Python开发【模块】:Urllib(一)
Urllib模块
1、模块说明:
Urllib库是Python中的一个功能强大、用于操作的URL,并在做爬虫的时候经常要用到的库。在Python2.X中,分Urllib库和Urllib库,Python3.X之后合并到Urllib库中,使用方法稍有不同,在此,本书中代码会以Python的新版,即Python3.X进行讲解,具体使用的是Python3.5.2。同时在本章中,我还会讲解如何处理异常等知识。
2、快速使用Urllib爬去网页:
导入对应的模块,读取网页内容
# 导入模块urllib
import urllib.request file = urllib.request.urlopen("http://www.baidu.com") # 打开网页
data = file.read() # 读取所有页面所有内容
dataline = file.readline() # 读取第一行
datalines = file.readlines() # 读取所有内容,列表形式存储,不推荐用此 # 存储文件
fhandle = open("baidu.html","wb") # 爬到的页面存储到本地
fhandle.write(data)
fhandle.close()
# 直接把网页存储到本地,适用于存储图片
urllib.request.urlretrieve(url="https://www.cnblogs.com/",filename="cnblogs.html")
urllib.request.urlcleanup() # urlretrieve执行后会产生一些缓存,清除 # 其他使用
print(file.info()) # 爬取页面的相关信息
print(file.getcode()) # 打印网页的状态码
print(file.geturl()) # 当前url # 200
# http://www.baidu.com
网页的编码和解码(中文字符要进行编码):
# 编码、解码
import urllib.request url_quote = urllib.request.quote("http://www.sina.com.cn")
print(url_quote)
# http%3A//www.sina.com.cn url_unquote = urllib.request.unquote(url_quote)
print(url_unquote)
# http://www.sina.com.cn
3、添加Headers属性:
# 添加报头
import urllib.request url = 'http://blog.csdn.net/weiwei_pig/article/details/51178226'
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
data = urllib.request.urlopen(req).read()
4、设置超时时间:
# 超时时间
import urllib.request
import logging for i in range(1,100):
try:
file = urllib.request.urlopen("http://www.baidu.com",timeout=1)
data = file.read()
print(len(data))
except Exception as e:
logging.error(e)
5、Post提交数据:
# post 提交
import urllib.request
import urllib.parse url = "http://www.iqianyue.com/mypost"
postdata = urllib.parse.urlencode({
"name":"ceo@iqianyue.com",
"pass":"aA123456"
}).encode("utf-8") # 转化成byte类型
req = urllib.request.Request(url,postdata)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
data = urllib.request.urlopen(req)
print(data.getcode())
# 200
6、代理服务器的设置:
有时候同一个IP去爬取同一个网站上的页面,久了之后就会被网站屏蔽,这时就需要代理服务器了,可以从http://www.xicidaili.com/网站上去找代理服务器地址:
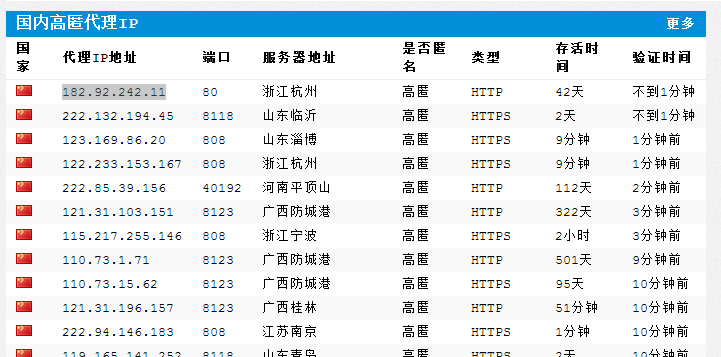
代码示例:
# 匿名代理
def urs_proxy(proxy_addr,url):
import urllib.request
proxy = urllib.request.ProxyHandler({'http':proxy_addr})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8')
return data proxy_addr = "182.92.242.11:80"
data = urs_proxy(proxy_addr,"https://www.cnblogs.com/")
print(len(data))
# 39244
7、异常处理URLError
# 异常处理
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://www.githup.com")
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
print(e)
# 403
# Forbidden
# HTTP Error 403: Forbidden
8、处理url
import urlparse #python2
base_url = "http://192.168.1.66:8088"
split = urlparse.urlsplit(base_url)
print(split)
# SplitResult(scheme='http', netloc='192.168.1.66:8088', path='', query='', fragment='')
Python开发【模块】:Urllib(一)的更多相关文章
- Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
- [转]Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
- python开发模块基础:re正则
一,re模块的用法 #findall #直接返回一个列表 #正常的正则表达式 #但是只会把分组里的显示出来#search #返回一个对象 .group()#match #返回一个对象 .group() ...
- python开发模块基础:异常处理&hashlib&logging&configparser
一,异常处理 # 异常处理代码 try: f = open('file', 'w') except ValueError: print('请输入一个数字') except Exception as e ...
- python开发模块基础:os&sys
一,os模块 os模块是与操作系统交互的一个接口 #!/usr/bin/env python #_*_coding:utf-8_*_ ''' os.walk() 显示目录下所有文件和子目录以元祖的形式 ...
- python开发模块基础:序列化模块json,pickle,shelve
一,为什么要序列化 # 将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化'''比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?现在我们能想到的方法就是存在文 ...
- python开发模块基础:time&random
一,time模块 和时间有关系的我们就要用到时间模块.在使用模块之前,应该首先导入这个模块 常用方法1.(线程)推迟指定的时间运行.单位为秒. time.sleep(1) #括号内为整数 2.获取当前 ...
- python开发模块基础:collections模块¶miko模块
一,collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdic ...
- python开发模块基础:正则表达式
一,正则表达式 1.字符组:[0-9][a-z][A-Z] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示字符分为很多类,比如数字.字母.标点等等.假如你现在要求一个位置&q ...
- Python开发——目录
Python基础 Python开发——解释器安装 Python开发——基础 Python开发——变量 Python开发——[选择]语句 Python开发——[循环]语句 Python开发——数据类型[ ...
随机推荐
- More is better-多多益善
思路:在图中所有的连通分量中找出包含顶点最多的个数.继续使用并查集解决! #include <iostream> using namespace std; ; int tree[MAX]; ...
- hadoop学习笔记之-hbase完全分布模式安装-5
http://blog.csdn.net/lichangzai/article/details/8441975 http://blog.csdn.net/jpiverson/article/detai ...
- MathType使用中的四个小技巧
MathType是一种比较常见的数学公式编辑器,常常与office搭配着使用,我们在使用的时候有一些要注意的小技巧,下面我们就来给大家介绍介绍MathType使用中的四个小技巧? 技巧一:调整工具栏显 ...
- c# T obj = default(T);
泛型类和泛型方法同时具备可重用性.类型安全和效率,这是非泛型类和非泛型方法无法具备的.泛型通常用在集合和在集合上运行的方法中..NET Framework 2.0 版类库提供一个新的命名空间 Syst ...
- C#------Entity Framework6的T4模板的使用
转载: http://www.cnblogs.com/Zhangzhigang/articles/4850549.html 1.新建一个.tt文件 2.打开.tt文件 3.粘贴入以下代码即可(inpu ...
- UIScrollView的用法,属性
iOS开发学习笔记-UIScrollView的用法 转载地址:http://www.jianshu.com/p/bcaf5cdfaa7e# UIScrollView是用来在屏幕上显示那些在有限区域内放 ...
- python2.0 s12 day7
开发的第二阶段 网络编程阶段 之所以叫网络编程,是因为,这里面就不是你在一台机器中玩了.多台机器,CS架构.即客户端和服务器端通过网络进行通信的编程了. 首先想实现网络的通信,你得先学网络通信的一个基 ...
- list的下标【python】
转自:http://www.cnblogs.com/dyllove98/archive/2013/07/20/3202785.html list的下表从零开始,和C语言挺类似的,但是增加了负下标的使用 ...
- HTML 解析
xml,json都有大量的库来解析,我们如何解析html呢? TFHpple是一个小型的封装,可以用来解析html,它是对libxml的封装,语法是xpath.今天我看到一个直接用libxml来解析h ...
- 《C++ Primer Plus》15.5 类型转换运算符 学习笔记
C++相对C更严格地限制允许的类型转换,并添加4个类型转换运算符,是转换过程更规范:* dynamic_cast:* const_cast:* static_cast:* reinterpret_ca ...