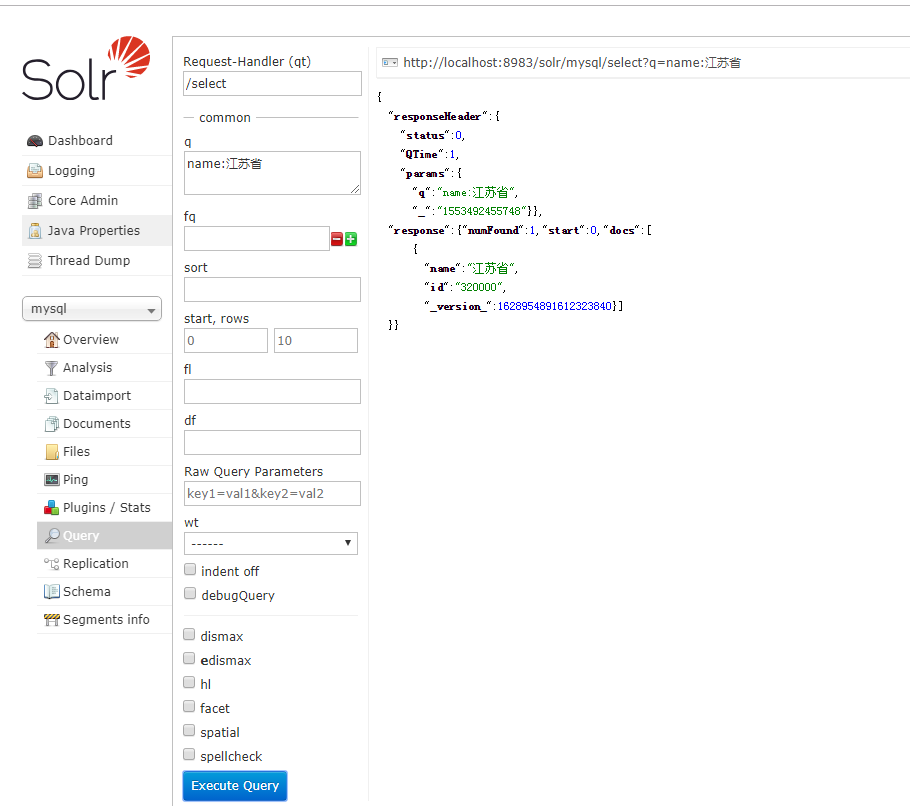
5、使用solrj
maven配置solrj的包
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
</dependency>
java代码
public class SolrjDrmo {
// 这个是solr索引库的连接地址
private static final String URL = "http://localhost:8983/solr/mysql";
public static void main(String[] args) throws SolrServerException, IOException {
// 创建solr客户端连接
HttpSolrClient hsc = new HttpSolrClient.Builder(URL).build();
// 创建查询对象
SolrQuery query = new SolrQuery();
query.setQuery("*:*");// 设置查询全部数据的条件
/* query.setQuery("name:江苏省"); */ // 列名:值
List<Map<String, Object>> list = getSolrQuery(hsc, query);
if (list == null) {
System.out.println("没有数据");
return ;
}
for (Map<String, Object> map : list) {
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
Object value = map.get(key);
System.out.println(key + "," + value);
}
System.out.println(" ");
}
}
public static List<Map<String, Object>> getSolrQuery(HttpSolrClient client, SolrQuery query)
throws SolrServerException, IOException {
List<Map<String, Object>> list = null;
// 执行查询并返回结果
QueryResponse resp = client.query(query);
SolrDocumentList results = resp.getResults();
// 获取查询到的数据总量
long numFound = results.getNumFound();
// 判断总量是否大于0,
) {
// 如果小于0,表示未查询到任何数据,返回null
return null;
} else {
// 如果大于0,表示有数据
// 创建list存储每条数据
list = new ArrayList<>();
// 遍历结果集
for (SolrDocument doc : results) {
// 得到每条数据的map集合
Map<String, Object> map = doc.getFieldValueMap();
// 添加到list
list.add(map);
}
// 返回list集合
return list;
}
}
}
IK分词器的下载地址:https://files.cnblogs.com/files/yangk1996/ikanalyzer-solr6.5.zip
至此一个简单的SolrDemo就搭建成功,如果中间有错误的地方,欢迎指正
Solr7.4的学习与使用的更多相关文章
- solr7.1.0学习笔记(10)---Solr发布到Tomcat
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/weixin_39082031/article/details/79069554 将solr作为一个单 ...
- JavaEE进阶——全文检索之Solr7.4服务器
I. Solr Solr简介 Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器. Solr比Lucene提供了更多的查询语句,而且它可扩展.可配置,同时它对L ...
- solr学习篇(三) solr7.4 连接MySQL数据库
目录 导入相关jar包 配置连接信息 将数据库导入到solr中 验证是否成功 创建一个Core,创建Core的方法之前已经很详细的讲解过了,如果还是不清楚请参考 solr7.4 安装配置篇: 1.导入 ...
- solr学习篇(一) solr7.4 安装配置篇
目录: solr简介 solr安装 创建core 1.solr简介 solr是企业级应用的全文检索项目,它是基于Apache Lucence搜索引擎开发出来的用于搜索的应用工程 运行环境:solr需要 ...
- Solr7.x学习(4)-导入数据
导入配置可参考官网:http://lucene.apache.org/solr/guide,http://lucene.apache.org/solr/guide/7_7/ 1.数据准备(MySQL8 ...
- Solr7.x学习(3)-创建core并使用分词器
1.创建core文件夹 ck /usr/local/solr-7.7.2/server/solr mkdir first_core cp -r configsets/_default/* first_ ...
- Solr7.x学习(2)-设置开机启动
1.创建solr用户 useradd solr 2.设置solr-7.7.2目录拥有者 cd /usr/local/ chown -R solr:solr solr-7.7.2 3.在/etc/ini ...
- Solr7.x学习(1)-安装
1.下载solr-7.7.2.tgz和jdk-8u221-linux-x64.tar.gz 2.将文件解压到/usr/local目录 cd /usr/local/ tar -zxvf jdk-8u22 ...
- Solr7.x学习(8)-使用spring-data-solr
1.maven配置 <dependency> <groupId>org.springframework.data</groupId> <artifactId& ...
随机推荐
- (K)ubuntu上将分区格式化成NTFS格式
新买了硬盘,装系统时,为Windows预留了几个分区,由于没有其他选择,因此将分区格式化成了fat32格式.装完系统后,总是很纠结,想把这些分区格式化成NTFS格式. google了一下,从这个网址( ...
- linux 一个网卡配置多个IP
在Redhat系列(redhat,Fedora,Centos,Gentoo)中的实现方法如下: 1.单网卡绑定多IP在Redhat系列中的实现方法 假设需要绑定多IP的网卡是eth0,请在/etc/s ...
- R学习笔记-安装R和RStudio,注意RStudio的版本需要与操作系统版本匹配
1.安装步骤:先安装R,再安装RStudio RStudio是R的集成开发工具,本身不带R环境. 2.从当前R的官网和RStudio下载的R和RStudio的版本分别为: A .For Windows ...
- JavaScript事件 DOMNodeInserted DOMNodeRemoved
JavaScript与HTML之间的交互是通过事件实现的.事件,就是文档或浏览器窗口中发生的一些特定交互的瞬间.可以使用侦听器(或处理程序)来预订事件,以便事件发生时执行相应的代码. 13.1 事件流 ...
- tp5中url使用js变量传参方法
window.location.href="{:url('Index/index')}>"+"/ID/"+ID; //这样可以生成,但url模式改变则不能 ...
- 检测Linux系统是否支持某系统调用
随内核版本的变化,会增加一些新的系统调用,但如果glibc没有跟上,则不能直接调用,这个时候可以自己包装一下.如果想知道内核是否支持某系统调用,先得知道它的系统调用ID号,下面代码即是用来检查是否支持 ...
- [Selenium With C#基础教程] Lesson-02 Web元素定位
作者:Surpassme 来源:http://www.jianshu.com/p/cfd4ed1daabd 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 使用Selenium ...
- tomcat mac
在mac上安装tomcat,教程很不错:http://blog.csdn.net/j2ee_me/article/details/7928493 注意 1.要下载二进制文件,core, 2.解压后移动 ...
- Android-自定义仿QQ列表Item滑动
效果图: 布局中去指定自定义FrameLayout: <!-- 自定义仿QQ列表Item滑动 --> <view.custom.shangguigucustomview.MyCust ...
- WIN7或2008远程连接特别慢的解决方法 【转】
方法一. 原因在于从vista开始,微软在TCP/IP协议栈里新加了一个叫做“Window Auto-Tuning”的功能.这个功能本身的目的是为了让操作系统根据网络的实时性能,(比如响应时间)来动态 ...