(四)五种IO模型
基本概念
我们之前编写的套接字程序都是阻塞式的,其实这也是默认的形式。现在我们需要明确一些概念:
用户空间和内核空间
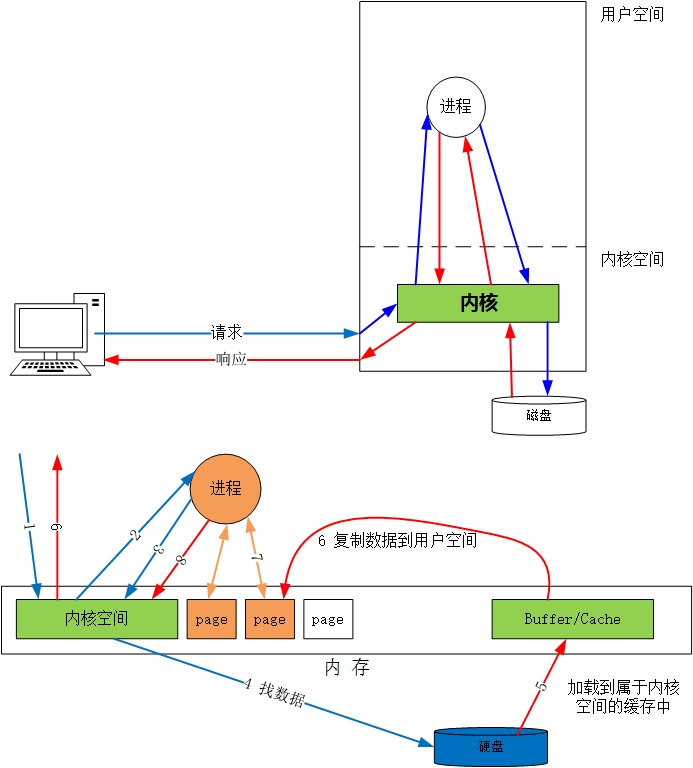
首先要明确,用户启动的应用程序在系统中以一个进程的形式存在,而无论对于网络数据还是磁盘数据通常来讲这个进程都无法直接访问,必须由内核把数据复制到用户空间也就是进程所在的内存空间里这个进程才可以访问。上图结合了网络请求和磁盘数据,用户发起一个HTTP请求,请求一个HTML页面,这个页面就在磁盘上,其实就是把这个HTML页面发送给用户,用户的浏览器解析HTML语言就显示了页面。用户请求一个页面其实就是阻塞的,浏览器必须等待所有数据返回后才能正确显示这个页面。所以这个请求的整个过程是阻塞的也是同步的,因为你无法让当前这个浏览器标签在等待服务器返回数据的时候去干别的。
其实对于我们之前写的程序也是一样,虽然服务器做的事情就是回显客户端发送的数据,其实客户端发送过来也是先进入服务器内核的TCP协议栈,而你的服务端程序运行在用户空间,内核需要把这个数据从内核空间复制到用户空间,然后服务器端程序才能拿到进而进行处理然后在进行发送,发送的过程其实就是接受的反向过程。
名词解释
阻塞:进程发起IO调用时,如果这个IO没有准备好数据那么进程调用的这个函数将不会返回,那么这个进程就要进入睡眠状态,也就是当前进程会被挂起。当数据拷贝到用户空间后才返回。
非阻塞:进程发起IO调用时,被调用函数在完成IO之前不会阻塞当前进程,而是立即返回,返回的含义你可以理解为数据还没准备好。虽然进程不阻塞,但是它需要频繁的调用之前的函数看看数据有没有准备好,所以这就是忙等,也叫轮训。
同步:进程发起一个过程调用(功能、函数)调用后,在没得到结果之前,该调用将不会返回。相当于你买麦当劳,你拿着小票在取餐处等着,如果你的餐没有做好那么服务员是不会给你端上来的。
异步:进程发起一个过程调用,即使不能立即得到结果,但也会得到返回值。当IO完成后,内核会通知进程资源已经准备好了,你可以来读取了。你可以理解为饭店点菜,点好了你可以干别的,菜好了服务员就给你端上来。
同步和阻塞、异步和非阻塞看起来概念上很像,但是他们所描述的对象不同,同步或异步是被调用者如何响应调用者,而阻塞或非阻塞是调用者如何被处理的。或者换句话说阻塞或非阻塞这种状态的描述对象是进程也就调用者被如何处理的,而同步或异步的这种处理方式所描述的对象是被调用者会如何响应调用者的。所以说的是同一个事情,但是描述的时候所站在的角度不同。
如果要把同步、异步、阻塞和非阻塞对应到后面要说的IO模型上的话,那么阻塞和非阻塞就是进程调用的系统函数是否立即返回无论数据准备好没有;同步和异步就是数据准备好后从内核空间拷贝到用户空间的过程中进程是否阻塞。
五种调用模型
阻塞式IO
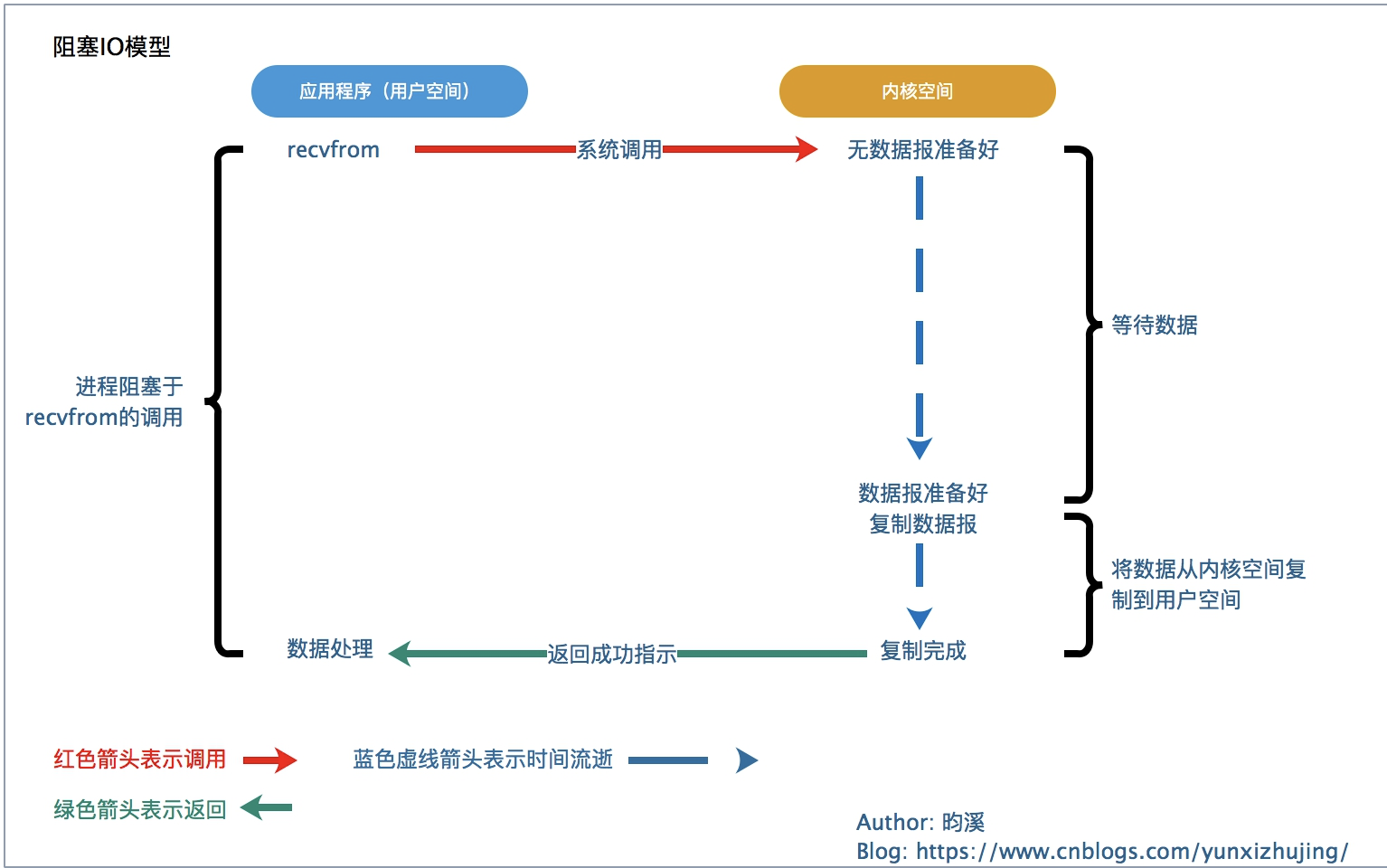
阻塞式IO也是我们之前一直使用的模式其实也是默认模式。一次系统调用分为2个阶段:
- 数据从磁盘到内核空间的缓冲区
- 内核把内核空间的数据复制到进程空间,然后删除内核空间数据
进程调用recvfrom就被阻塞,这时候就等数据,数据准备好了就从内核空间复制到用户空间,复制完成之后recvfrom函数才返回,这时候进程才开始对数据进行处理。在上面的图示数据准备好我们理解为数据可读,结合之前的例子就是我们的服务端程序阻塞在accept处,当有新连接进来之后连接套接字变为可读这时候就accept就返回了,看下图代码:
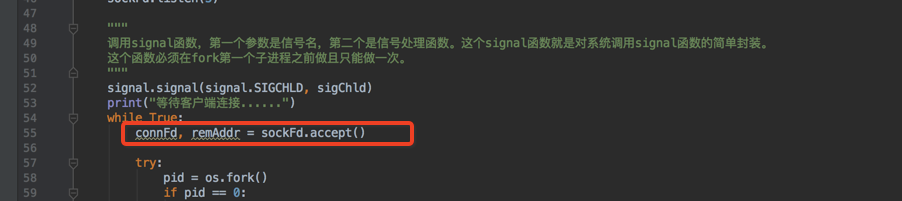
另外在接收客户端数据的时候服务端调用recv函数其实也是阻塞在这里,因为它要等着客户端发数据来,如下图:
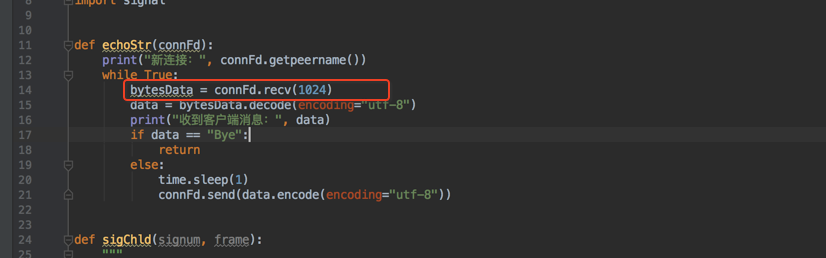
因为connFd代表一个与客户端的连接套接字,这个套接字可读证明有数据到达且被复制到进程的缓冲区(也就是用户空间),这时候这个函数才返回,否则就一直阻塞。
非阻塞式IO
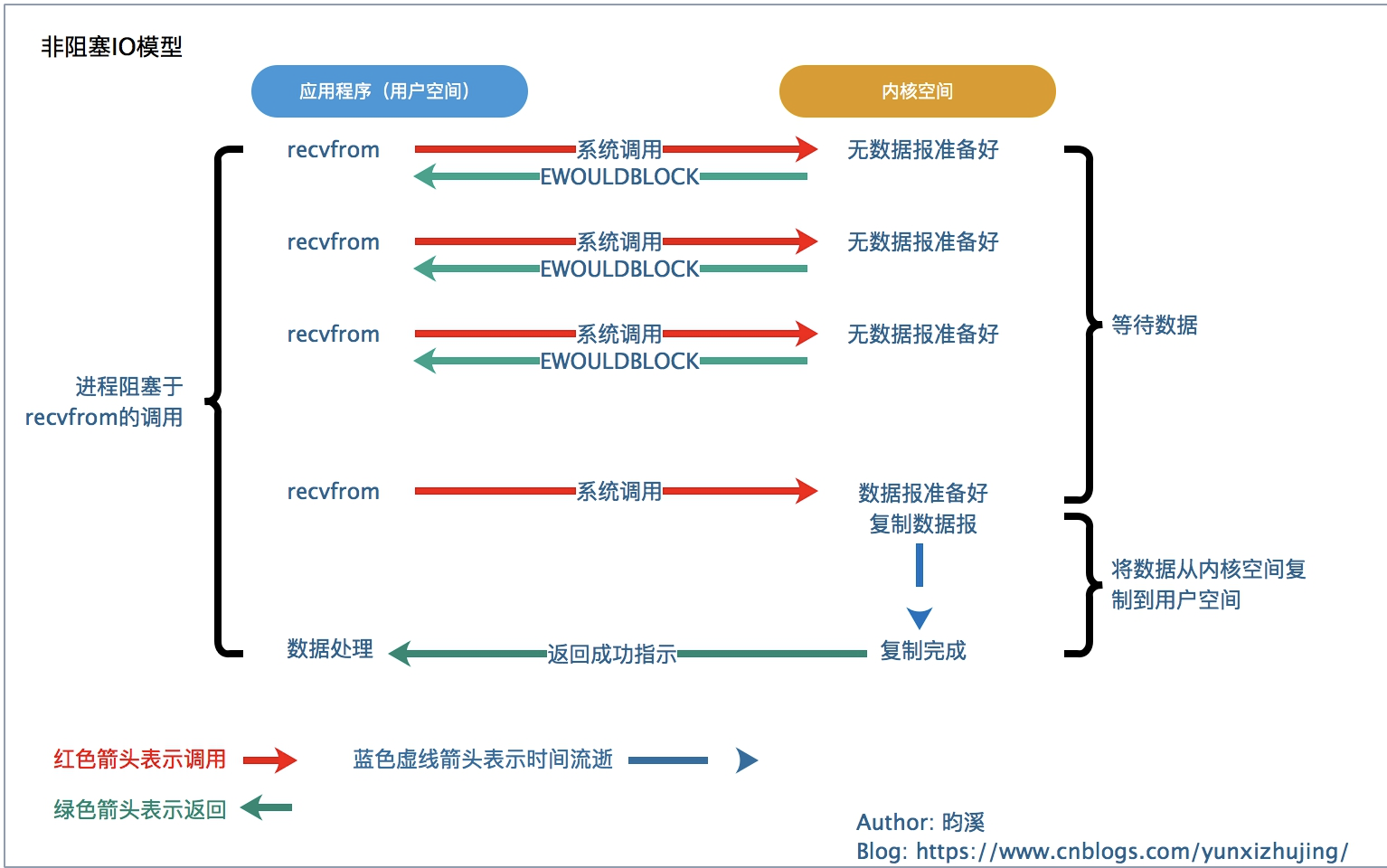
你明白了上面的阻塞式IO后再看这个非阻塞式的就很好理解,调用函数不阻塞立即返回,但是内核不会告诉你啥时候数据到达,你的反复调用,如果第N次调用刚好数据准备好,那么就阻塞了,这时候开始等待数据复制,复制完毕函数返回。这种方式会大量消耗CPU时间。
IO复用

在这种模型中,这时候并不是进程直接发起资源请求的系统调用去请求资源,进程不会被“全程阻塞”,进程是调用select或poll函数。进程不是被阻塞在真正IO上了,而是阻塞在select或者poll上了。Select或者poll帮助用户进程去轮询那些IO操作是否完成。
不过你可以看到之前都只使用一个系统调用,在IO复用中反而是用了两个系统调用,但是使用IO复用你就可以等待多个描述符也就是通过单进程单线程实现并发处理,同时还可以兼顾处理套接字描述符和其他描述符。
信号驱动模型
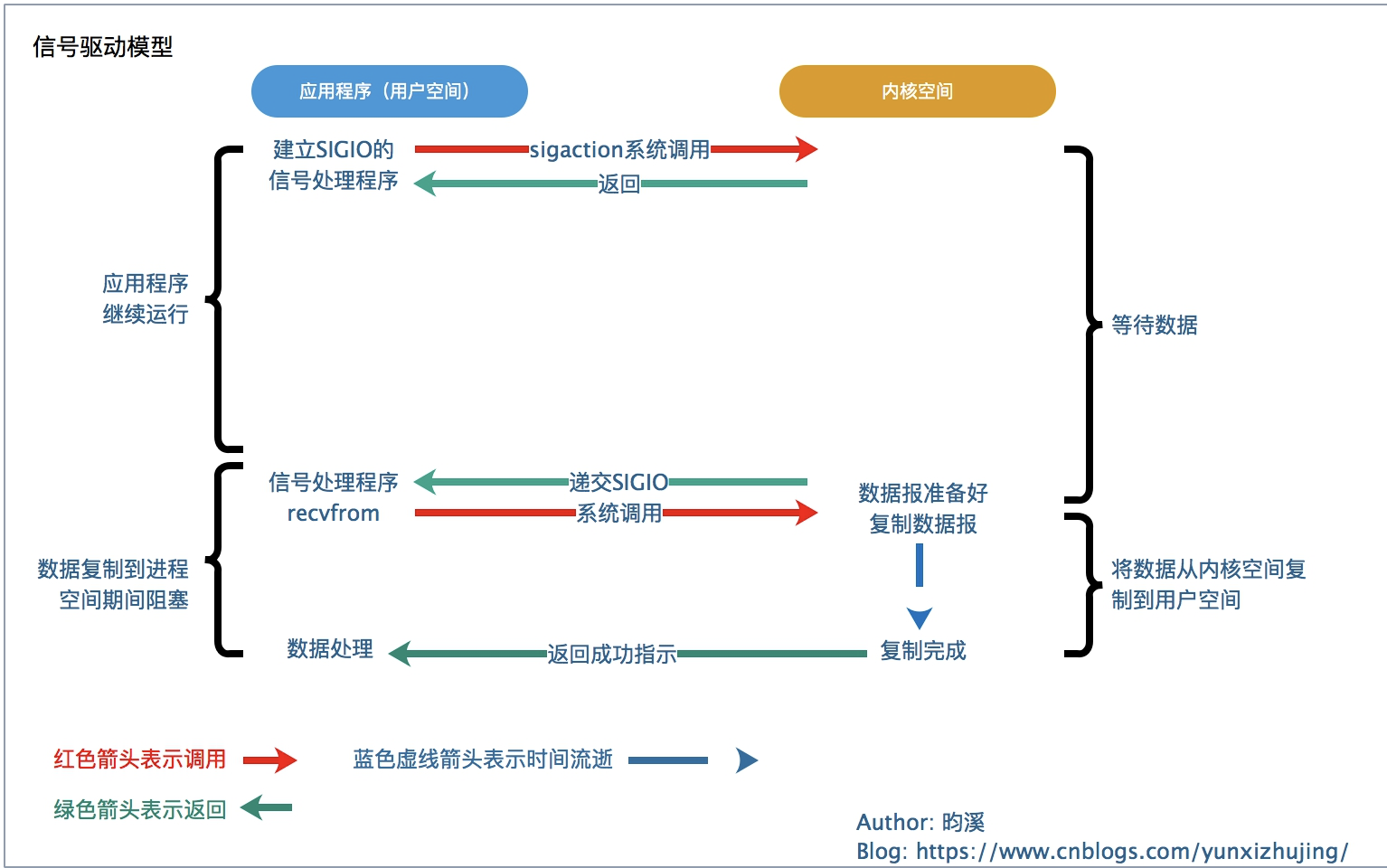
让内核在文件描述符就绪时通过信号通知进程。从上图可以看出这种模型进程建立信号处理程序然后立即返回,当数据准备好后发送信号通知进程,然后进程调用recvfrom系统调用进行复制数据,当数据复制到用户空间后函数返回(信号驱动机制需要内核支持)。这就相当于是你点菜下单后可以继续干其他的事情虽然菜好了会通知你,但是你需要自己去拿。但这里有个情况,如果通知进程来拿数据,但是进程没来怎么办?这就引出了水平触发和边缘触发概念
边缘触发(Edge triggered):以epoll为例,当被监控的文件描述符上有可读写事件时,被调用者(epoll_wait())通知进程去读写,如果一次没有把全部数据读写完毕比如读写缓冲区太小,那么下次调用epoll_wait()时被调用者它不会通知进程,它只通知一次,直到该文件描述符上出现第二次可读写事件才会通知。信号驱动IO是边缘触发模型,epoll()支持水平也支持边缘,默认是水平触发。
水平触发(Level triggered):以epoll为例,当被监控的文件描述符上有可读写事件时,被调用者(epoll_wait())通知进程去读写,如果一次没有把全部数据读写完毕比如读写缓冲区太小,那么下次调用epoll_wait()时,它还会通知进程在上次没有读写完的文件描述符上继续读写,当然如果你一直不读写,它会一直通知。如果系统中有大量你需要读写的文件描述符,而且它每次都返回,这会大大降低程序检查自己关心的文件描述符的效率,相比之下边缘触发效率更高。Select()和poll()都是水平触发的。
异步IO模型
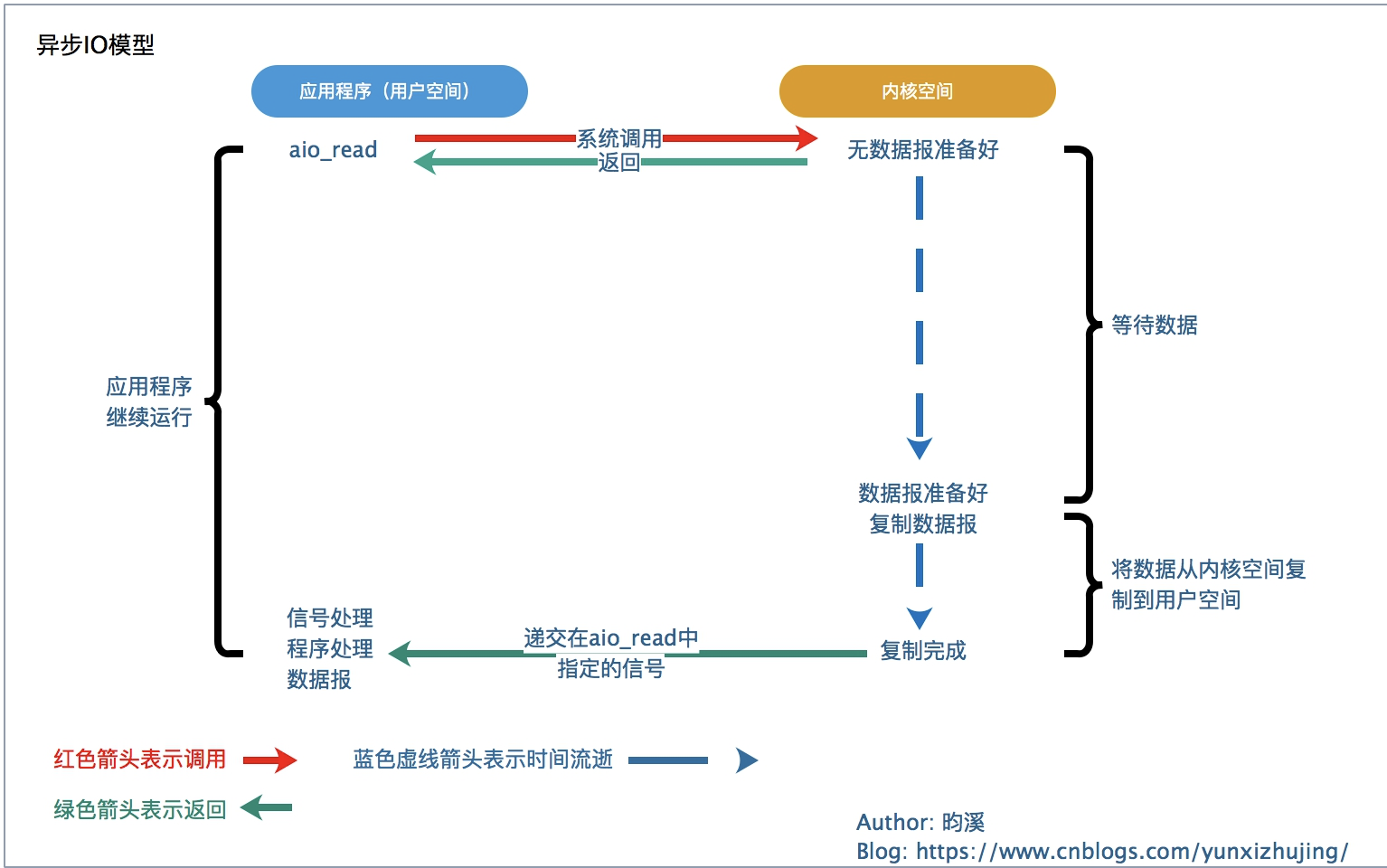
这种模型可以看出全程无阻塞,就等于你点菜下单后你可以续干其他的事情,菜做好了服务员会给你端上来,剩下的就是你如何处理这些菜。从效率上来讲异步IO模型是最高的。
5种IO模型比较
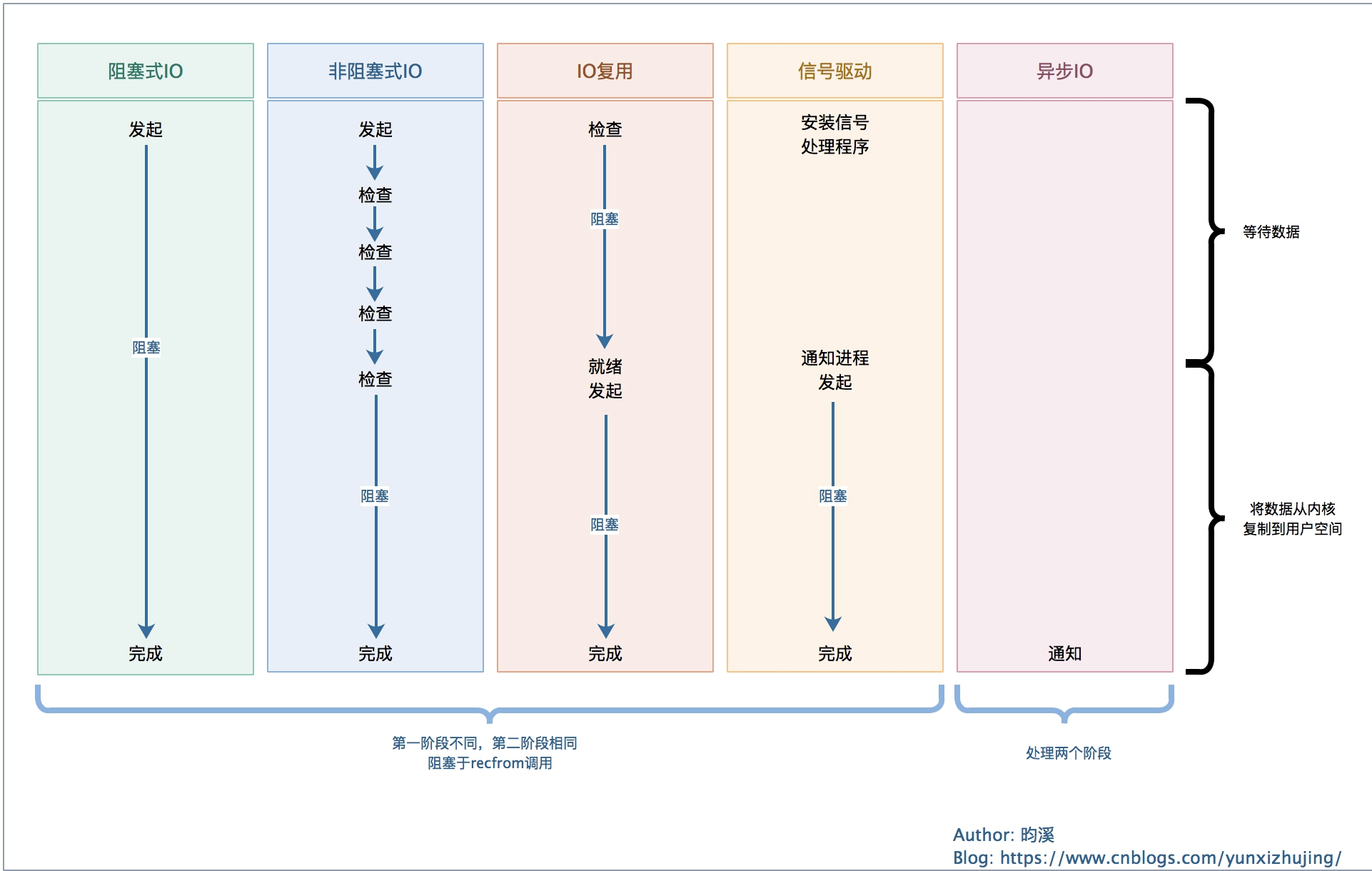
从上图可以效率从左至右逐步提高,其实IO复用也不是不阻塞,只是阻塞在像select这种IO复用函数这里。
(四)五种IO模型的更多相关文章
- Atitit 五种IO模型attilax总结 blocking和non-blocking synchronous IO和asynchronous I
Atitit 五种IO模型attilax总结 blocking和non-blocking synchronous IO和asynchronous I 1.1. .3 进程的阻塞1 1.2. 网络 ...
- 聊聊 Linux 中的五种 IO 模型
本文转载自: http://mp.weixin.qq.com/s?__biz=MzAxODI5ODMwOA==&mid=2666538919&idx=1&sn=6013c451 ...
- Linux 下的五种 IO 模型
概念说明 用户空间与内核空间 现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方).操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的 ...
- [转载] Linux五种IO模型
转载:http://blog.csdn.net/jay900323/article/details/18141217 Linux五种IO模型性能分析 目录(?)[-] 概念理解 Lin ...
- 2018.5.4 Unix的五种IO模型
阻塞非阻塞和异步同步 同步和异步关注的是消息通信机制,关注两个对象之间的调用关系. 阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态,关注单一程序. Unix的五种IO模型 以下基于Li ...
- Linux五种IO模型(同步 阻塞概念)
Linux五种IO模型 同步和异步 这两个概念与消息的通知机制有关. 同步 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回.比如,调用readfrom系统调用时,必须等待IO操 ...
- Windows五种IO模型性能分析和Linux五种IO模型性能分析
Windows五种IO模型性能分析和Linux五种IO模型性能分析 http://blog.csdn.net/jay900323/article/details/18141217 http://blo ...
- (转载) Linux五种IO模型
转载:http://blog.csdn.net/jay900323/article/details/18141217 Linux五种IO模型及分析 目录(?)[-] 概念理解 Linux下 ...
- 漫谈五种IO模型(主讲IO多路复用)
首先引用levin的回答让我们理清楚五种IO模型 1.阻塞I/O模型 老李去火车站买票,排队三天买到一张退票. 耗费:在车站吃喝拉撒睡 3天,其他事一件没干. 2.非阻塞I/O模型 老李去火车站买票, ...
- 漫谈五种IO模型
阅读目录 1 基础知识回顾 2 I/O模式 3 事件驱动编程模型 网络编程里常听到阻塞IO.非阻塞IO.同步IO.异步IO等概念,搞清楚这些概念之前,还得先回顾一些基础的概念. 1 基础知识回顾 注意 ...
随机推荐
- 八、OpenStack—Cinder组件安装
一.安装和配置控制器节点 1.先决条件 1)创建数据库 # mysql -u root -p 2)创建cinder数据库 MariaDB [(none)]> CREATE DATABASE ci ...
- Adams 2013自定义插件方法zz
1.Adams插件介绍 Adams的高级模块(如Controls控制模块.Vibration振动模块.Durability耐久性模块等)是以插件的形式集成在Adams软件中.通过Adams提供的插件管 ...
- wsl 子系统 用户目录位置
C:\Users\DELL\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu18.04onWindows_79rhkp1fndgsc\LocalS ...
- Cause: java. lang.InstantiationException: tk.mybatis.mapper.provider.base.BaseInsertProvider
相信现在Java Web开发都是用的mybatis吧,而用到mybatis很多人都不会错过通用mapper吧! (纯属瞎扯淡...qwq). 如我上一篇博客所写,目前公司新项目,使用了通用mapper ...
- 在虚拟机中安装Centos系统
1.首先下载VMware 2.然后可以去http://mirrors.aliyun.com下载映像ISO 3.打开VM,点击创建新的虚拟机 4.选择典型模式 5.稍后安装操作系统 6.选择你所要安装的 ...
- java拦截处理System.exit(0)
在使用TestNG做单元测试时,需要测试的代码中出现System.exit(0),导致单元测试还未结束程序就停止了.解决方法如下: public class TestMain { public sta ...
- 2017 ES GZ Meetup分享:Data Warehouse with ElasticSearch in Datastory
以下是我在2017 ES 广州 meetup的分享 ppt:https://elasticsearch.cn/slides/11#page=22 摘要 ES最多使用的场景是搜索和日志分析,然而ES强大 ...
- for循环:用turtle画一颗五角星
import turtle # 设置初始位置 turtle.penup() turtle.left(90) turtle.fd(200) turtle.pendown() turtle.right(9 ...
- 4.23 Linux(3)
2019-4-23 19:03:53 买的服务器第三天感觉超爽!! 发现学习Linux超爽,有种操作的快感!!!!!是Windows比不了的!! 阿里巴巴镜像源 : https://opsx.alib ...
- web移动端开发技巧
一.meta的使用 1.<meta name="viewport" content="width=device-width,initial-scale=1.0, m ...