【转】Hive学习路线图
原文博客出自于:http://blog.fens.me/hadoop-hive-roadmap/ 感谢!
Hive学习路线图
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-hive-roadmap/

前言
Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作。就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。
让我们把Hive的环境构建起来,帮助非开发人员也能更好地了解大数据。
目录
- Hive介绍
- Hive学习路线图
- 我的使用经历
- Hive的使用案例
1. Hive介绍
Hive起源于Facebook,它使得针对Hadoop进行SQL查询成为可能,从而非程序员也可以方便地使用。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
详细地Hive的安装和使用介绍,请参考文章:Hive安装及使用攻略
2. Hive学习路线图
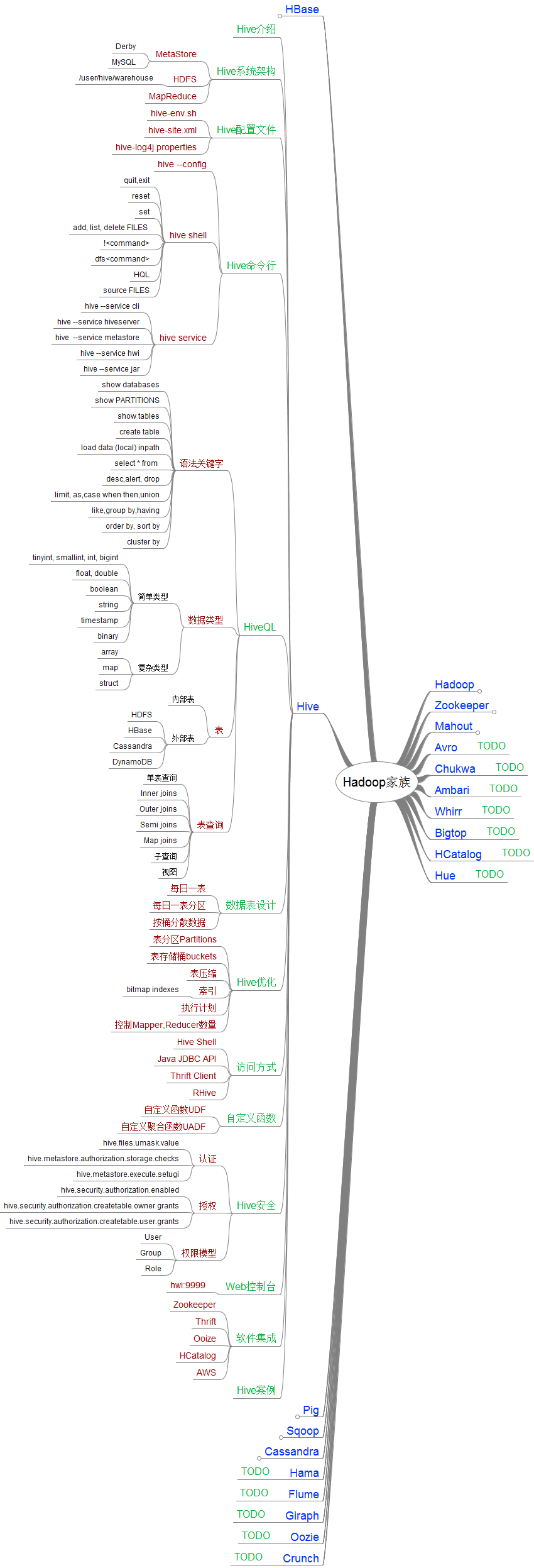
Hive的知识点,我已经列在图中,希望帮助其他人更好的了解Hive。
接下来,是我的使用经历,谁都没有捷径。把心踏实下来,就不那么难了。
3. 我的使用经历
我使用Hive有两个考虑:
- 1. 帮助无开发经验的数据分析人员,有能力处理大数据
- 2. 构建标准化的MapReduce开发过程
1). 帮助无开发经验的数据分析人员,有能力处理大数据
完全符合与Hive的设计理念,一直在强调,无需多言。
2). 构建标准化的MapReduce开发过程
这个方面是我们需要努力的方向。
首先,Hive已经用类SQL的语法封装了MapReduce过程,这个封装过程就是MapReduce的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这是第二层封装是在Hive之上的封装。在第二层封装时,我们要尽可能多的屏蔽Hive的细节,让接口单一化,低少灵活性,再次精简HQL的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道Hive是什么, 更不用知道Hadoop是什么。我们只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
当我们完成了Hive的二次封装后,我们可以构建标准化的MapReduce开发过程。
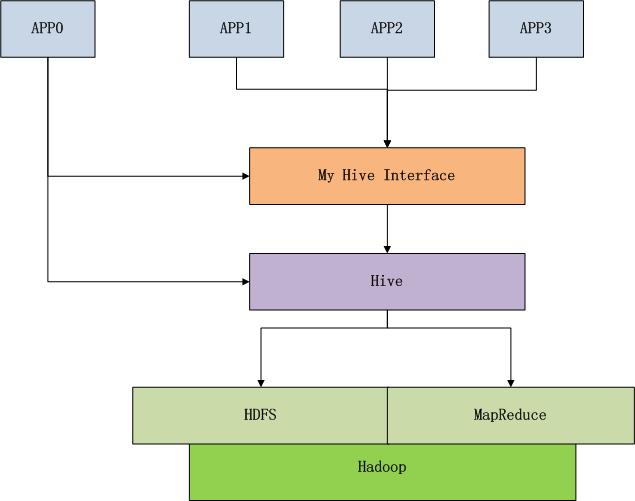
通过上图的思路,我们可以统一企业内部各种应用对于Hive的依赖,并且当人员素质升高后,有可以剥离Hive,用更优秀的底层解决方案来替换,如果封装的接口的不变,甚至替换Hive时业务使用都不知道,我们已经替换了Hive。
这个过程是需要经历的,也是有意义的。当我在考虑构建Hadoop分析工具时,以Hive作为Hadoop访问接口是最有效的。
3). 有关Hive的运维:
因为Hive是基于Hadoop构建的,简单地说就是一套Hadoop的访问接口,Hive本身并没有太多的东西,所以运维上面我们注意下面几个问题就行了。
- 1. 使用单独的数据库存储元数据
- 2. 定义合理的表分区和键
- 3. 设置合理的bucket数据量
- 4. 进行表压缩
- 5. 定义外部表使用规范
- 6. 合理的控制Mapper, Reducer数量
4. Hive的使用案例
已经整理成文章的案例
相关文章:
Hadoop家族产品学习路线图
【转】Hive学习路线图的更多相关文章
- Hive学习路线图(转)
Hadoophivehqlroadmap学习路线图 1 Comment Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig ...
- Hive学习路线图--张丹老师
前言 Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作 ...
- Hive学习路线图
- Hadoop学习路线图
Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括, ...
- Hadoop家族学习路线图--转载
原文地址:http://blog.fens.me/hadoop-family-roadmap/ Sep 6, 2013 Tags: Hadoophadoop familyroadmap Comment ...
- Hadoop家族学习路线图
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop家族学习路线图v
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- hive学习路线
hive学习路线图:
- 转】Mahout学习路线图
原博文出自于: http://blog.fens.me/hadoop-mahout-roadmap/ 感谢! Mahout学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目 ...
随机推荐
- 《OD学hadoop》第三周0709
一.MapReduce编程模型1. 中心思想: 分而治之2. map(映射)3. 分布式计算模型,处理海量数据4. 一个简单的MR程序需要制定map().reduce().input.output5. ...
- oracle教程:PLSQL常用方法汇总
oracle教程:PLSQL常用方法汇总 在SQLPLUS下,实现中-英字符集转换alter session set nls_language='AMERICAN';alter session set ...
- ural1221. Malevich Strikes Back!
http://acm.timus.ru/problem.aspx?space=1&num=1221 算是枚举的 题目意思是必须划出这样的 11011 10001 00000 10001 110 ...
- Java中的private、protected、public和default的区别
(1)对于public修饰符,它具有最大的访问权限,可以访问任何一个在CLASSPATH下的类.接口.异常等.它往往用于对外的情况,也就是对象或类对外的一种接口的形式. (2)对于protec ...
- 使用Less color函数创建专业网站配色方案
Less提供了很多实用的函数专门用于定义和操作色彩.本文将介绍如何使用这些函数来 帮助你控制色彩,创造合适的色彩搭配,并且保持网站的一致性和专业性 color spinning spin()函数允许我 ...
- UIImagePicker照片选择器
UIImagePickerController 1.+(BOOL)isSourceTypeAvailable:(UIImagePickerControllerSourceType)sourceType ...
- 切记一定要防止恶意用户直接访问Ajax请求地址
多年前的一个web项目, 有一个地方是用ajax发送短信验证码, 当时没考虑好, 没判断来路, 这几天被人恶意滥用发送了很多垃圾短信, 投诉到公司来了. 今天一看代码吓出一身冷汗! 以后一定要记得判 ...
- *ecshop安装模板
1. 安装模板 例: 新建abc.com文件 复制default下的style.css 修改两个http://www.ecshop.com/ 为 http://www.hua.com/ 复制defau ...
- db2数据库创建一张表,并为该表加上主键递增的性能和中间表的创建的sql语句
创建角色表 CREATE TABLE NBCTXP.TBL_NBC_NONBANKROLE ( ID BIGINT NOT NULL, ROLENAME VARCHAR(50), C ...
- 如何正确选择MySQL数据列类型
MySQL数据列类型选择是在我们设计表的时候经常会遇到的问题,下面就教您如何正确选择MySQL数据列类型,供您参考学习. 选择正确的数据列类型能大大提高数据库的性能和使数据库具有高扩展性.在选择MyS ...