大数据与云计算的关系是什么,Hadoop又如何参与其中?Nosql在什么位置,与BI又有什么关系?
1、数据存储层
2、数据处理层
3、数据分析层
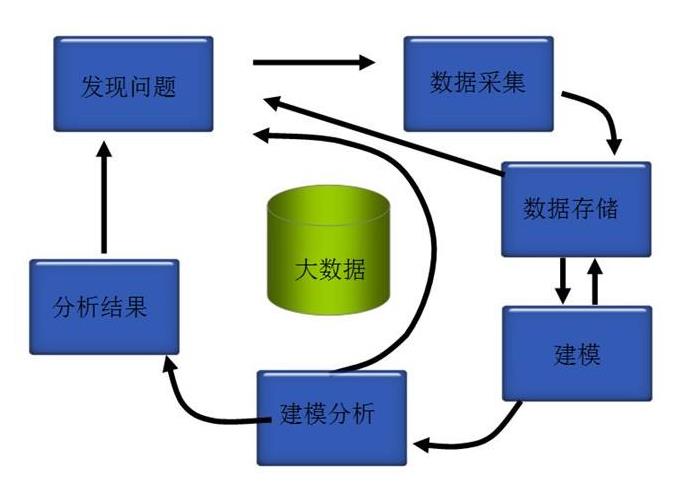
上海尚学堂大数据培训编辑整理,。推荐阅读:《大数据与Hadoop之间的关系》;《云计算大数据高收入的11个技能和3个岗位 》
大数据与云计算的关系是什么,Hadoop又如何参与其中?Nosql在什么位置,与BI又有什么关系?的更多相关文章
- Hadoop,大数据,云计算三者之间的关系
大数据和云计算是何关系?关于大数据和云计算的关系人们通常会有误解.而且也会把它们混起来说,分别做一句话直白解释就是:云计算就是硬件资源的虚拟化;大数据就是海量数据的高效处理.大数据.hadoop及云计 ...
- MongoDB实战指南(一):大数据与云计算
1.1 什么大数据 具体来说,大数据技术涉及到数据的创造,存储,获取和分析,大数据的主要特点有下面几个: 数据量大.一个典型的PC机载2000年前后其存储空间可能有10GB,今天facebook一天增 ...
- 黑马基础阶段测试题:创建一个存储字符串的集合list,向list中添加以下字符串:”C++”、”Java”、” Python”、”大数据与云计算”。遍历集合,将长度小于5的字符串从集合中删除,删除成功后,打印集合中的所有元素
package com.swift; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; ...
- 创新能力加速产业发展,SphereEx 荣获“中关村银行杯”『大数据与云计算』领域 TOP1
8 月 9 日下午,2022 中关村国际前沿科技创新大赛"中关村银行杯"大数据与云计算领域决赛在北京市门头沟区中关村(京西)人工智能科技园·智能文创园落下了帷幕.SphereEx ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- IT大数据服务管理高级课程(IT服务,大数据,云计算,智能城市)
个人简历 金石先生是马克思主义中国化的研究学者,上海财经大学经济学和管理学硕士,中国民主建国会成员,中国特色社会主义人文科技管理哲学的理论奠基人之一.金石先生博学多才,对问题有独到见解.专于工作且乐于 ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- 大数据&人工智能&云计算
仅从技术上讲大数据.人工智能都包含工程.算法两方面内容: 一.大数据: 工程: 1)云计算,核心是怎么管理大量的计算机.存储.网络. 2)核心是如何管理数据:代表是分布式存储,HDFS 3)核心是如何 ...
随机推荐
- mycat+mysql集群:实现读写分离,分库分表
1.mycat文档:https://github.com/MyCATApache/Mycat-doc 官方网站:http://www.mycat.org.cn/ 2.mycat的优点: 配 ...
- rsync拉取服务器上的代码到本地
#!/bin/sh ];then echo "The parameters must be input:file path and host" read -p "(Exa ...
- 论文阅读笔记五十四:Gradient Harmonized Single-stage Detector(CVPR2019)
论文原址:https://arxiv.org/pdf/1811.05181.pdf github:https://github.com/libuyu/GHM_Detection 摘要 尽管单阶段的检测 ...
- C# Aspose.Cells 如何设置单元格样式
//Instantiating a Workbook object Workbook workbook = new Workbook(); //Adding a new worksheet to th ...
- python re库的正则表达式学习笔记
1. 安装 默认已经安装好了python环境了 re库是python3的核心库,不需要pip install,直接import就行 2. 最简单的模式 字符本身就是最简单的模式 比如:'A', 'I ...
- 1.用代码演示String类中的以下方法的用法 (2018.08.09作业)
public class Test_001 { public static void main(String[] args) { String a = "德玛西亚!"; Strin ...
- Linux中jdk的安装配置
1.下载jdk安装包 2.解压文件:tar -zxvf jdk-8u211-linux-x64.tar.gz 3.编辑环境变量:vi /etc/profile 4.在环境变量文末添加三行: expor ...
- Linux-网络综合实验
题目要求:财务部门有俩台机器acc-1和acc-2,it部门有俩台机器it-2和it-2,要求acc机器互通,it机器互通,财务部和it部机器通过路由器互通
- BZOJ.4184.shallot(线段树分治 线性基)
BZOJ 裸的线段树分治+线性基,就是跑的巨慢_(:з」∠)_ . 不知道他们都写的什么=-= //41652kb 11920ms #include <map> #include < ...
- BZOJ.4145.[AMPPZ2014]The Prices(状压DP)
BZOJ 比较裸的状压DP. 刚开始写麻烦惹... \(f[i][s]\)表示考虑了前\(i\)家商店,所买物品状态为\(s\)的最小花费. 可以写求一遍一定去\(i\)商店的\(f[i]\)(\(f ...