java程序控制KETTLE JOB的执行
有时候我们想在java程序中触发远程服务器上kettle job的执行,并且获得执行结果。kettle的carte提供了远程执行job和transfer的功能。
我使用的kettle是6.1版本,部署在linux服务器上,没有使用资源库。
下面介绍下各个步骤:为了方便以windows系统为例
1、开启carte服务,在kettle安装目录下,运行Carte.bat,直接上图
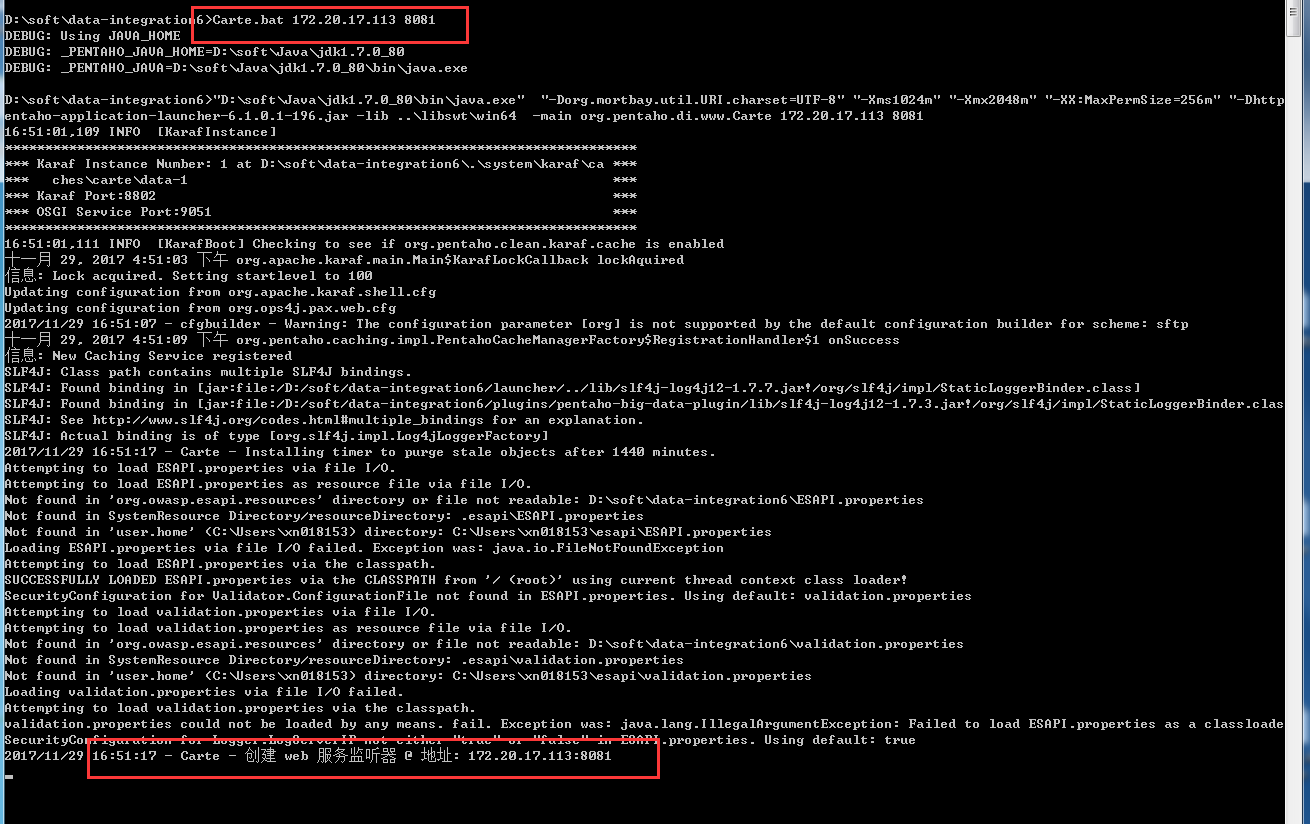
直接打Carte.bat后面不带任何参数就可以看到参数介绍,我这里在本机8081端口开启服务,看到最后的文字说明服务启动成功。
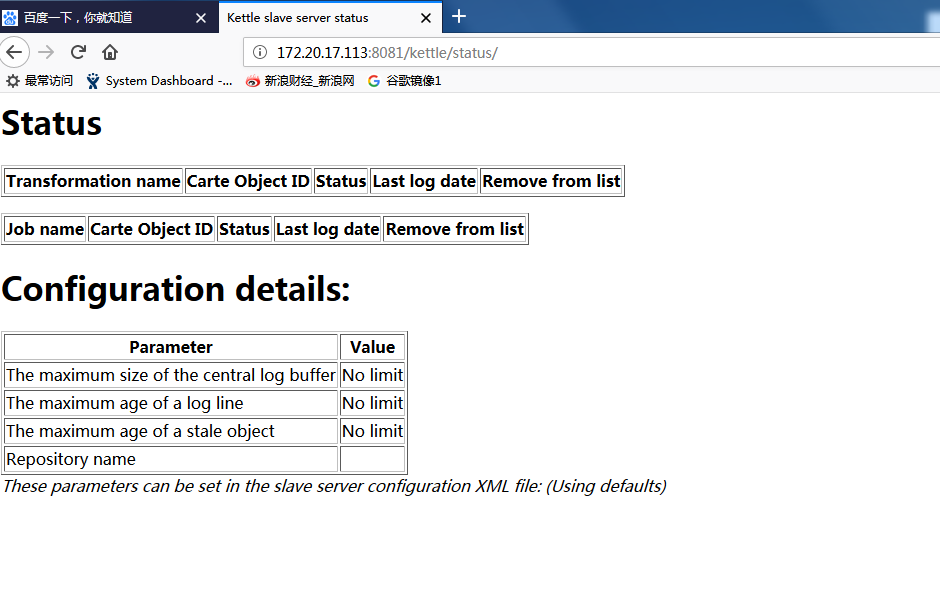
2、在浏览器中查看kettle 状态
在浏览器中输入http://172.20.17.113:8081,会提示输入密码,这里先直接输入cluster/cluster,然后可以进入,页面上会显示通过carte执行的job和transfer的状态。
那么这个用户名密码在哪设置呢?我找了半天,也是网上看前辈指引,原来是在kettle安装目录/pwd下面,大家可以看到有carte-config-8081到8084这些配置文件,还有carte-config-master-8080.xml,应该是做主从集群用的,先不管了。
打开carte-config-8081.xml就可以看到
<slaveserver>
<name>slave1-8081</name>
<hostname>localhost</hostname>
<port>8081</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver>
端口号跟用户名密码的默认配置都在这里了。
3、使用java触发JOB执行。
下面介绍真正要做的事情了,建立java project。把kettle安装目录/lib下面相关jar包依赖上去。需要的包挺多的,懒得话全部依赖吧。我这边依赖这些包就够了,因为用到了spring读取文件的工具,也依赖了spring的包。

代码逻辑如下:
package com.lzh.kettle; import org.pentaho.di.cluster.SlaveServer;
import org.pentaho.di.core.KettleEnvironment;
import org.pentaho.di.core.Result;
import org.pentaho.di.job.Job;
import org.pentaho.di.job.JobExecutionConfiguration;
import org.pentaho.di.job.JobMeta;
import org.pentaho.di.www.SlaveServerJobStatus;
import org.springframework.core.io.FileSystemResource; public class kettleRemoteDemo {
public static void main(String[] args) {
String jobPath = "E:\\ws0815\\xnol-reporting-app-trunk\\etl\\kettle\\jobs\\jb_current_account_order_latest5.kjb";
try {
KettleEnvironment.init(); SlaveServer remoteSlaveServer = new SlaveServer();
remoteSlaveServer.setHostname("172.20.17.113");// 设置远程IP
remoteSlaveServer.setPort("8081");// 端口
remoteSlaveServer.setUsername("cluster");
remoteSlaveServer.setPassword("cluster");
FileSystemResource r = new FileSystemResource(jobPath);
// jobname 是Job脚本的路径及名称
JobMeta jobMeta = new JobMeta(r.getInputStream(), null, null); JobExecutionConfiguration jobExecutionConfiguration = new JobExecutionConfiguration();
jobExecutionConfiguration.setRemoteServer(remoteSlaveServer);// 配置远程服务 String lastCarteObjectId = Job.sendToSlaveServer(jobMeta, jobExecutionConfiguration, null, null);
System.out.println("lastCarteObjectId=" + lastCarteObjectId);
SlaveServerJobStatus jobStatus = null;
do {
Thread.sleep(5000);
jobStatus = remoteSlaveServer.getJobStatus(jobMeta.getName(), lastCarteObjectId, 0);
} while (jobStatus != null && jobStatus.isRunning());
Result oneResult = new Result();
System.out.println(jobStatus);
if (jobStatus.getResult() != null) {
// 流程完成,得到结果
oneResult = jobStatus.getResult();
System.out.println("Result:" + oneResult);
} else {
System.out.println("取到空了");
}
} catch (Exception e1) {
e1.printStackTrace();
} }
}
这里因为job执行需要一些时间,我代码里面每隔5秒去拿一下结果,拿到结果确定job是否执行完成。
这时候如果我们去浏览器查看,可以看到job正在执行的状态。
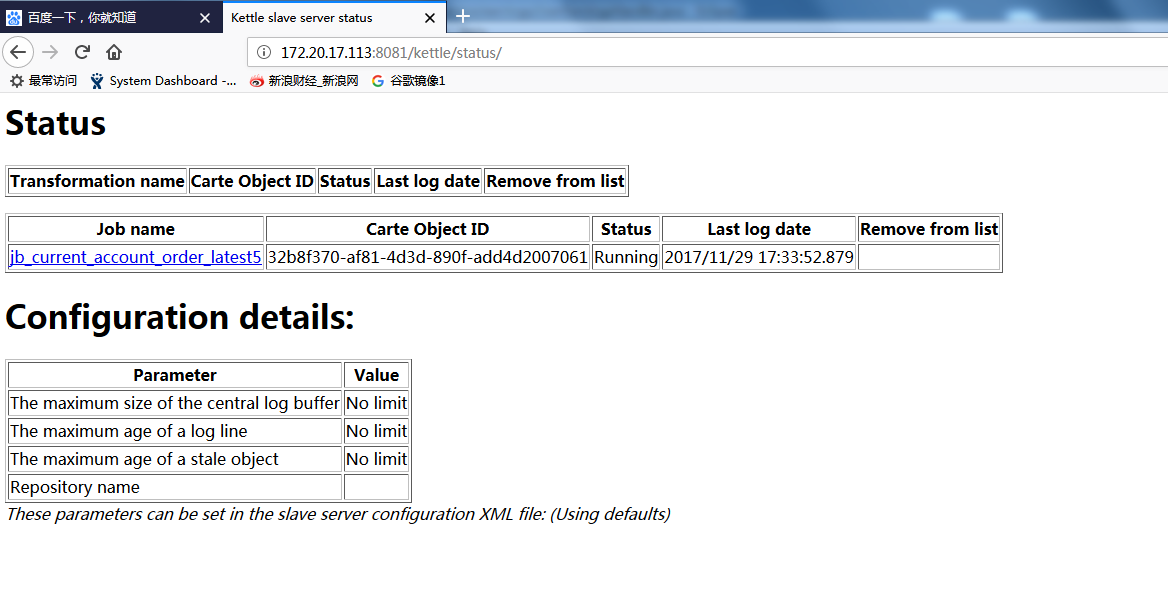
执行完成之后Running会变成Finish,如果有异常,status也会有提示。在命令行下面也会有job执行的日志信息。
大致过程就是这样,但是我研究的时候还是花了不少时间,网上资料不是很多,我这个算是完整介绍吧。
还有一个问题就是,我的job文件需要在本地保存一份,最开始我一直想的是我的job文件放到KETTLE所在服务器上,在代码中我指定指向job文件的路劲即可,但是运行的时候,kettle总是去本地路劲找文件然后找不到就报错。后来我想可能我的这种想法需要依赖kettle的资源库才能实现。而我没有使用资源库所以我必须在我java程序所在服务器放置job文件,然后去kettle所在远程服务器执行。
如果有朋友能解决我最后的疑虑,还望留言指点。谢谢!
java程序控制KETTLE JOB的执行的更多相关文章
- java调用kettle的job和transfer工具类
package com.woaiyitiaocai.util; import java.util.Map; import java.util.UUID; import org.apache.log4j ...
- 【Kettle】Java借助Kettle将Excel导入数据
示例功能(仅供测试): 在JAVA项目中,将数据从Excel文件导入数据库中.实现该能有多种方法,而本例则是“不走寻常路”,尝试借助Kettle实现数据导入. 原理: Java中调用存储在Kettle ...
- java中如何生成可执行的jar文件
java中如何生成可执行的jar文件 最简单的方法就是: jar -cfe Card.jar CardLayoutDemo CardLayoutDemo$1.class CardLayoutDemo$ ...
- "Java 反序列化"过程远程命令执行漏洞
一.漏洞描述 国外 FoxGlove 安全研究团队于2015年11月06日在其博客上公开了一篇关于常见 Java 应用如何利用反序列化操作进行远程命令执行的文章.原博文所提到的 Java 应用都使 ...
- 在CMD窗口中使用javac和java命令进行编译和执行带有包名的具有继承关系的类
一.背景 最近在使用记事本编写带有包名并且有继承关系的java代码并运行时发现出现了很多错误,经过努力一一被解决,今天我们来看一下会遇见哪些问题,并给出解决办法. 二.测试过程 1.父类代码 pack ...
- 在windows下使用cmd命令行对java文件进行编译和执行
windows下利用cmd命令行可以调用jdk里的javac.exe和java.exe对java文件进行编译和执行,前提是jdk已成功安装并正确配置相关环境变量 相关配置链接:java基础学习总结—— ...
- Java Swing jpanel paint方法执行两次的问题
Java Swing jpanel paint方法执行两次的问题: 在其他环境下执行了两次,自己测试怎么都是执行了一次,记录一下这个问题:需要后继工作: 可能是进行各种参数设置的时候导致了paint方 ...
- java之生成可重复执行的sql脚本
在实际项目开发过程中,sql脚本需要多次执行.而一般的DML和DDL语句一般只能执行一次,再次执行执行时就会报错(操作对应已存在/不存在),所以必须将sql脚本生成可重复执行的.本文共分为4部分:1. ...
- [学习笔记]java基础Java8SE开发环境搭建、第一个Java Hello World、Java程序的编译与执行
本文作者:sushengmiyan 本文地址:http://blog.csdn.net/sushengmiyan/article/details/25745945 内容简介: ------------ ...
随机推荐
- kue
尝试着看英文的文档,你发现他其实并不难. https://www.npmjs.com/package/kue
- [转载]SQL语句练习
.查询“生物”课程比“物理”课程成绩高的所有学生的学号: 思路: 获取所有有生物课程的人(学号,成绩) - 临时表 获取所有有物理课程的人(学号,成绩) - 临时表 根据[学号]连接两个临时表: 学号 ...
- Spring Boot 整合Swagger2构建API文档
1.pom.xml中引入依赖 <dependency> <groupId>io.springfox</groupId> <artifactId>spri ...
- 本田CB750型加速时发动机工作间歇
本田CB750型加速时发动机工作间歇 [故陣现象]近期以来,该车发动机工作无力,加速时发 动机工作不连续. [原因分析]起动发动机试验,发动机起动困难,怠速时 抖动严重,加速反应缓慢,工作间歇,声音沉 ...
- 论integer是地址传递还是值传递(转)
原文链接:http://blog.csdn.net/witsmakemen/article/details/46874717 论integer是地址传递还是值传递 Integer 作为传参的时候是地址 ...
- 浏览器的get请求和post请求的区别
GET 请求和 POST 请求: 1). 使用GET方式传递参数: ①. 在浏览器地址栏中输入某个URL地址或单击网页上的一个超链接时,浏览器发出的HTTP请求消息的请求方式为 ...
- Python流程控制-逻辑运算-if...else语句
摘录自:http://www.runoob.com/python/python-if-statement.html Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执 ...
- Centos 中扩展 软件源 的安装 之 Remi ( 为yum 扩展软件源 )
平时一般都是使用Ubuntu的,最近用起来Centos 发现软件安装方便不是很方便, 在安装过程中接触到了这么一个概念, 就是为yum 安装 扩展源, 这里下面要说的就是其中的 Remi ...
- vue图片上传组件
前言:很多项目中都需要用到图片上传功能,而其多处使用的要求,为了避免重复造轮子,让我决定花费一些时间去深入了解,最终封装了一个vue的图片上传组件.现将总结再次,希望有帮助. Layout <d ...
- 在C#中调用Java生成的jar包文件的方法
C#工程调用Java已生成的jar包步骤如下: 一.使用IKVM.NET组件 首先到IKVM官网(http://www.ikvm.net)下载组件,下载地址:https://sourceforge.n ...