day46-python爬虫学习
一、定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
二、原理
爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
简单来说这段过程发生了以下四个步骤:
查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址
向IP对应的服务器发送请求。
服务器响应请求,发回网页内容。
浏览器显示网页内容。
浏览器工作原理网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
三、使用模块
1.Requests库基础知识
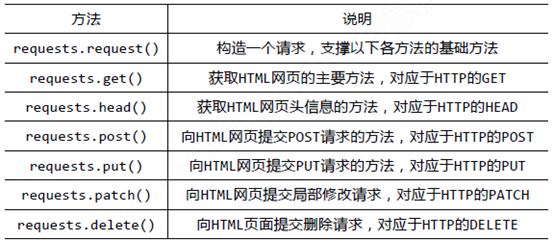
Requests库的get()方法


Requests库的Response对象:
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
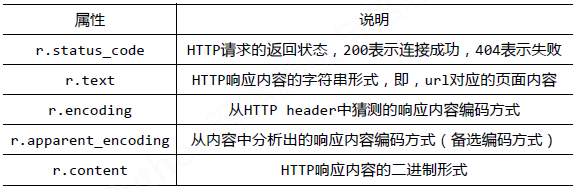
运行截图如下所示:
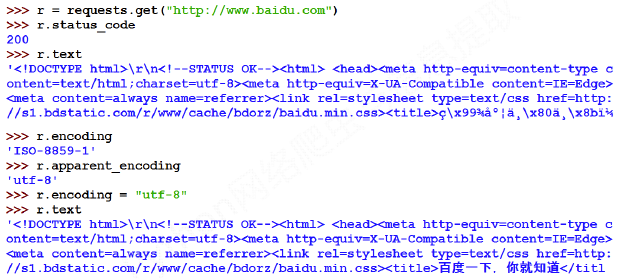
2、Requests库实例
(1)京东商品的爬取--普通爬取框架
import requests
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败!")
(2)亚马逊商品的爬取--通过修改headers字段,模拟浏览器向网站发起请求
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.status_code)
print(r.text[:1000])
except:
print("爬取失败")
(3)百度/360搜索关键词提交--修改params参数提交关键词
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
import requests
url="http://www.baidu.com/s"
try:
kv={'wd':'Python'}
r=requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
print(r.text[500:5000])
except: print("爬取失败")
(4)网络图片的爬取和存储--结合os库和文件操作的使用
import requests
import os
url="http://tc.sinaimg.cn/maxwidth.800/tc.service.weibo.com/p3_pstatp_com/6da229b421faf86ca9ba406190b6f06e.jpg"
root="D://pics//"
path=root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except: print("爬取失败")
day46-python爬虫学习的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- k8s集群安装
准备三台虚拟机,一台做master,两台做master节点,关闭selinux. 一.安装docker,两node节点上进行 1. 2.安装docker依赖包:yum install -y yum-u ...
- Vue 组件&组件之间的通信 父子组件的通信
在Vue的组件内也可以定义组件,这种关系成为父子组件的关系: 如果在一个Vue实例中定义了component-a,然后在component-a中定义了component-b,那他们的关系就是: Vue ...
- Dataframe 多行合并为一行
原表数据: 最后4行合并为1行: def ab(df): return','.join(df.values) df = df.groupby(['股票代码','股票简称'])['所属概念'].appl ...
- npm install
npm install moduleName 命令 1. 安装模块到项目node_modules目录下.2. 不会将模块依赖写入devDependencies或dependencies 节点.3. 运 ...
- flutter测试页
import 'package:flutter/material.dart'; // 应用页面使用有状态Widget class AppScene extends StatefulWidget { @ ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- 最大子段和的DP算法设计及其效率测试
表情包形象取自番剧<猫咪日常> 那我也整一个 曾几何时,笔者是个对算法这个概念漠不关心的人,由衷地感觉它就是一种和奥数一样华而不实的存在,即便不使用任何算法的思想我一样能写出能跑的程序 直 ...
- 【VS2019】F12跳转到源码
1.工具->选项 2.文本编辑器->C#->高级->勾选支持导航到反编译源码 3.关闭浏览器不停止项目
- OpenGL.Tutorial03_Matrices_测试
1. 2. // ZC: 工程-->右键-->属性--> 配置属性: // ZC: C/C++ -->常规-->附加包含目录,里面添加: // ZC: E:\OpenGL ...
- 使用pyinstaller打包多个py文件为一个EXE文件
1. 安装pyinstaller. pip install pyinstaller !!!!64位win7上打包后始终不能用,提示找不到ldap模块,换了32位win7就好了.!!!!(代码中涉及ld ...