python学习过程(四)
上节我们说了怎么从一个网页中获取所有的a标签,包括a标签的文本和a标签的url,以及最后经过整理,直接从网页中获取key-value键值对,也就是标签:url这种形式。
例如 : 百度: http://www.baidu.com
在此基础,我们还可以做一些模糊筛选,将我们感兴趣的所有标签查找初来,供进一步爬虫分别爬取各个页面。今天,我们就是来做的事情就是把页面中的文本内容取出来,
类似的效果比如是这样的:


下面我们就一步步来实现这个过程:
首先是我们做的事情是导入一个类工具,对应的代码可以和我照着这么写就可以了:
import urllib2
import re
from sgmllib import SGMLParser
导入了这个东西以后,我们就可以来创建我们自己的类来继承这个类,到时候里面的很多方法会很有用哦. . .
看看我们的类是什么样的:
class GetIdList(SGMLParser): #此处定义一个自己的类,叫作GetIdList,它肯定要继承SGMLParser啦
def reset(self):
self.IDlist = [] #这就是最后返回给我们的结果,先是空的
self.flag = False #这就是一个做标记的作用,默认开始是False
self.getdata=False #这也是标志作用,是否开始获取数据
self.verbatim = 0
SGMLParser.reset(self) def start_div(self,attrs): #表示遇到了一个div的开始,也就是碰到了<div>
if self.flag == True:
self.verbatim +=1 #进入子层div
return
for k,v in attrs: #我的理解就是attrs包含了class的信息,如果是碰到了我感兴趣的,
if k =='class' and v =='entry-content': #这里entry-content是根据自己网页改,看你自己对哪个感兴趣
self.flag=True
return def end_div(self): #表示结束div,碰到</div>
if self.verbatim ==0:
self.flag=False
if self.flag == True:
self.verbatim -=1 def start_p(self,attrs): #碰到p标签开始
if self.flag == False:
return
self.getdata=True #可以获取数据 def end_p(self):#遇到</p> #碰到p标签结束,
if self.getdata:
self.getdata = False #停止获取数据啦 def handle_data(self, text):#处理文本
if self.getdata:
self.IDlist.append(text) #把我获取到的数据加到list中 def printID(self): #这里就是打印出获取到的结果并返回
for i in self.IDlist:
print i
return self.IDlist
类写好了,怎么去用呢??用时需要条件嘛,现在只是一个类,我们要对它实例化,学过java的知道,我们没有对象,去new一个就可以了嘛,
有了这个类的实例,你还有给我网页的文本嘛,也就是html源码嘛,前面我们说了怎么从网络上获取html,这里我们就开头图上说的那个静态的字符串
好了,看代码怎么去操作这个html,解析出我们想要的数据:
def printText(html):
lister = GetIdList() #创建实例,这里可千万别说new一个
lister.feed(html) #提供我们的html
l = lister.printID() #开始打印输出吧 printText(the_page)
这样,我们就把网页中感兴趣的div内容取出了,看结果:

啊?为什么最头上的<a></a>怎么没有,而<p><a href="http://www.baidu.com">感兴趣内容里面的a标签</a></p>却有呀,
因为前面123直接在div下,而感兴趣内容里面的a标签在P标签下,仔细看我们设计的类里,因为后者在p标签下,为了也获取前者123,我们完全可以在类里加这么两个函数
来获取a标签的123,看图:
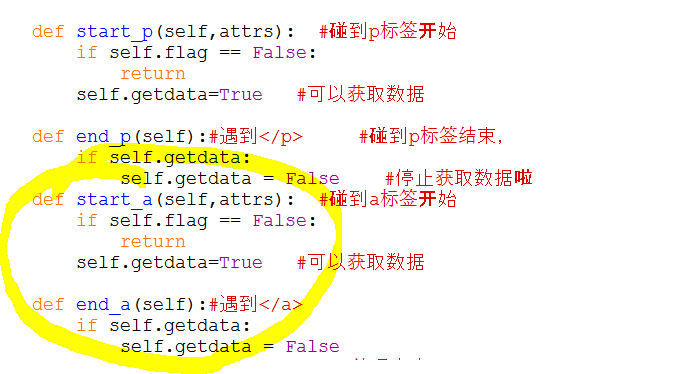

加了start_a和end_a,就可以获取到了我们div下的<a>123</a>了,那么我还想获取 <h1> 、<table> 、<ul> 、 . . . . . . 不用说了吧
接下来是不是可以获取到我感兴趣的一切啦?还在等什么,赶紧行动起来吧!!!
python学习过程(四)的更多相关文章
- 孤荷凌寒自学python第四十九天继续研究跨不同类型数据库的通用数据表操作函数
孤荷凌寒自学python第四十九天继续研究跨不同类型数据库的通用数据表操作函数 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 不同类型 ...
- 孤荷凌寒自学python第四十八天通用同一数据库中复制数据表函数最终完成
孤荷凌寒自学python第四十八天通用同一数据库中复制数据表函数最终完成 (完整学习过程屏幕记录视频地址在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 今天经过反复折腾,最终基本上算 ...
- 孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数
孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数 (完整学习过程屏幕记录视频地址在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 今天打算完成的是通用的(至少目 ...
- 孤荷凌寒自学python第四十六天开始建构自己用起来更顺手一点的Python模块与类尝试第一天
孤荷凌寒自学python第四十六天开始建构自己用起来更顺手一点的Python模块与类,尝试第一天 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 按上一天的规划,这是根据过去我自学其它编程语 ...
- 孤荷凌寒自学python第四十五天Python初学基础基本结束的下阶段预安装准备
孤荷凌寒自学python第四十五天Python初学基础基本结束的下阶段预安装准备 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天本来应当继续学习Python的数据库操作,但根据过去我自 ...
- 孤荷凌寒自学python第四十四天Python操作 数据库之准备工作
孤荷凌寒自学python第四十四天Python操作数据库之准备工作 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天非常激动地开始接触Python的数据库操作的学习了,数据库是系统化设计 ...
- 孤荷凌寒自学python第四十三天python 的线程同步之Queue对象
孤荷凌寒自学python第四十三天python的线程同步之Queue对象 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) Queue对象是直接操作队列池的对象,队列中可以存放多种对象,当然也 ...
- 孤荷凌寒自学python第四十二天python线程控制之Condition对象
孤荷凌寒自学python第四十二天python的线程同步之Condition对象 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天学习了Condition对象,发现它综合了Event对象 ...
- 孤荷凌寒自学python第四十天python 的线程锁RLock
孤荷凌寒自学python第四十天python的线程锁RLock (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 因为研究同时在多线程中读写同一个文本文件引发冲突,所以使用Lock锁尝试同步, ...
- 孤荷凌寒自学python第四天 安装python的其它IDE环境
孤荷凌寒自学python第四天 安装python的其它IDE环境 (完整学习过程屏幕记录视频地址在文末) 因为是完全的新手,对python环境搭建完全一无所知,因此,可真是大费周章才配置了其它多个Id ...
随机推荐
- PostgreSQL recovery.conf恢复配置
PostgreSQL recovery.conf恢复配置 这一章描述recovery.conf 文件中可用的设置.它们只应用于恢复期.对于你希望执行的任意后续恢复, 它们必须被重置.一旦恢复已经开始, ...
- SpringMVC 之URL请求到Action的映射(1)
URL路径映射 1.1.对一个action配置多个URL映射: @RequestMapping(value={"/index", "/hello"}, meth ...
- react-router4.x 实用例子(路由过渡动画、代码分割)
react-router4.2.0实用例子 代码分割 官网上面写的代码分割是不支持create-react-app脚手架的,要使用import实现 创建一个bundle.js文件 import { C ...
- 2014.12.22 几个有用的oracle正则表达式
SELECT REGEXP_REPLACE('LSS12345', '[^0-9]') FROM DUAL 结果:12345 '[^0-9]'中的^表示‘非’上述表达式的含义是“将LSS12345中的 ...
- 人工智能一之TensorFlow环境配置
1.安装pip:sudo apt-get install python-pip python-dev 2.定义仅支持CPU的python2.7环境下TensorFlow安装包地址:export TF_ ...
- python去掉括号之间的字符
在字符串中识别括号并删除括号及其中的内容括号包括 大中小 3种括号 输入为 1个字符串 s="我是一个人(中国人)[真的]{确定}"; 输出为 result = "我是一 ...
- cookie禁用后重定向跳转时session的跟踪
- VS项目模板文件位置
目录: D:\Users\lyn\Documents\Visual Studio 2012\Templates\ProjectTemplates 模板文件完整路径: D:\Users\lyn\Do ...
- eclipse java 注释模板配置详解
设置注释模板的入口: Window->Preference->Java->Code Style->Code Template 然后展开Comments节点就是所有需设置注释的元 ...
- centos 端口iptables配置
1.安装iptables yum install iptables* -y 2.打开端口 iptables -I INPUT -p tcp --dport -j ACCEPT 3.查看本机关于IPTA ...