day46-python爬虫学习
一、定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
二、原理
爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
简单来说这段过程发生了以下四个步骤:
查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址
向IP对应的服务器发送请求。
服务器响应请求,发回网页内容。
浏览器显示网页内容。
浏览器工作原理网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
三、使用模块
1.Requests库基础知识
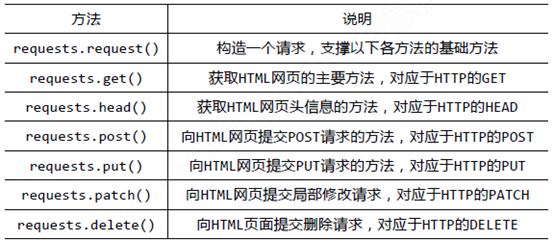
Requests库的get()方法


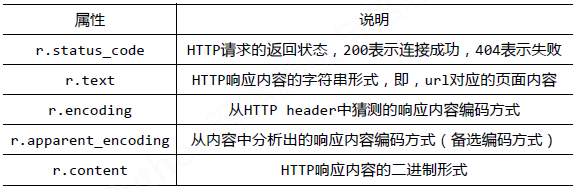
Requests库的Response对象:
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
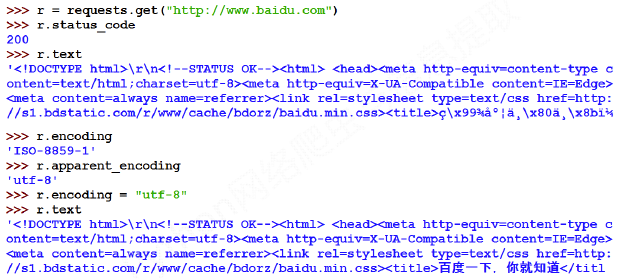
运行截图如下所示:
2、Requests库实例
(1)京东商品的爬取--普通爬取框架
import requests
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败!")
(2)亚马逊商品的爬取--通过修改headers字段,模拟浏览器向网站发起请求
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.status_code)
print(r.text[:1000])
except:
print("爬取失败")
(3)百度/360搜索关键词提交--修改params参数提交关键词
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
import requests
url="http://www.baidu.com/s"
try:
kv={'wd':'Python'}
r=requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
print(r.text[500:5000])
except: print("爬取失败")
(4)网络图片的爬取和存储--结合os库和文件操作的使用
import requests
import os
url="http://tc.sinaimg.cn/maxwidth.800/tc.service.weibo.com/p3_pstatp_com/6da229b421faf86ca9ba406190b6f06e.jpg"
root="D://pics//"
path=root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except: print("爬取失败")
day46-python爬虫学习的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- Linux查看当前目录下文件名中包含指定字符的文件
find . -type f -name "edaijia* 结果:
- laravel 常见问题
1. Specified key was too long; max key length is 767 bytes 处理: 修改config/database.php , mysql配置.删除数据库 ...
- Exp1 PC平台逆向破解 20164303 景圣
逆向及Bof基础实验 实验对象 文件名为pwn1的linux可执行文件. 实验目标:程序正常执行流程weimain调用foo函数,foo函数会简单回显任何用户输入的字符串.该程序同时包含另一个代码片段 ...
- Vue学习——使用vue-cli搭建一个简单的本地vue项目
前提 安装好node.js.npm.vue-cli.为什么要先安装这些,建议查看https://www.cnblogs.com/jixue/p/10673875.html,这个对于vue-cli理解很 ...
- Pycharm 的设置--参数设置(运行.py文件带参数,例如argument)
程序运行时,如果需要输入参数,如下图中程序代码: 在生成exe后,程序在控制台下运行时格式为: 这种情况在调试程序时,如果只是在Pycharm环境中简单执行“Run”菜单下的“Run”命令,会出现以下 ...
- .Net dependent configuration
error info: 解决方案:在.exe.config文件中配置Newtonsoft.Json所用版本 <runtime> <assemblyBinding xmlns=&quo ...
- POJ1848--Tree ——树形dp
题意:给你一个树,问你最少连几条边可以让树中的每一个节点在且只在一个环内.如果无法完成就输出-1. 我们设dp[i][0]为根节点为i的树变成每一个节点都在且只在一个环里所需要的最小边数.dp[i][ ...
- ng/cli new skip install and do not create a folder
ng new myApp --skip-install --directory ./
- 常见的JavaWeb安全问题及修复
1.SQL注入:程序向后台数据库传递SQL时,用户提交的数据直接拼接到SQL语句中并执行,从而导入SQL注入攻击. 字符型注入:黑色部分为拼接的问题参数 select * from t_user wh ...
- Redhat更换yum源
redhat 默认自带的 yum 源需要注册,才能更新,所以对于我们来说需要替换掉redhat的yum源.下文更换为网易的. 删除原有的yum rpm -qa|grep yum|xargs rpm - ...