Python 爬虫 JD商品-scrapy+requests
目标站点需求分析
JD商品信息抓取
需求信息字段
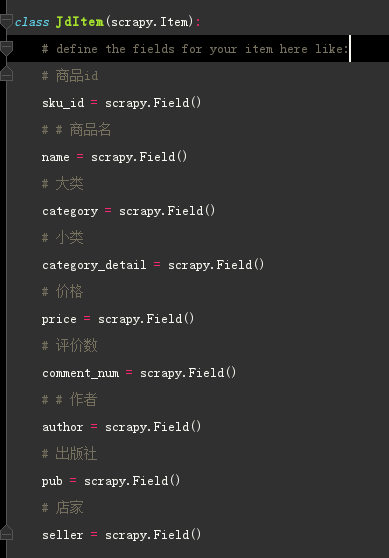
涉及的库
scrapy,
requests,re
lxml
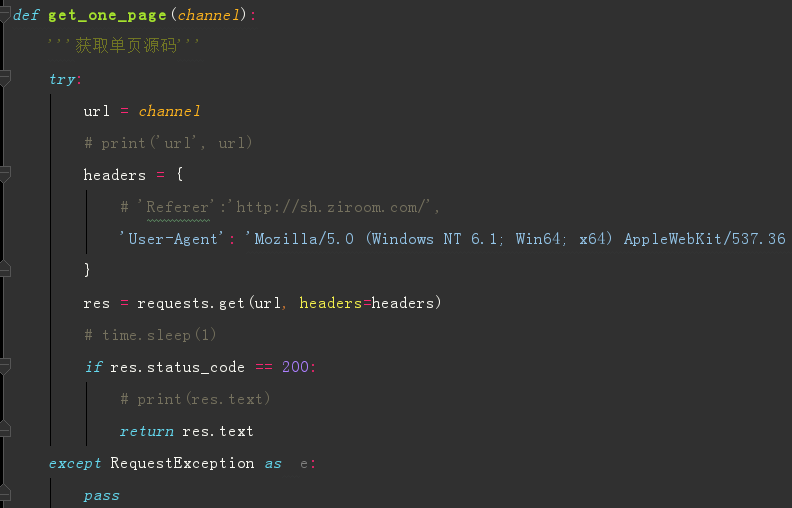
获取单页源码
解析单页源码
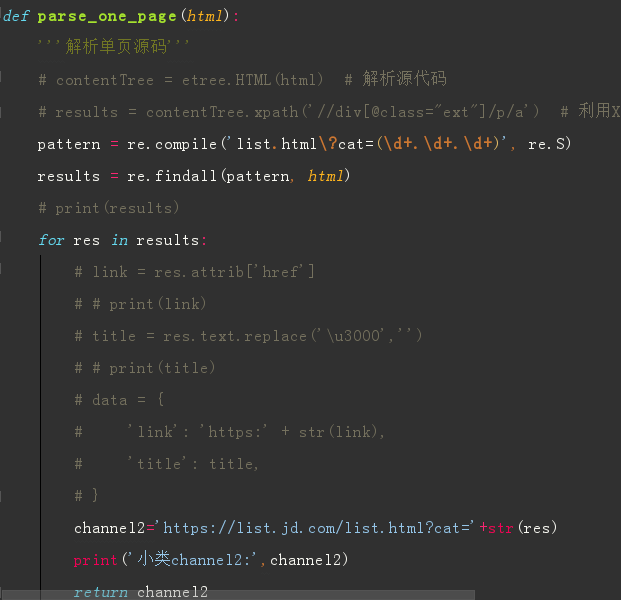
获取总页数

获取商品url
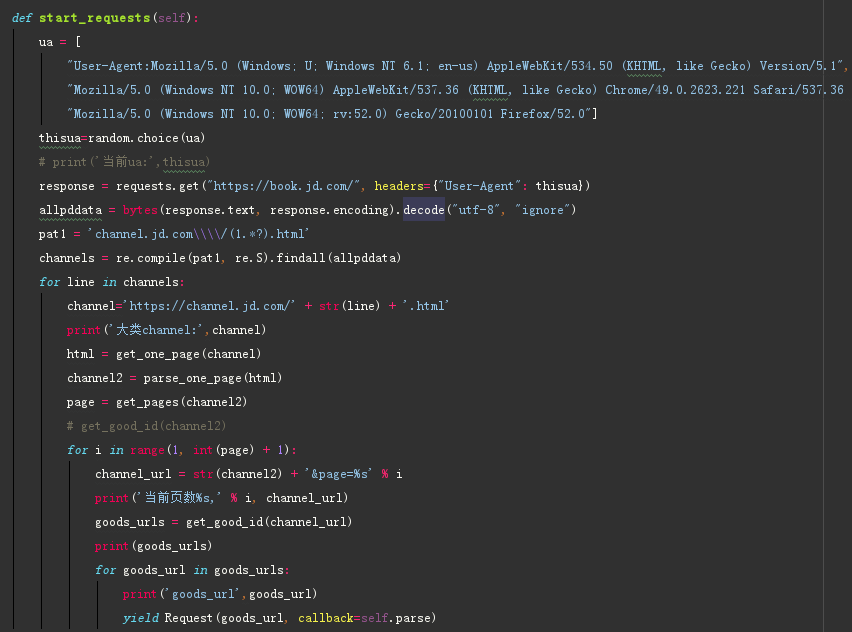
解析商品信息
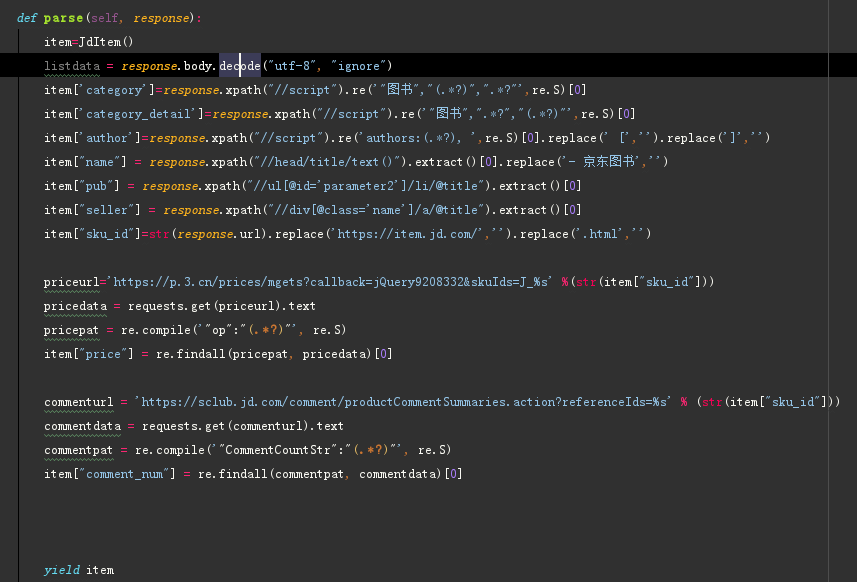
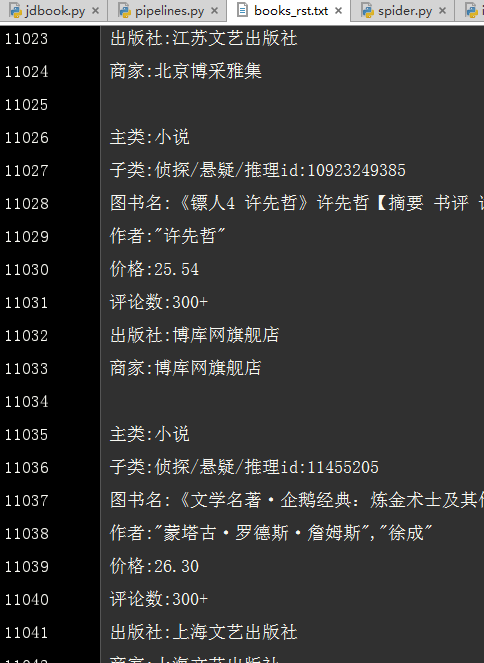
保存本地文件

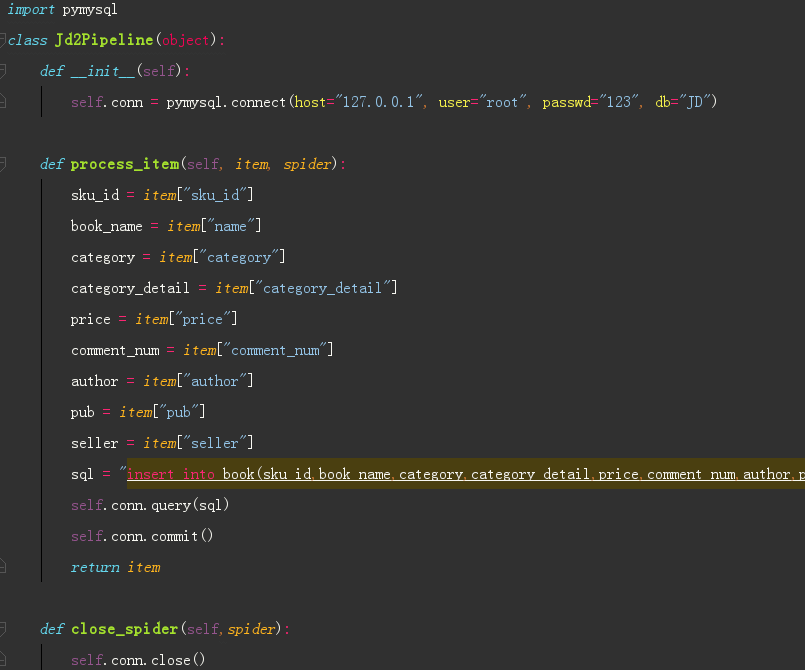
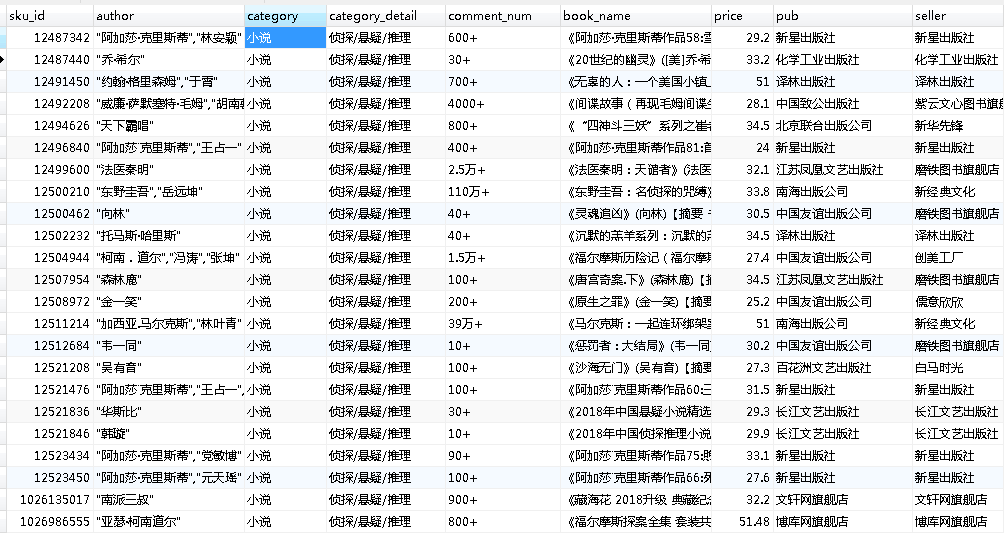
保存mysql数据库
结果
Python 爬虫 JD商品-scrapy+requests的更多相关文章
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫常用之Scrapy 简述
一.安装 pip install scrapy. 如果提示需要什么包就装什么包 有的包pip安装不起,需要自己下载whl文件进行安装. 二.基本的爬虫流程 通用爬虫有如下几步: 构造url --> ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
随机推荐
- 08-JavaScript中的函数
JavaScript中的函数 1.函数简介 函数:就是将一些语句进行封装,然后通过调用的形式,执行这些语句. 函数的作用: 将大量重复的语句写在函数里,以后需要这些语句的时候,可以直接调用函数,避免重 ...
- 播放器更改语言归属地后Cnario player软件无法启动的问题
打开系统运行,输入regedit,进入注册表编辑器. 找到HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\C-nario\Player下面culture 的值,删除即可 ...
- Python exe2shellcode,shellcode2exe
exe2shellcode #! /usr/bin/env python # -*- coding: utf-8 -*- import os import sys def payload(files) ...
- redis从入门到高可用 Redis复制的原理与优化
需要的联系我,QQ:1844912514
- object.observe被废弃了怎么办
用新的 Proxy 具体见:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Proxy
- git 学习(2) ----- 分支
当我们进行程序开发的过程中,有时会产生一个新的想法,然后就想马上试验,那我们怎么办? 如果我们继续在现有的基础上进行开发,但最后想法不成功,我们还要进行版本回退?如果我们的新想法,需要很长时间才能实现 ...
- ovs之组网实验
介绍 本示例将创建两个OVS实例和两个主机,其中每个OVS上接入一个主机,OVS实例之间有链路连接,形成一个链状拓扑,如图.在OVS组网完成之后,再通过手动方式添加流表,实现网络通信,从而验证实验可行 ...
- mysql表加锁、全表加锁、查看加锁、解锁
单个表锁定: 格式: LOCK TABLES tbl_name {READ | WRITE},[ tbl_name {READ | WRITE},……] 例子: lock tables db_a.tb ...
- C++:位操作基础篇之位操作全面总结
位操作篇共分为基础篇和提高篇,基础篇主要对位操作进行全面总结,帮助大家梳理知识.提高篇则针对各大IT公司如微软.腾讯.百度.360等公司的笔试面试题作详细的解答,使大家能熟练应对在笔试面试中位操作题目 ...
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(1 构建目录环境和依赖)
引言:在用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建一 的基础上 继续进行项目搭建 该部分的主要目的是测通MyBatis 及Spring-dao ...