大数据与云计算的关系是什么,Hadoop又如何参与其中?Nosql在什么位置,与BI又有什么关系?
1、数据存储层
2、数据处理层
3、数据分析层
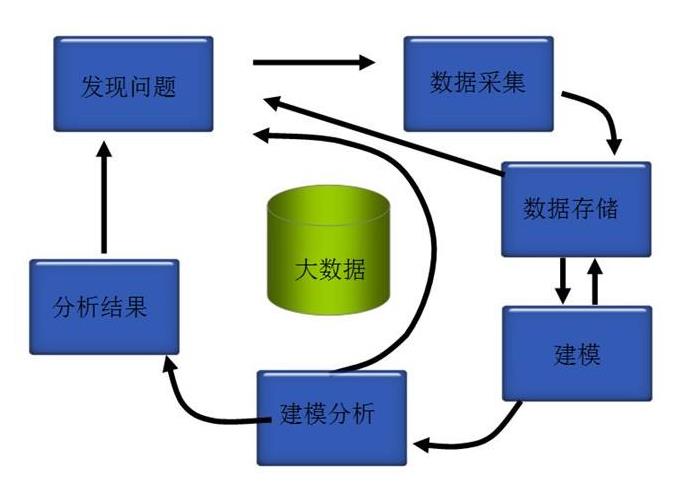
上海尚学堂大数据培训编辑整理,。推荐阅读:《大数据与Hadoop之间的关系》;《云计算大数据高收入的11个技能和3个岗位 》
大数据与云计算的关系是什么,Hadoop又如何参与其中?Nosql在什么位置,与BI又有什么关系?的更多相关文章
- Hadoop,大数据,云计算三者之间的关系
大数据和云计算是何关系?关于大数据和云计算的关系人们通常会有误解.而且也会把它们混起来说,分别做一句话直白解释就是:云计算就是硬件资源的虚拟化;大数据就是海量数据的高效处理.大数据.hadoop及云计 ...
- MongoDB实战指南(一):大数据与云计算
1.1 什么大数据 具体来说,大数据技术涉及到数据的创造,存储,获取和分析,大数据的主要特点有下面几个: 数据量大.一个典型的PC机载2000年前后其存储空间可能有10GB,今天facebook一天增 ...
- 黑马基础阶段测试题:创建一个存储字符串的集合list,向list中添加以下字符串:”C++”、”Java”、” Python”、”大数据与云计算”。遍历集合,将长度小于5的字符串从集合中删除,删除成功后,打印集合中的所有元素
package com.swift; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; ...
- 创新能力加速产业发展,SphereEx 荣获“中关村银行杯”『大数据与云计算』领域 TOP1
8 月 9 日下午,2022 中关村国际前沿科技创新大赛"中关村银行杯"大数据与云计算领域决赛在北京市门头沟区中关村(京西)人工智能科技园·智能文创园落下了帷幕.SphereEx ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- IT大数据服务管理高级课程(IT服务,大数据,云计算,智能城市)
个人简历 金石先生是马克思主义中国化的研究学者,上海财经大学经济学和管理学硕士,中国民主建国会成员,中国特色社会主义人文科技管理哲学的理论奠基人之一.金石先生博学多才,对问题有独到见解.专于工作且乐于 ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- 大数据&人工智能&云计算
仅从技术上讲大数据.人工智能都包含工程.算法两方面内容: 一.大数据: 工程: 1)云计算,核心是怎么管理大量的计算机.存储.网络. 2)核心是如何管理数据:代表是分布式存储,HDFS 3)核心是如何 ...
随机推荐
- 直流滤波器 verilog
// dc filter- y(n) = c*x(n) + (1-c)*y(n-1) `timescale 1ps/1ps module ad_dcfilter #( // data path dis ...
- CISPA Scyther tools
1.Scyther软件作者网站的整理 Scyther工具的网站主页:https://people.cispa.io/cas.cremers/index.html 首先 对Scyther软件的资料进行整 ...
- 集腋成裘-12-git使用-01创建库
一.git安装教程 git安装比较简单,选择好安装路径,直接默认下一步即可 1:检查git是否安装成功 二.SourceTree工具 1:下载&安装 安装过程中如何免注册? 在C:\Users ...
- python+selenium自动测试之WebDriver的常用API(基础篇一)
基于python3.6,selenium3.141,详细资料介绍查看官方API文档,点击这里 一.对浏览器操作 driver = webdriver.Chrome() # 初始化chrome driv ...
- RabbitMQ 实现远程过程调用RPC
RPC调用的顺序1. 在客户端初始化的时候,也就是SimpleRpcClient类初始化的时候,它会随机的创建一个callback队列,用于存放服务的返回值,这个队列是exclusive的.连接断开就 ...
- 通过创建制定版本react-native项目解决“Unable to resolve module `AccessibilityInfo` ”的问题
react-native init MyApp --version 0.55.4 注:不能将--version简写成-v
- Hadoop HDFS安装、环境配置
hadoop安装 进入Xftp将hadoop-2.7.3.tar.gz 复制到自己的虚拟机系统下的放软件的地方,我的是/soft/software 在虚拟机系统装软件文件里,进行解压缩并重命名 进入p ...
- python copy模块
python copy模块 copy模块用于对象的拷贝操作 该模块只提供了两个主要的方法: copy.copy:浅复制 copy.deepcopy:深复制 直接赋值,深拷贝和浅拷贝的区别 直接赋值:简 ...
- ORA-01455
Oracle 用exp 导出数据库的时候,可能会遇到这个错误: Encountering errors in Export logfileEXP-00008: Oracle error # encou ...
- Win10家庭版WindowsUpdate属性为灰色
一般的取消Windows更新只需要打开任务管理器,点击服务 然后点击左下角的打开服务 找到WindowsUpdate,右键属性 按照正常的电脑只要在启动类型中选择禁用,然后在恢复里的第一次操作选择无操 ...