C# & SQL Server大数据量插入方式对比
以下内容大部分来自:
http://blog.csdn.net/tjvictor/article/details/4360030
部分内容出自互联网,实验结果为亲测。
最近自己开发一个向数据库中插入大量历史数据的函数库,需要解决一个大数据量插入的效率问题。不用分析,我知道如果采取逐条数据插入的方式,那么效率肯定很低,光是那么多循环就知道很慢了。于是乎,我找到了上篇博客,知道了BulkCopy和TVPs方式。为了更好的了解其效率,我自己动手亲测了一下效果,测试的数据库位于本机。
(1)方式1:循环插入
public static void NormalInerst(String connString)
{
Console.WriteLine("使用NNormalInerst方式:");
Stopwatch sw = new Stopwatch();
SqlConnection sqlConn = new SqlConnection(connString);
SqlCommand sqlCmd = new SqlCommand();
sqlCmd.CommandText = String.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");
sqlCmd.Parameters.Add("@p0", SqlDbType.Int);
sqlCmd.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlCmd.Parameters.Add("@p2", SqlDbType.VarChar);
sqlCmd.CommandType = CommandType.Text;
sqlCmd.Connection = sqlConn;
sqlConn.Open();
try
{
for (int i = , j = ; i < ; ++i )
{
for (j = i * ; j < (i + ) * ; ++j )
{
sqlCmd.Parameters["@p0"].Value = j;
sqlCmd.Parameters["@p1"].Value = String.Format("User-{0}", i * j);
sqlCmd.Parameters["@p2"].Value = String.Format("Pwd-{0}", i * j);
sw.Start();
sqlCmd.ExecuteNonQuery();
sw.Stop();
} Console.WriteLine("第{0}次插入{1}条数据耗时:{2}", (i + ), dataScale, sw.ElapsedMilliseconds);
sw.Reset();
}
}
catch (System.Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
}
该方式的效率极低,运行时间很长,我这里就不给出结果了,有兴趣可以自己粘贴试一下。PS:其中的数据规模应该是dataScale而不是10000,不过总是还是慢。
(2)方式2:使用BulkCopy
public static void BulkInerst(String connString)
{
Console.WriteLine("使用BulkInerst方式:");
Stopwatch sw = new Stopwatch(); String strDel = "delete from BulkTestTable";
float millTime = ;
for (int multiply = ; multiply < ; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * dataScale; count < (multiply + ) * dataScale; count++)
{
DataRow r = dt.NewRow();
r[] = count;
r[] = string.Format("User-{0}", count * multiply);
r[] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
} SqlConnection sqlConn = new SqlConnection(connString);
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlConn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count; sw.Reset();
sw.Start();
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != )
bulkCopy.WriteToServer(dt);
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
if (bulkCopy != null)
bulkCopy.Close();
}
sw.Stop(); Console.WriteLine("第{0}次插入{1}条数据耗时:{2}", (multiply + ), dataScale, sw.ElapsedMilliseconds);
millTime += sw.ElapsedMilliseconds;
}
Console.WriteLine("总耗时:{0}毫秒,平均耗时:{1}毫秒", millTime, millTime / );
SqlConnection sqlConn2 = new SqlConnection(connString);
SqlCommand sqlCmd = new SqlCommand(strDel, sqlConn2);
try
{
sqlConn2.Open();
sqlCmd.ExecuteNonQuery();
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn2.Close();
}
Console.WriteLine("Done!");
}
(3)方式3:使用TVPs
public static void TVPsInerst(String connString)
{
Console.WriteLine("使用TVPsInerst方式:");
Stopwatch sw = new Stopwatch();
SqlConnection sqlConn = new SqlConnection(connString);
String strSQL = "insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
String strDel = "delete from BulkTestTable";
float millTime = ; for (int multiply = ; multiply < ; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * dataScale; count < (multiply + ) * dataScale; count++)
{
DataRow r = dt.NewRow();
r[] = count;
r[] = string.Format("User-{0}", count * multiply);
r[] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
} sw.Reset();
sw.Start();
SqlCommand cmd = new SqlCommand(strSQL, sqlConn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.BulkUDT";
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != )
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
sw.Stop(); Console.WriteLine("第{0}次插入{1}条数据耗时:{2}", (multiply + ), dataScale, sw.ElapsedMilliseconds);
millTime += sw.ElapsedMilliseconds;
}
Console.WriteLine("总耗时:{0}毫秒,平均耗时:{1}毫秒", millTime, millTime / );
SqlCommand sqlCmd = new SqlCommand(strDel, sqlConn);
try
{
sqlConn.Open();
sqlCmd.ExecuteNonQuery();
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
Console.WriteLine("Done!");
}
这里TVPs方式需要利用Visual Studio 2008采用的自定义数据表类型,这是一个比较新的东西。这里补充几个类型和函数,主要是为了检测数据库中是否存在数据表和数据表类型,如果不存在则进行创建。补充代码如下:
public enum CheckType
{
isTable = ,
isType
} protected static int dataScale = ; public static bool CheckExistsObject(String connString, String objectName, CheckType type)
{
String strSQL = "select COUNT(1) from sys.sysobjects where name='" + objectName + "'";
switch (type)
{
case CheckType.isTable:
strSQL = "select COUNT(1) from sys.sysobjects where name='" + objectName + "'";
break;
case CheckType.isType:
strSQL = "select COUNT(1) from sys.types where name='" + objectName + "'";
break;
default:
break;
}
using (SqlConnection conn = new SqlConnection(connString))
{
conn.Open();
SqlCommand cmd = new SqlCommand(strSQL, conn);
int result = Convert.ToInt32(cmd.ExecuteScalar());
if ( == result)
{
return false;
}
} return true;
} public static bool CreateObject(String connString, String objectName, CheckType type)
{
String strSQL = "";
switch (type)
{
case CheckType.isTable:
strSQL = "Create table " + objectName + " (Id int primary key, UserName nvarchar(32), Pwd varchar(16))";
break;
case CheckType.isType:
strSQL = "CREATE TYPE " + objectName + " AS TABLE (Id int, UserName nvarchar(32), Pwd varchar(16))";
break;
default:
break;
}
using (SqlConnection conn = new SqlConnection(connString))
{
conn.Open();
SqlCommand cmd = new SqlCommand(strSQL, conn);
cmd.ExecuteNonQuery();
} return true;
}
public static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[]{
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))}); return dt;
}
调用的方式就很好说了,参见如下测试代码:
public static void Main(string[] args)
{
String conString = "Persist Security Info=False;User ID=sa;Password=scbj123!@#;Initial Catalog=testGR;Server=KLH-PC";
String strType = "BulkUDT";
String strTable = "BulkTestTable";
if (!CheckExistsObject(conString, strType, CheckType.isType))
{
Console.WriteLine("类型{0}不存在", strType);
if (CreateObject(conString, strType, CheckType.isType))
{
Console.WriteLine("类型{0}创建成功!", strType);
}
} if (!CheckExistsObject(conString, strTable, CheckType.isTable))
{
Console.WriteLine("表格{0}不存在", strTable);
if (CreateObject(conString, strTable, CheckType.isTable))
{
Console.WriteLine("表格{0}创建成功!", strTable);
}
}
Console.WriteLine("=================================================="); //NormalInerst(conString);
BulkInerst(conString);
TVPsInerst(conString); Console.ReadKey();
}
-------------------------------------------------------------------------------------------------
直接看效果对比:
<1>第一次运行
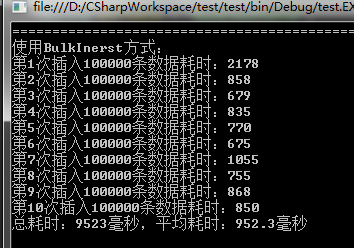
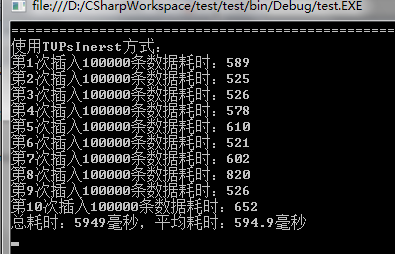
<2>第二次和第三次运行
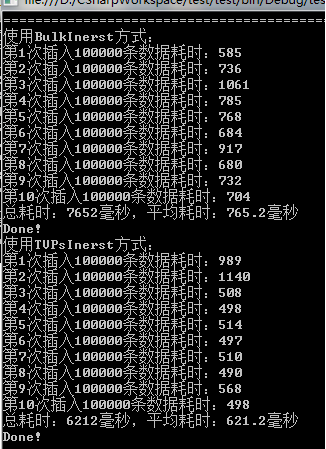
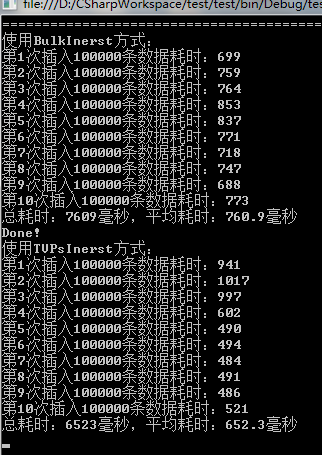
这里考虑到了SQL Server自身缓存的原因,所以进行了多次测试,不过数据量没有变。可以从上述结果中看出:TVPs方式不愧是新出的啊,一代更比一代强!
C# & SQL Server大数据量插入方式对比的更多相关文章
- sql server 2005 大数据量插入性能对比
sql server 2005大数据量的插入操作 第一,写个存储过程,传入参数,存储过程里面是insert操作, 第二,用System.Data.SqlClient.SqlBulkCopy实例方法, ...
- [转]Sql server 大数据量分页存储过程效率测试附代码
本文转自:http://www.cnblogs.com/lli0077/archive/2008/09/03/1282862.html 在项目中,我们经常遇到或用到分页,那么在大数据量(百万级以上)下 ...
- SQL Server 大数据量insert into xx select慢的解决方案
最近项目有个需求,把一张表中的数据根据一定条件增删改到另外一张表.按理说这是个很简单的SQL.可是在实际过程中却出现了超级长时间的执行过程. 后来经过排查发现是大数据量insert into xx s ...
- SQL Server 大数据量批量插入
private void AddShuJu_Click(object sender, RoutedEventArgs e) { Stopwatch wath = new Stopwatch(); wa ...
- SQL Server 大数据量分页建议方案
简单的说就是这个 select top(20) * from( select *, rowid = row_number() over(order by xxx) from tb with(noloc ...
- mysql/oracle jdbc大数据量插入优化
10.10.6 大数据量插入优化 在很多涉及支付和金融相关的系统中,夜间会进行批处理,在批处理的一开始或最后一般需要将数据回库,因为应用和数据库通常部署在不同的服务器,而且应用所在的服务器一般也不会 ...
- SQL优化-大数据量分页优化
百万数据量SQL,在进行分页查询时会出现性能问题,例如我们使用PageHelper时,由于分页查询时,PageHelper会拦截查询的语句会进行两个步骤 1.添加 select count(*)fro ...
- sql server 大数据, 统计分组查询,数据量比较大计算每秒钟执行数据执行次数
-- 数据量比较大的情况,统计十分钟内每秒钟执行次数 ); -- 开始时间 ); -- 结束时间 declare @num int; -- 结束时间 set @begintime = '2019-08 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
随机推荐
- c++ 走向高级之日积月累
1.enum:http://en.cppreference.com/w/cpp/language/enum 2.weak_pr:http://en.cppreference.com/w/cpp/mem ...
- insertAdjacentHTML
/** * insertAdjacentHTML * 支持 insertAdjacentHTML()方法的浏览器有 IE.Firefox 8+.Safari.Opera 和 Chrome */ var ...
- 面向过程部分 Java 和 C++ 的区别
前言 Java 和 C++ 在面向过程部分区别并不大,但还是有的,本文罗列了这些区别. 在 Java 中: 1. 数据类型的范围和机器无关 2. 加上前缀 0b 可以表示二进制数,如 0b1001 就 ...
- Web应用开发工具及语言需要具备的功能探索
1 前言 最近一个多月在做Web项目,用到的技术有(也不算泄漏公司机密吧): 后台:Struts 2(with JSP/FreeMarker).Spring.Hibernate.MySQL.Web S ...
- 获取元素高度及定位js
<script type="text/javascript"> $(window).scroll(f ...
- 浅谈C中的malloc和free
转自http://bbs.bccn.net/thread-82212-1-1.html非常感谢作者 浅谈C中的malloc和free 在C语言的学习中,对内存管理这部分的知识掌握尤其重要!之前对C中的 ...
- C++ Primer : 第十二章 : 动态内存之动态数组
动态数组的分配和释放 new和数组 C++语言和标准库提供了一次分配一个对象数组的方法,定义了另一种new表达式语法.我们需要在类型名后跟一对方括号,在其中指明要分配的对象的数目. int* arr ...
- JavaScript学习记录总结(五)——servlet将json数据写出去
定义teacher和student实体 json.do List<Student> stus=new ArrayList<Student>(); stus.a ...
- DAG上的动态规划之嵌套矩形
题意描述:有n个矩形,每个矩形可以用两个整数a.b描述,表示它的长和宽, 矩形(a,b)可以嵌套在矩形(c,d)当且仅当a<c且b<d, 要求选出尽量多的矩形排成一排,使得除了最后一个外, ...
- 全排列 Permutations
class Solution { public: vector<vector<int>> permute(vector<int>& nums) { sort ...