机器学习笔记(四)Logistic回归模型实现
一、Logistic回归实现
(一)特征值较少的情况
1. 实验数据
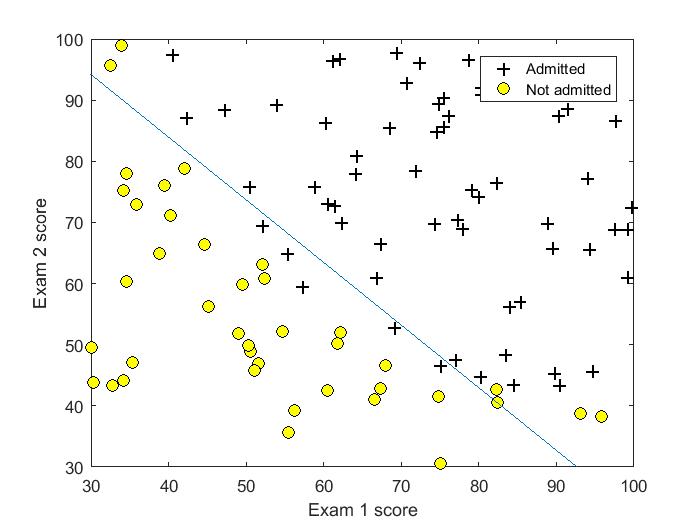
吴恩达《机器学习》第二课时作业提供数据1。判断一个学生能否被一个大学录取,给出的数据集为学生两门课的成绩和是否被录取,通过这些数据来预测一个学生能否被录取。
2. 分类结果评估
横纵轴(特征)为学生两门课成绩,可以在图中清晰地画出决策边界。
3. 代码实现
首先自己实现了梯度下降方法并测试
gradientDesent.m
%Logistic gradientDesent
function [Theta] = gradientDescentLog(X, y, Theta, alpha, counter)
[m,n] = size(X); % m样本数量 n特征数
H = zeros(m,1);
for iter = 1:counter
H = 1./(1 + exp(X * Theta));
Delta = (1/m) * X'*(H-y)
Theta = Theta + alpha * Delta;
Jtheta = (-1/m)*(y'*log(H)+(1-y)'*log(1-H))
end
接下来用课程中讲的高级优化方法,并实现costFunction函数。
%% Machine Learning Online Class - Exercise 2: Logistic Regression %
%% Initialization
clear ; close all; clc
%% Load Data
% The first two columns contains the exam scores and the third column
% contains the label.
data = load('ex2data1.txt');
X = data(:, [1, 2]);
y = data(:, 3);
%% ==================== Part 1: Plotting ====================
%We start the exercise by first plotting the data to understand the
% the problem we are working with.
fprintf(['Plotting data with + indicating (y = 1) examples and o ' ...
'indicating (y = 0) examples.\n']);
plotData(X, y);
xlabel('Exam 1 score')
ylabel('Exam 2 score')
legend('Admitted', 'Not admitted')
hold off;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% ============ Part 2: Compute Cost and Gradient ============
[m, n] = size(X);
% Add intercept term to x and X_test
X = [ones(m, 1) X];
% Initialize fitting parameters
initial_theta = zeros(n + 1, 1);
% Compute and display initial cost and gradient
[cost, grad] = costFunction(initial_theta, X, y);
fprintf('Cost at initial theta (zeros): %f\n', cost);
fprintf('Expected cost (approx): 0.693\n');
fprintf('Gradient at initial theta (zeros): \n');
fprintf(' %f \n', grad);
fprintf('Expected gradients (approx):\n -0.1000\n -12.0092\n -11.2628\n');
% Compute and display cost and gradient with non-zero theta
test_theta = [-24; 0.2; 0.2];
[cost, grad] = costFunction(test_theta, X, y);
fprintf('\nCost at test theta: %f\n', cost);
fprintf('Expected cost (approx): 0.218\n');
fprintf('Gradient at test theta: \n');
fprintf(' %f \n', grad);
fprintf('Expected gradients (approx):\n 0.043\n 2.566\n 2.647\n');
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% ============= Part 3: Optimizing using fminunc =============
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 40);
% Run fminunc to obtain the optimal theta
% This function will return theta and the cost
[theta, cost] = ...
fminunc(@(t)(costFunction(t, X, y)), initial_theta, options);
% Print theta to screen
fprintf('Cost at theta found by fminunc: %f\n', cost);
fprintf('Expected cost (approx): 0.203\n');
fprintf('theta: \n');
fprintf(' %f \n', theta);
fprintf('Expected theta (approx):\n');
fprintf(' -25.161\n 0.206\n 0.201\n');
% Plot Boundary
plotDecisionBoundary(theta, X, y);
% Put some labels hold on;
% Labels and Legend
xlabel('Exam 1 score')
ylabel('Exam 2 score')
% Specified in plot order
legend('Admitted', 'Not admitted')
hold off;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% ============== Part 4: Predict and Accuracies ==============
prob = sigmoid([1 45 85] * theta);
fprintf(['For a student with scores 45 and 85, we predict an admission ' ...
'probability of %f\n'], prob);
fprintf('Expected value: 0.775 +/- 0.002\n\n');
% Compute accuracy on our training set
p = predict(theta, X);
fprintf('Train Accuracy: %f\n', mean(double(p == y)) * 100);
fprintf('Expected accuracy (approx): 89.0\n');
fprintf('\n');
predict.m
function p = predict(theta, X)
%PREDICT Predict whether the label is or using learned logistic
m = size(X, );
% Number of training examples
p = sigmoid(X * theta)>=0.5;
end
sigmoid.m
function g = sigmoid(z)
%SIGMOID Compute sigmoid function
g = zeros(size(z));
g = 1./(1 + exp(-z));
end
costFunction.m
function [J, grad] = costFunction(theta, X, y)
%COSTFUNCTION Compute cost and gradient for logistic regression
m = length(y);
% number of training examples
J = 0;
grad = zeros(size(theta));
J = 1/m*(-y'*log(sigmoid(X*theta)) - (1-y)'*(log(1-sigmoid(X*theta))));
grad = 1/m * X'*(sigmoid(X*theta) - y);
end
plotData.m
function plotData(X, y)
pos = find(y == 1);
neg = find(y == 0);
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 1, ...
'MarkerSize', 7);
hold on;
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y', ...
'MarkerSize', 7);
plotDecisionBoundary.m(course provide)
function plotDecisionBoundary(theta, X, y)
%函数plotDate
plotData(X(:,:), y);
hold on
if size(X, ) <=
% Only need points to define a line, so choose two endpoints
plot_x = [min(X(:,))-, max(X(:,))+];
% Calculate the decision boundary line
plot_y = (-./theta()).*(theta().*plot_x + theta());
% Plot, and adjust axes for better viewing
plot(plot_x, plot_y)
% Legend, specific for the exercise
legend('Admitted', 'Not admitted', 'Decision Boundary')
axis([, , , ])
else
% Here is the grid range
u = linspace(-, 1.5, );
v = linspace(-, 1.5, );
z = zeros(length(u), length(v));
% Evaluate z = theta*x over the grid
for i = :length(u)
for j = :length(v)
z(i,j) = mapFeature(u(i), v(j))*theta;
end
end
z = z'; % important to transpose z before calling contour
% Plot z =
% Notice you need to specify the range [, ]
contour(u, v, z, [, ], 'LineWidth', ) %画等值线
end
hold off
end
输出结果:
For a student with scores and , we predict an admission probability of 0.771019
Expected value: 0.775 +/- 0.002 Train Accuracy: 89.000000
Expected accuracy (approx): 89.0
(二)特征值较多的情况
1. 实验数据
http://archive.ics.uci.edu/ml/index.php wine数据集,其特征取值是连续的。
2. 分类结果评估
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况:
实例是正类并且也被预测成正类,即为真正类(TP:True positive)
实例是负类被预测成正类,称之为假正类(FP:False positive)
实例是负类被预测成负类,称之为真负类(TN:True negative)
实例是正类被预测成负类则为假负类(FN:false negative)。
评价标准:
精确率:precision = TP / (TP + FP)模型判为正的所有样本中有多少是真正的正样本。
召回率:recall = TP / (TP + FN)
准确率:accuracy = (TP + TN) / (TP + FP + TN + FN)反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负
如何在precision和Recall中权衡?F1 Score = P*R/2(P+R),其中P和R分别为 precision 和 recall,在precision与recall都要求高的情况下,可以用F1 Score来衡量。
为什么会有这么多指标呢?这是因为模式分类和机器学习的需要。判断一个分类器对所用样本的分类能力或者在不同的应用场合时,需要有不同的指标。
3. 代码实现
%Logistic回归梯度下降法
%logistic梯度下降法
[Data] = xlsread('wine.xlsx',,'B1:N130');
[y] = xlsread('wine.xlsx',,'A1:A130');
[m,n] = size(Data); % m样本数量 n特征数
Data = featureScaling(Data);
for i = :m
if y(i)==
y(i) = ;
end
end
x0 = ones(m,); X = ([x0,Data])';
Theta = zeros(n+,);
alpha = 0.1;
counter = ;
H = gradientDescentLog(X, y, Theta, alpha, counter);
TP = ; TN = ; FP = ; FN = ;
for i = :m
if H(i)<0.5 %判断为negative
if y(i)==
TN = TN+;
else
FN = FN+;
end
else %判断为positive
if y(i)==
TP = TP+;
else
FP = FP+;
end
end
end
precision = TP / (TP + FP)
recall = TP / (TP + FN)
accuracy = (TP + TN) / (TP + FP + TN + FN)
%Logistic gradientDesent
function [H] = gradientDescentLog(X, y, Theta, alpha, counter)
[n,m] = size(X); % m样本数量 n特征数
H = zeros(m,1);
for iter = 1:counter
for i = 1:m
H(i) = 1/(1+exp(-Theta'*X(:,i))); %Logistic回归模型
end
Delta = 1/m * X * (H-y);
Theta = Theta - alpha * Delta;
Jtheta = -1/m*(y'*log(H)+(1-y)'*log(1-H))
end
输出结果:
Jtheta = 0.3497
precision = 0.8983
recall = 0.8983
accuracy = 0.9077
此时alpha = 0.1; counter = 4000;可见此时很可能已经出现过拟合现象,在下一篇笔记中我们针对这种过拟合现象进行讨论。
机器学习笔记(四)Logistic回归模型实现的更多相关文章
- 吴恩达机器学习笔记 —— 7 Logistic回归
http://www.cnblogs.com/xing901022/p/9332529.html 本章主要讲解了逻辑回归相关的问题,比如什么是分类?逻辑回归如何定义损失函数?逻辑回归如何求最优解?如何 ...
- 机器学习笔记(三)Logistic回归模型
Logistic回归模型 1. 模型简介: 线性回归往往并不能很好地解决分类问题,所以我们引出Logistic回归算法,算法的输出值或者说预测值一直介于0和1,虽然算法的名字有“回归”二字,但实际上L ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
- 机器学习实战读书笔记(五)Logistic回归
Logistic回归的一般过程 1.收集数据:采用任意方法收集 2.准备数据:由于需要进行距离计算,因此要求数据类型为数值型.另外,结构化数据格式则最佳 3.分析数据:采用任意方法对数据进行分析 4. ...
- 机器学习(4)之Logistic回归
机器学习(4)之Logistic回归 1. 算法推导 与之前学过的梯度下降等不同,Logistic回归是一类分类问题,而前者是回归问题.回归问题中,尝试预测的变量y是连续的变量,而在分类问题中,y是一 ...
- 机器学习之线性回归---logistic回归---softmax回归
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 可以取两个以上的值. Softmax回归模型对于诸如MNIST手写数字分类等问题 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- logistic回归模型
一.模型简介 线性回归默认因变量为连续变量,而实际分析中,有时候会遇到因变量为分类变量的情况,例如阴性阳性.性别.血型等.此时如果还使用前面介绍的线性回归模型进行拟合的话,会出现问题,以二分类变量为例 ...
- Softmax回归——logistic回归模型在多分类问题上的推广
Softmax回归 Contents [hide] 1 简介 2 代价函数 3 Softmax回归模型参数化的特点 4 权重衰减 5 Softmax回归与Logistic 回归的关系 6 Softma ...
随机推荐
- Git Learning3 Eclipse Tools(未完成)
1.创建Git 操作:工程 右键 Team Share Project Git 完成创建 2.全局设置:Window->Preference->Git->Configuration- ...
- Kotlin 类和对象
类定义 Kotlin 类可以包含:构造函数和初始化代码块.函数.属性.内部类.对象声明. Kotlin 中使用关键字 class 声明类,后面紧跟类名: class Runoob { // 类名为 R ...
- .Net Core文件上传
https://www.cnblogs.com/viter/p/10074766.html 1.内置了很多种绑定模型 缺少了一个FromFileAttribute 绑定模型 需要自己实现一个 pub ...
- CentOS7.5下安装、配置MySql数据库 --CentOS7.5
1.下载MySql的rpm包 [root@VM_39_157_centos -]# wget http://repo.mysql.com/mysql-community-release-el7-5.n ...
- Oracle解决ora-01653 无法通过1024扩展
综合上述检查结果,可断定遇到的问题是因为可能性1—表空间不足导致.解决办法也就是扩大表空间 扩大表空间的四种方法: 1.增加数据文件 ALTER TABLESPACE ***_TRD ADD DATA ...
- 在jsp中如何使用javax.servlet.http.HttpServlet,javax.servlet.GenericServlet, javax.servlet.Servlet
- var that = this 小坑记
在js编码过程中,经常会使用如上的语句来规避拿不到变量的问题. 比如: queryData:function () { var that=this; var param={}; for(var key ...
- java.lang.ClassCastException: android.widget.TextView cannot be cast to android.widget.EditText
Caused by: Java.lang.ClassCastException: Android.widget.TextView cannot be cast to android.widget.Ed ...
- Ubuntu16.04下安装sublime text3
通过ppa安装,打开终端,输入以下命令: sudo add-apt-repository ppa:webupd8team/sublime-text-3 sudo apt-get update sudo ...
- jjava:将jar包引入环境变量的一个骚操作以及因此搞出来的扑街问题
现在我有一个java文件,我只想javac启动,但是这货import了一堆jar里面的东西. 于是我下回了所有的jar包,将这些jar包丢到jdk1.8.0_162\jre\lib\ext里面就ok了 ...