智能 Request 推荐,K8s 资源利用率提升 252%
作者
王孝威,FinOps 认证从业者,腾讯云容器服务产品经理,热衷于为客户提供高效的 Kubernetes 使用方式,为客户极致降本增效服务。
余宇飞,FinOps 认证从业者,腾讯云专家工程师,从事云原生可观测性、资源管理、降本增效产品的开发。
资源利用率为何都如此之低?
虽然 Kubernetes 可以有效的提升业务编排能力和资源利用率,但如果没有额外的能力支撑,提升的能力十分有限,根据 TKE 团队之前统计的数据: Kubernetes 降本增效标准指南| 容器化计算资源利用率现象剖析,如下图所示:TKE 节点的资源平均利用率在 14% 左右。
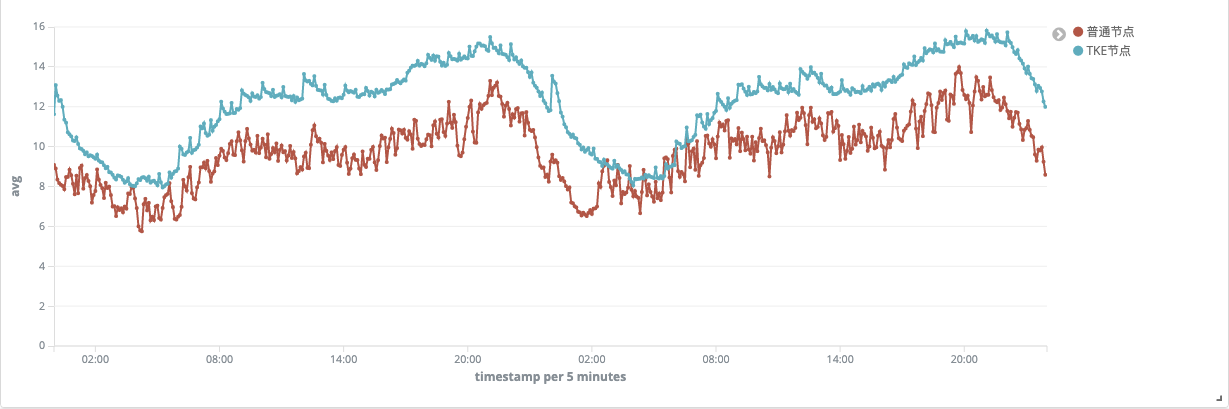
为什么 Kubernetes 集群的资源利用率依旧不高?
这里一个很重要的原因是因为 Kubernetes 的资源调度逻辑,在创建 Kubernetes 工作负载的时候,通常需要为工作负载配置合适的资源 Request 和 Limit,表示对资源的占用和限制,其中对利用率影响最大的是 Request。
为防止自己的工作负载所用的资源被别的工作负载所占用,或者是为了应对高峰流量时的资源消耗诉求,用户一般都习惯将 Request 设置得较大,这样 Request 和实际使用之间的差值,就造成了浪费,而且这个差值的资源,是不能被其它工作负载所使用的。
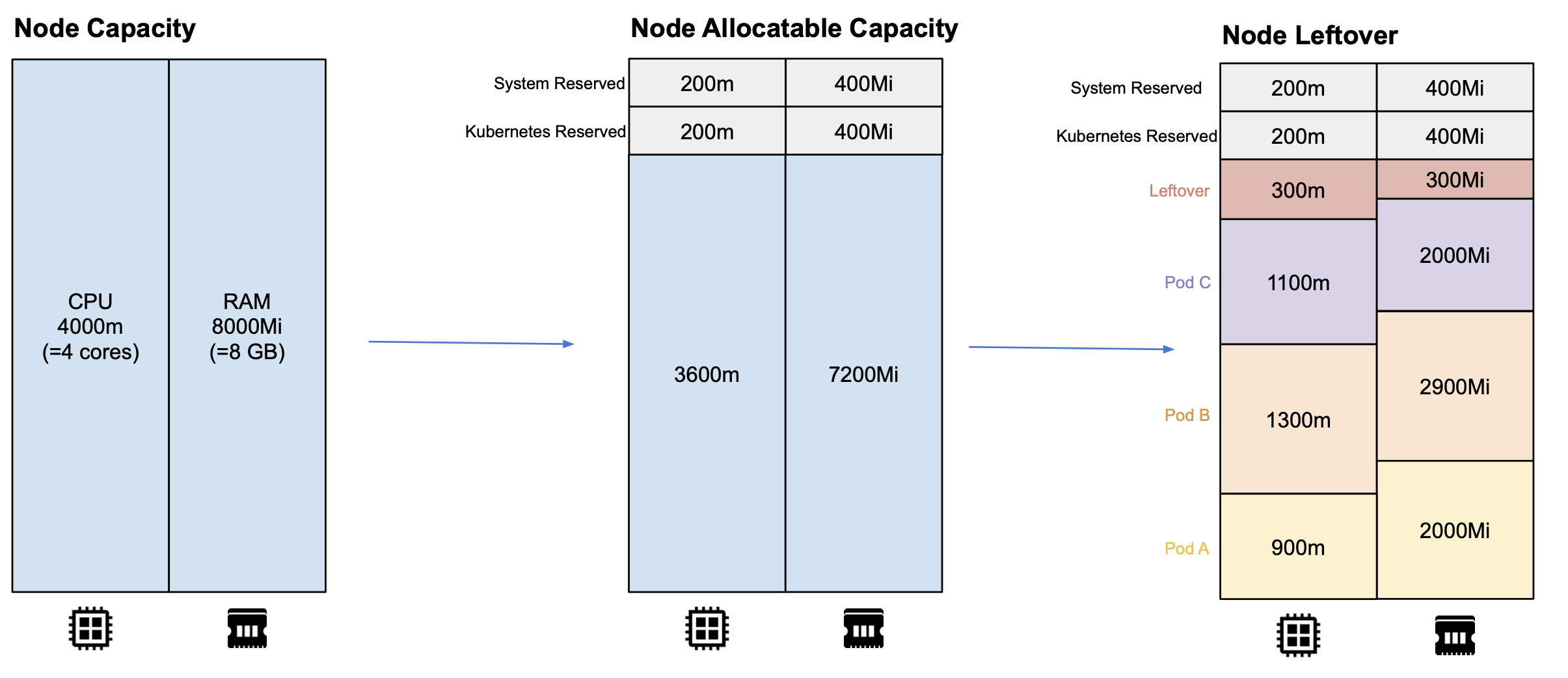
Request 数值不合理的过大,是造成 Kubernetes 集群资源利用率低一个很普遍的现象。另外,每个节点的资源很难被充分分配,如下图所示,节点普遍会存在一些资源的碎片(Leftover),这些都是导致集群整理资源利用率不高的原因。
资源实际利用率到底有多低?
如何设置更合理的资源 Request,首先需要分析业务对资源的消耗情况。在腾讯云原生 Kubernetes 降本增效标准指南| 资源利用率提升工具大全资源常见浪费场景部分,有对单一的工作负载进行分析,工作负载设置的 Request 中至少有一半的资源没有被使用,而且这部分资源不能被其他的工作负载使用,浪费现象严重。 这时把视角上升到集群维度,下图是某一 TKE 集群的 CPU 分配率和使用率。
分配率是用所有容器对 CPU 的 Request 之和除以集群所有节点的 CPU 数量,使用率是所有容器对 CPU 的 Usage 之和除以集群所有节点的 CPU 数量:
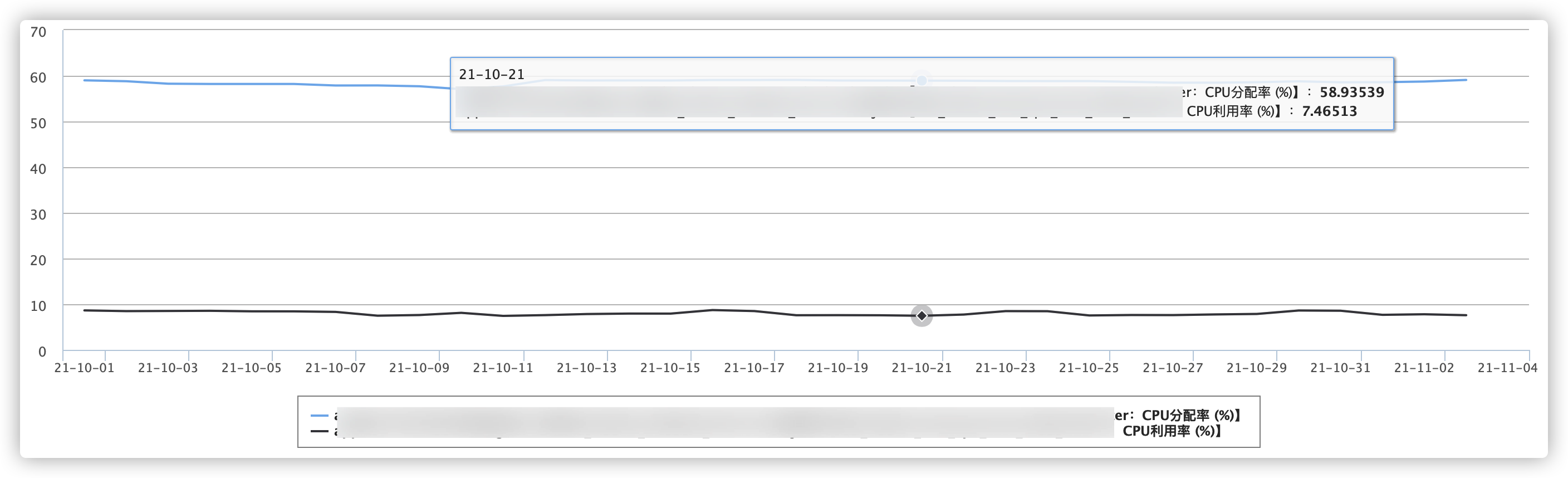
可见集群整体的 CPU 分配率在60%左右,但 CPU 实际的利用率最高不超过 10%。可以理解成用户在云上花了一百元,实际上 90多元都被浪费掉了。
如何设置 Request?
提升资源利用率有很多种方法,详见 Kubernetes 降本增效标准指南| 资源利用率提升工具大全。本文主要探讨 Request 的设置。
既然设置了 Request 导致资源利用率如此之低,那是不是干脆不要设置 Request了,然后直接把集群的规模缩减到原来的十分之一,就可以解决上图中的问题?这确实看似是一种简单高效的方法,但存在几个较为严重的问题:
- Kubernetes 会自动配置 Pod 的服务质量 QoS,对于没有设置 Request 数值的 Pod,当资源比较紧张时,比较容易被驱逐,业务稳定性受到影响。
- 集群的整理资源实际上并不是一个完整的整体,集群是由很多节点构成的,实际的 CPU 和内存的资源都是节点的属性,每个节点的容量大小有上限,例如64核 CPU,对于比较大的业务来说,可能需要一个数千核乃至数万核的集群,这样集群里的节点数量就会变多,节点数量越多,每个节点的碎片资源越多,碎片资源都无法有效被利用。
- 业务本身可能会有较大波动,例如地铁系统白天繁忙、夜晚空闲,设置固定的 Request 数值必须按照峰值考虑,此时浪费现象依旧突出。
可以看出,Request 的设置对于运维开发来说一直是个很大难题,Request 设置过小容易导致业务运行时性能受到影响,设置过大势必造成浪费。
Request 智能推荐
是否存在一个有效的工具,能基于业务本身的特性自动推荐甚至设置 Request 数值?
这样无疑对开发运维来说极大的减轻了负担。为解决这样的问题,TKE 成本大师推出了 Request 智能推荐的工具。用户可以通过标准 Kubernetes API(例如:/apis/recommendation.tke.io/v1beta1/namespaces/kube-system/daemonsets/kube-proxy)访问相应的推荐值。
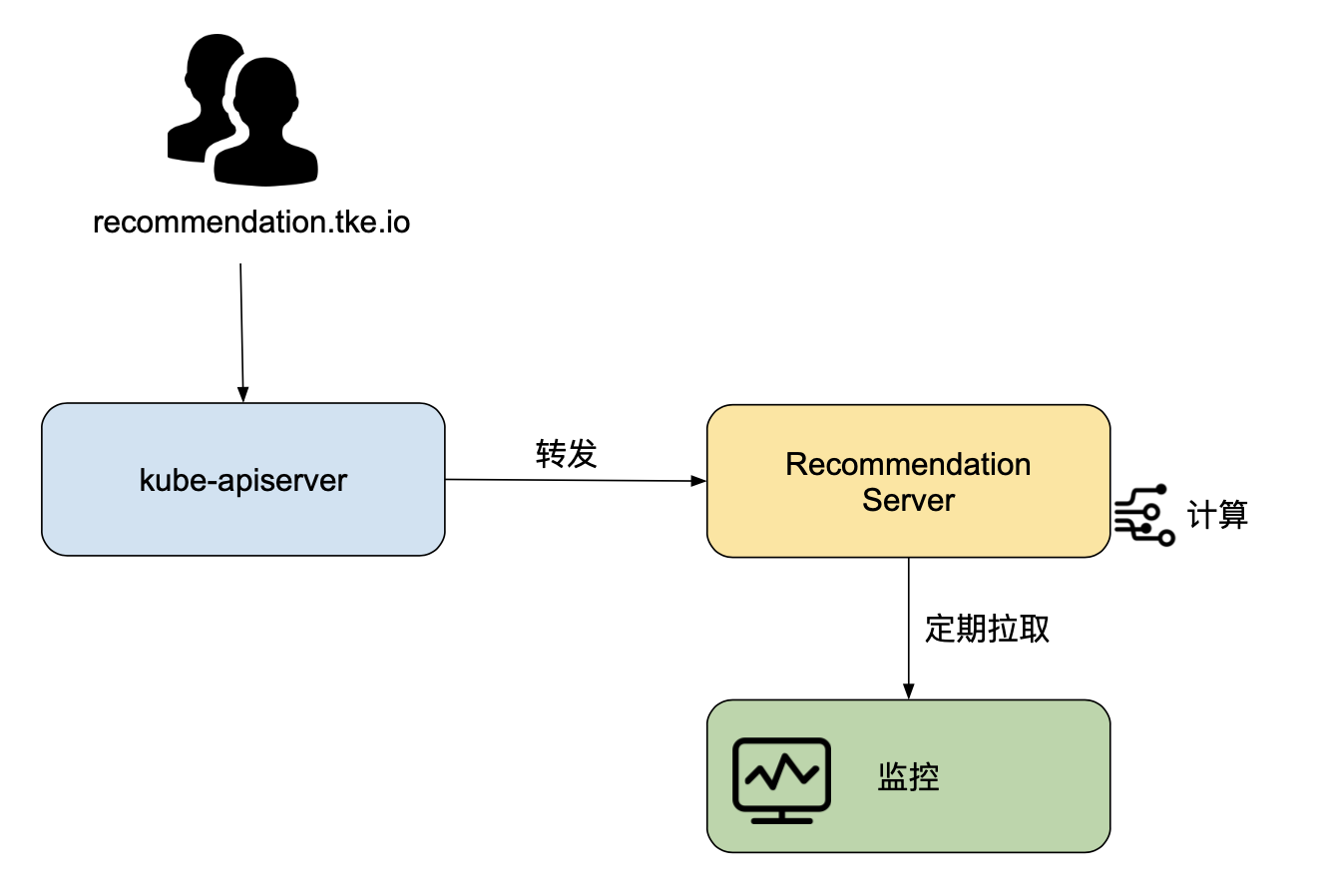
该功能启动后,Request 智能推荐的相关组件会从腾讯云监控(未来支持 Prometheus,InfluxDB,或第三方云厂商)拉取集群中所有 Deployment、DaemonSet、StatefulSet 在过去一段时间存在过的容器的 CPU 和 内存的监控指标,计算相应的 P99 值,再乘以一个安全系数(例如:1.15),当作推荐的 Request。

关于 Limit,Request 智能推荐功能推荐的 Limit ,以初始 Request 智能推荐功能设置的 Request 与 Limit 之比计算。例如初始设置的 CPU 的 Request 数值为 1000m,Limit 为 2000m,Request 与 Limit 之比为 1:2。若新推荐的 CPU 的 Request 数值为 500m,则会推荐 Limit 为 1000m。
更多关于 Request 智能推荐的使用请参考:Request 智能推荐产品文档。
Request 推荐参考应用的历史资源消耗峰值,给出一个相对「合理」并且「安全」的资源请求值,可以很大程度上缓解由于业务 Request 设置不合理导致的资源浪费或者业务不稳定。
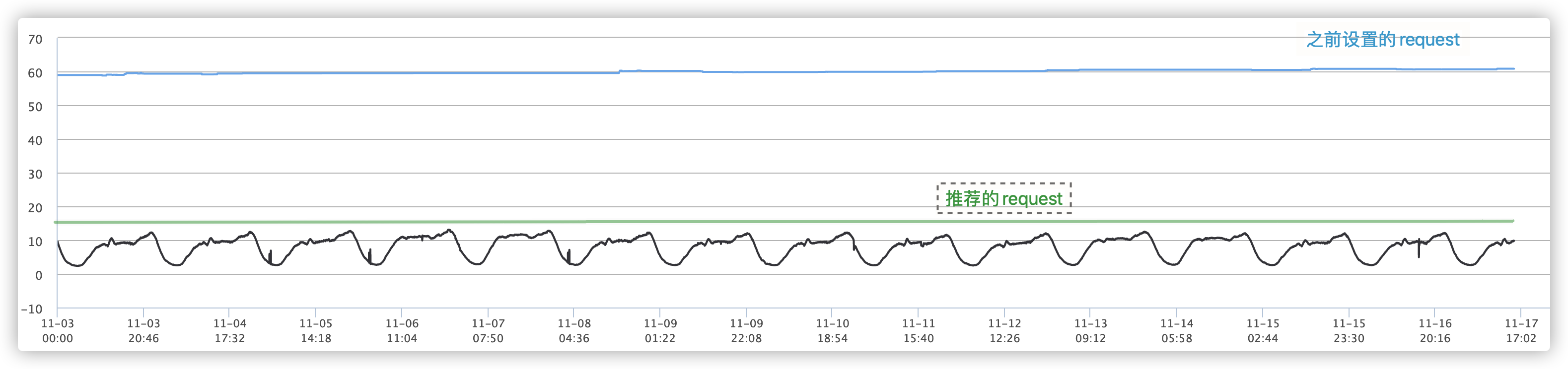
例如在下面的集群中应用 Request 推荐,业务资源使用量在 10 核左右,但手工配置的 Request 是 60 核,实际上 Request 设置在 17 核就足够了,利用率从之前的 16.7%(=10/60) 左右 提升到 58.8%(=10/17),提升了 252%(=(58.8-16.7)/16.7),CPU 节省了 71.7%(=(60-17)/60)。
AHPA
当然 ,Request 智能推荐不是银弹,因为应用的资源消耗并不是一成不变的,大量的应用都存在潮汐现象,业务高峰和低谷所需要的资源存在着几倍甚至几十倍的差距。以高峰期资源需求为准设置的 Request,使得业务在空闲时段占有大量并不使用的资源,导致应用的平均资源利用率依然不高。此时,想要做进一步优化,就需要借助弹性伸缩的手段。
现阶段,HPA 是 Kubernetes 领域最常用的弹性工具,虽然 HPA 可以一定程度上解决周期性业务流量资源使用弹性的问题,但是 HPA 是有滞后性的。具体表现在:通常 HPA 需要先定义监控的指标,例如 CPU 利用率 60%,然后相关的监控组件监控到负载压力变大,触达了这个使用率的阈值,HPA 才会扩缩容副本数。
通过对大量运行在腾讯云上的内部和外部用户的实际应用的观察,我们发现许多业务的资源使用在时间序列上是具有周期性的,特别是对于那些直接或间接为“人”服务的业务。这种周期是由人们日常活动的规律性决定的。例如:
- 人们习惯于中午和晚上点外卖
- 早上和晚上是交通高峰期
- 即使对于没有明显模式的服务,如搜索,夜间的请求量也远低于白天
对于与此类相关的应用程序,从过去几天的历史数据中推断第二天的指标,或从上周一的数据推断下周一的访问流量是一个自然的想法。通过对未来的指标预测,可以更好地管理应用程序实例,稳定系统,同时降低成本。
CRANE 是 TKE 成本大师的技术底座,专注于通过多种技术,优化资源利用,进而降低用户的云上成本。 CRANE 中的 Predictor 模块可以自动识别出 Kubernetes 集群中应用的各种监控指标(例如 CPU 负载、内存占用、请求 QPS 等)的周期性,并给出未来一段时间的预测序列。在此基础上,我们开发了 AHPA(advanced-horizontal-pod-autoscaler),它能够识别适合水平自动缩放的应用程序,制定缩放计划,并自动进行缩放操作。它利用了原生 HPA 机制,但它基于预测,并主动提前扩容应用程序,而不是被动地对监测指标做出反应。与原生 HPA 相比,AHPA 消除了手动配置和自动缩放滞后的问题,彻底解放运维。 主要有如下特点:
- 可靠性—-保证可伸缩性和可用性
- 响应能力——扩展快,快速应对高负载
- 资源效能——降低成本
下图是该项目的实际运行效果:

- 红线是工作负载的实际资源使用量
- 绿线是预测该工作负载的资源使用量
- 蓝线是给出的弹性推荐的资源使用量
CRANE 和 AHPA 即将开源,敬请期待。
更多关于云原生的成本优化原理和实际案例可参考《降本之源-云原生成本管理白皮书》,是腾讯基于内外云原生成本管理最佳实践,并结合行业优秀案例,提出的一套体系化的云原生成本优化方法论和最佳实践路径。旨在帮助企业改善用云成本,充分发挥云原生的效能和价值。

更多白皮书细节内容,在【腾讯云原生】公众号回复“白皮书”下载了解。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

智能 Request 推荐,K8s 资源利用率提升 252%的更多相关文章
- kubernetes 降本增效标准指南| 资源利用率提升工具大全
背景 公有云的发展为业务的稳定性.可拓展性.便利性带来了极大帮助.这种用租代替买.并且提供完善的技术支持和保障的服务,理应为业务带来降本增效的效果.但实际上业务上云并不意味着成本一定较少,还需适配云上 ...
- kubernetes 降本增效标准指南| 容器化计算资源利用率现象剖析
作者:詹雪娇,腾讯云容器产品经理,目前主要负责腾讯云集群运维中心的产品工作. 张鹏,腾讯云容器产品工程师,拥有多年云原生项目开发落地经验.目前主要负责腾讯云TKE集群和运维中心开发工作. 引言 降本增 ...
- 作业帮上万个 CronJob 和在线业务混部,如何解决弱隔离问题并进一步提升资源利用率?
作者 吕亚霖,作业帮基础架构 - 架构研发团队负责人.负责技术中台和基础架构工作.在作业帮期间主导了云原生架构演进.推动实施容器化改造.服务治理.GO 微服务框架.DevOps 的落地实践. 别路,作 ...
- 提升资源利用率的MapReduce框架
Hadoop系统提供了MapReduce计算框架的开源实现,像Yahoo!.Facebook.淘宝.中移动.百度.腾讯等公司都在借助 Hadoop进行海量数据处理.Hadoop系统性能不仅取决于任务调 ...
- 如何提升集群资源利用率? 阿里容器调度系统Sigma 深入解析
阿里妹导读:为了保证系统的在线交易服务顺利运转,最初几年,阿里都是在双11大促来临之前大量采购机器储备计算资源,导致了双11之后资源大量闲置点现象.是否能把计算任务与在线服务进行混合部署,在现有弹性资 ...
- 成本降低40%、资源利用率提高20%的 AI 应用产品云原生容器化之路
作者 郭云龙,腾讯云高级工程师,目前就职于 CSIG 云产品三部-AI 应用产品中心,现负责中心后台业务框架开发. 导语 为了满足 AI 能力在公有云 SaaS 场景下,服务和模型需要快速迭代交付的需 ...
- k8s资源清单基础
资源清单介绍 创建资源的方法 apiserver仅接收JSON格式的资源定义 yaml格式提供配置清单 apiserver可自动把yaml转换成json格式数据 资源清单五个一级字段 1.ap ...
- Linux下资源利用率监测利器—nmon使用
最近接了一个任务,就是测试公司服务器的资源利用率,这样对每种业务平时所占资源有了大体的了解,进而为下一步的虚拟化做准备.找了很多开源的工具,但都不理想,有的安装很复杂,需要联网(而我们的服务器很多都不 ...
- 使用 Ansible 统计服务器资源利用率
使用 Ansible 统计服务器资源利用率: 3 条 shell 脚本实现统计: CPU 利用率统计: top -bn1 | grep load | awk '{printf "CPU Lo ...
随机推荐
- 洛谷4360[CEOI2004]锯木厂选址 (斜率优化+dp)
qwq 我感觉这都已经不算是斜率优化\(dp\)了,感觉更像是qwq一个\(下凸壳优化\)转移递推式子. qwq 首先我们先定义几个数组 \(sw[i]\)表示\(w[i]\)的前缀和 \(val[i ...
- Vulnhub实战-Dockhole_2靶机👻
Vulnhub实战-Dockhole_2靶机 靶机地址:https://www.vulnhub.com/entry/darkhole-2,740/ 1.描述 hint:让我们不要浪费时间在蛮力上面! ...
- 消息队列那么多,为什么建议深入了解下RabbitMQ?
你为啥要在项目中选择xxx消息中间件? 提起消息队列,也许你的脑海里会不自觉地蹦出好多概念:JMS.Kafka.RocketMQ.AMQP.RabbitMQ.ActiveMQ.Pulsar.Redis ...
- ES2020新特性记录
1.可选链操作符 // oldlet ret = obj && obj.first && obj.first.second// newlet ret = obj?.fi ...
- javascript的变量及数据类型
1.变量的概念 变量是储存数据的内存空间 2.变量的命名规则 js变量的命名规则如下:以字母或者下划线开头可以包含字母.数字.下划线,不能包含特殊字符 3.变量的创建及初始化方法 方法一:先创建后使用 ...
- 【UE4 C++】打印字符串与输出日志
打印屏幕 默认打印屏幕 // 打印至屏幕 FString screenMessage = "(AddOnScreenDebugMessage) Hello world!"; GEn ...
- Redis:学习笔记-02
Redis:学习笔记-02 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 4. 事物 Redis 事务本 ...
- [no code][scrum meeting] Alpha 14
项目 内容 会议时间 2020-04-22 会议主题 周中讨论会议 会议时长 45min 参会人员 全体成员 $( "#cnblogs_post_body" ).catalog() ...
- the Agiles Scrum Meeting 3
会议时间:2020.4.11 21:30 1.每个人的工作 今天已完成的工作 yjy:基本实现广播功能的前端 issues:小组任务1-增量开发组 wjx:基本实现注销功能的后端 issues:小组任 ...
- [BUAA]起点 软工第一次作业-热身
项目 内容 这个作业属于哪个课程 2020计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 第一次作业-热身! 我在这个课程的目标是 了解软件开发,提高自己的工程能力和团队协作能力 这个作业在哪 ...