vivo数据库与存储平台的建设和探索
本文根据Xiao Bo老师在“2021 vivo开发者大会"现场演讲内容整理而成。公众号回复【2021VDC】获取互联网技术分会场议题相关资料。
一、数据库与存储平台建设背景

以史为鉴,可以知兴替,做技术亦是如此,在介绍平台之前,我们首先来一起回顾下vivo互联网业务近几年的发展历程。
我们将时间拨回到三年前来看看 vivo 互联网产品近几年的发展状况,2018年11月,vivo移动互联网累计总用户突破2.2亿;2019年应用商店、浏览器、视频、钱包等互联网应用日活突破千万大关;2020年浏览器日活突破1亿,2021年在网总用户(不含外销)达到2.7亿,数十款月活过亿的应用,数据库和存储产品的也达到了4000+服务器和5万+数据库实例的规模。
那三年前的数据库和存储平台是什么样呢?

2018年的数据库服务现状如果用一个词形容,那我觉得“危如累卵”最适合不过了,主要表现为以下几点;
数据库线上环境的可用性由于低效的SQL、人为的误操作,基础架构的不合理,开源产品的健壮性等问题导致可用性经常受到影响。
变更不规范,变更和各种运维操作的效率低下,没有平台支撑,使用命令行终端进行变更。
数据库使用的成本极高,为了应对日益复杂的业务场景,增加了很多额外的成本。这些就是2018年当时vivo的数据库现状。
安全能力不够健全,数据分类分级、密码账号权限等缺乏规范。
我们再看看这些年vivo数据库一些运营数据上的变化趋势。
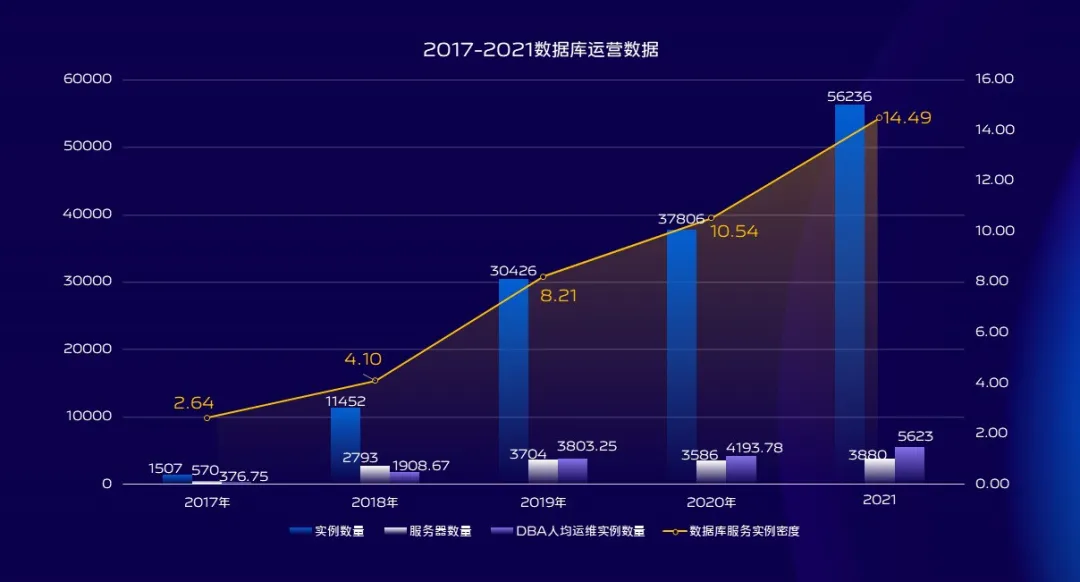
从17年底,18年初开始计算,这三年时间里面数据库实例的规模增加了接近5倍,所维护的数据库服务器规模增加了6.8倍,数据库实例的单机部署密度增加了5倍以上,DBA人均运维的数据库实例规模增加了14.9倍。
通过以上这些数字,我们发现近几年vivo互联网业务其实是处于高速发展的状态,在高速发展的过程中无论是从用户感受到的服务质量上来看还是从内部的成本效率来看,解决数据存储的问题是迫在眉睫的事情,于是我们在2018年启动了自研数据库与存储平台的计划,通过几年时间的建设,我们初步具备了一些能力,现在就这些能力给大家做下简单的介绍。
二、数据库与存储平台能力建设

首先来整体对数据库与存储平台产品做下介绍,主要分为2层。
第一层我们的数据库和存储产品,包括关系型数据,非关系型数据库,存储服务三大块。
第二层主要是工具产品,包括提供数据库和存储统一管控的研发和运维平台,数据传输服务,运维白屏化工具,还有一些SQL审核,SQL优化,数据备份等产品。
工具产品主要以自研为主,下面一层的数据库和存储产品我们会优先选用成熟的开源产品,同时也会在开源产品的基础上或者纯自研一些产品用来更好的满足业务发展,下面就部分产品的能力做下简单的介绍。

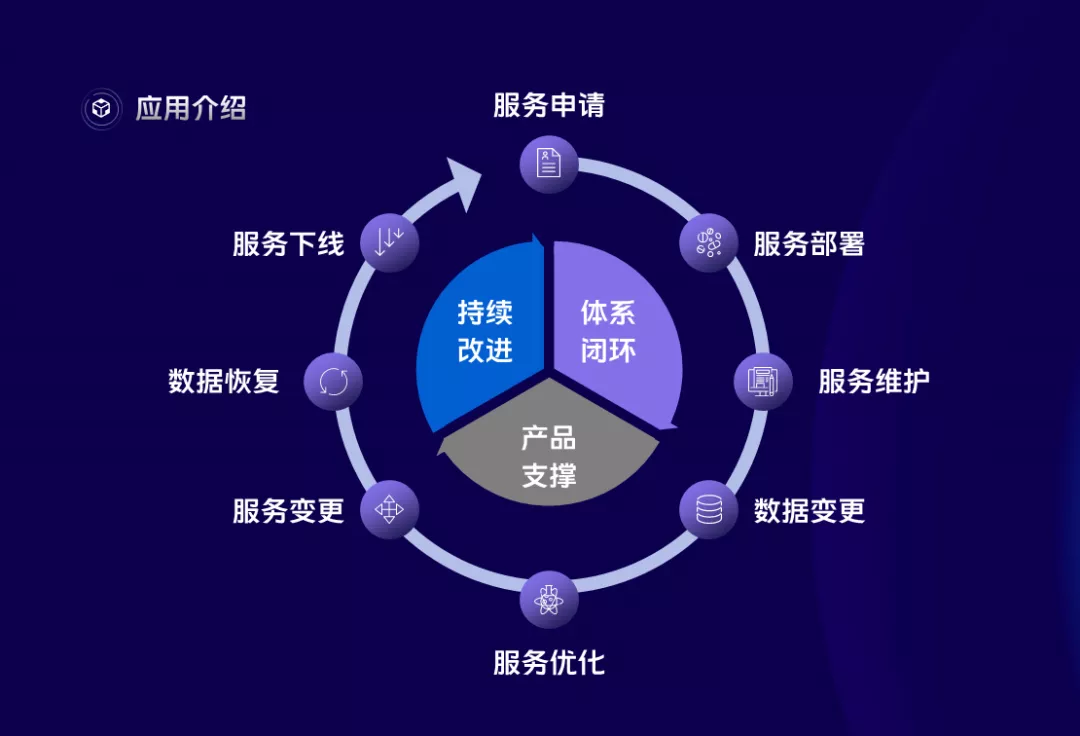
DaaS平台是Database as a Service的缩写,该平台旨在提供高度自助化、高度智能化、高可用、低成本的数据存储使用和管理的平台,涵盖了数据库和存储产品从服务申请、部署、维护直至下线的全生命周期,主要从四个方面为公司和用户提供价值。
第一是提升数据库产品的可用性,通过巡检、监控、预案、故障跟踪等对故障进行事前防范、事中及时处理、事后复盘总结进行全流程闭环。
第二是提升研发效能,研发自助使用数据库,提供变更检测、优化诊断等功能,减少人工沟通流程,项目变更规范流程清晰,提升研发效率。
第三是提升数据安全性,通过权限管控、密码管控、数据加密、数据脱敏、操作审计、备份加密等一系列手段全方位的保障数据安全性。
第四是降低数据库和存储产品的运营成本,首先通过自动化的流程减少DBA的重复工作,提高人效,其次通过服务编排和资源调度,提升数据库和存储服务的资源使用效率,持续降低运营成本。
通过几年时间的建设,以上工作取得了一些进展,其中每月数以千计的需求工单,其中90%以上研发同学可以自助完成,服务可用性最近几年都维持在4个9以上,平台对6种数据库产品和存储服务的平台化支持达到了85%以上,而且做到了同一能力的全数据库场景覆盖,比如数据变更,我们支持MySQL、ElastiSearch、MongoDB、TiDB的变更前语句审查,变更数据备份,变更操作一键回滚,变更记录审计追踪等。

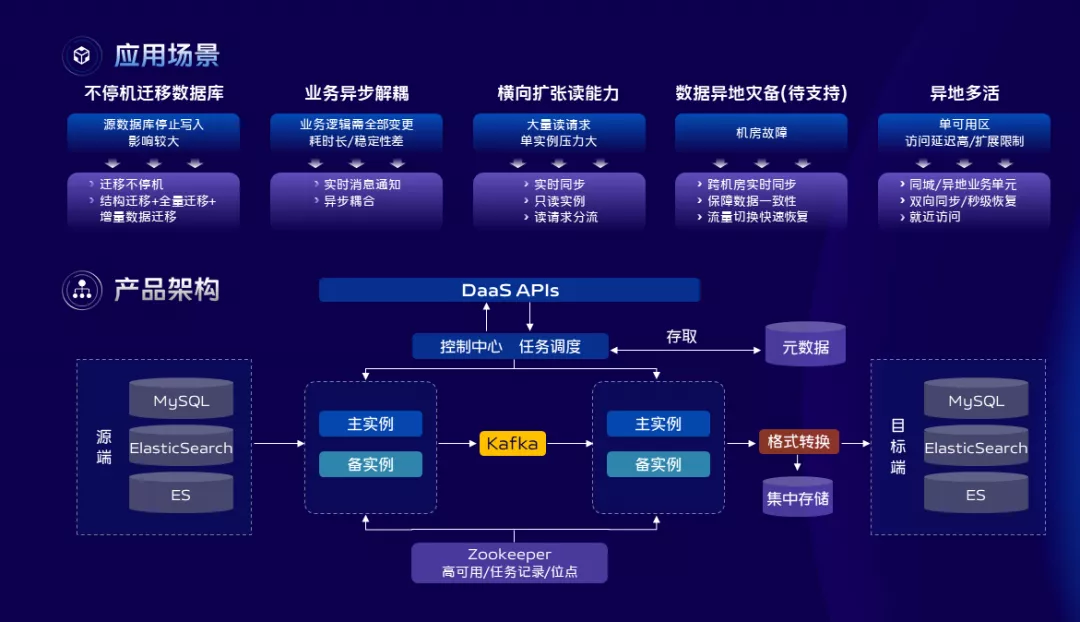
vivo的DTS服务是基于自身业务需求完全自研的数据传输服务,主要提供RDBMS、NoSQL、OLAP等数据源之间的数据交互。集数据迁移、订阅、同步、备份的一体化服务,从功能上来看,主要有三个特性;
第一是同步链路的稳定性和数据可靠性保障,通过结合各个数据源产品的自身特性可以做到数据不重不丢,给业务提供99.99%的服务可用性保障。
第二是功能层面支持异构的多种数据库类型,除了同步、迁移、订阅等这些通用功能外,我们还支持变更数据的集中化存储和检索。
第三是故障容灾层面,支持节点级别故障容灾,可以做到同步链路秒级恢复,也支持断点续传,可以有效的解决因硬件、网络等异常导致的传输中断问题。
下面我们再来看看我们在底层数据存储层做的一些项目,首先来看看MySQL数据库。

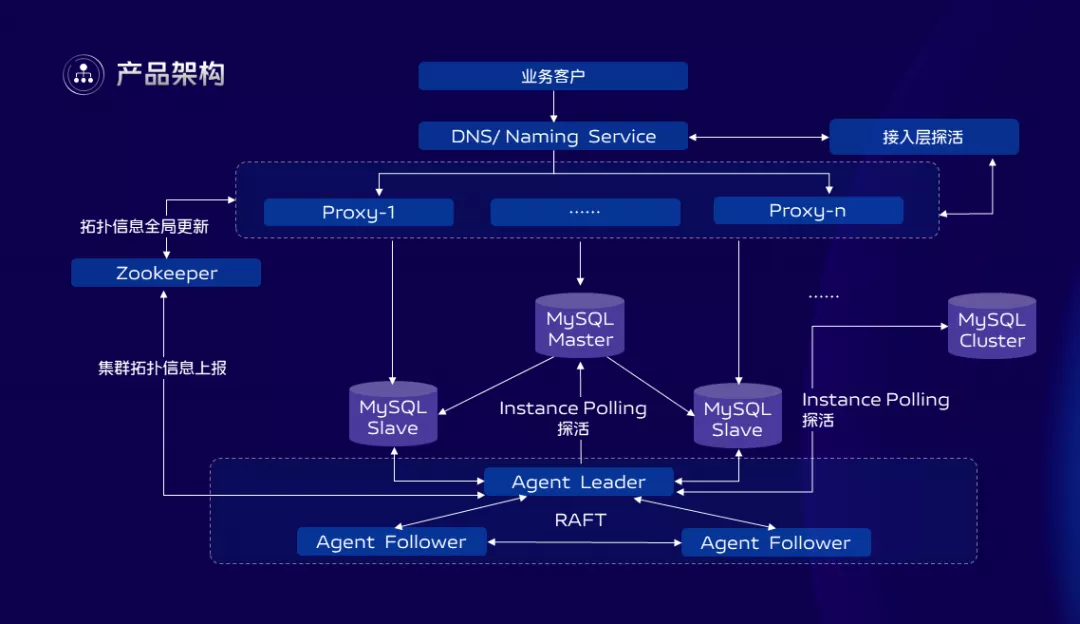
MySQL作为最流行的数据库,在vivo同样承担了关系型数据库服务的重任,上图的MySQL2.0是我们内部的架构版本,在这几年时间里面,我们的架构演化了2版。
第一版为了快速解决当时面临的可用性问题,基于MHA+自研组件做了1.0版本。
目前已经演化到了2.0版本,MHA等组件依赖已经没有了,从架构上看,2.0版本的服务接入层我们支持业务使用DNS或者名字服务接入,中间加入了一层自研的代理层Proxy,这一层做到了100%与MySQL语法和协议兼容,在Proxy上面我们又实现了三级读写分离控制,流量管控,数据透明加密,SQL防火墙,日志审计等功能。
Proxy层结合底层的高可用组件共同实现了MySQL集群的自动化、手动故障转移,通过RAFT机制保障了高可用管控组件自身的可用性,当然MySQL用的还是主从架构,在同地域可以跨IDC部署,跨地域同步可以用前面提到的DTS产品解决,跨地域多活目前还未支持,这块属于规划中的3.0架构。


Redis作为非常流行和优秀的KV存储服务,在vivo得到了大量的应用,在vivo互联网的发展历程中,有使用过单机版的Redis,也有使用过主从版本的Redis。到目前为止,已经全部升级到集群模式,集群模式的自动故障转移,弹性伸缩等特性帮我们解决了不少问题。
但当单集群规模扩大到TB级别和单集群节点数扩展到500+以后还是存在很多问题,基于解决这些问题的诉求,我们在Redis上面做了一些改造开发,主要包括三部份:
第一是Redis Cluster的多机房可用性问题,为此我们研发了基于Redis Cluster的多活版本Redis。
第二是对Redis的数据持久化做了加强,包括AOF日志改造,AEP硬件的引入,包括正在规划中的Forkless RDB等。
第三是Redis同步和集群模式的增强,包括异步复制,文件缓存,水位控制等,还有对Redis Cluster指令的时间复杂度优化,Redis Cluster指令的时间复杂度曾经给我们的运维带来了很多的困扰,通过算法的优化,时间复杂度降低了很多,这块的代码目前已经同步给社区。
我们在Redis上做了这些优化后,发现仅仅有内存型的KV存储是无法满足业务需要,未来还有更大的存储规模需求,必须有基于磁盘的KV存储产品来进行数据分流,对数据进行分层存储,为此我们研发了磁盘KV存储产品。

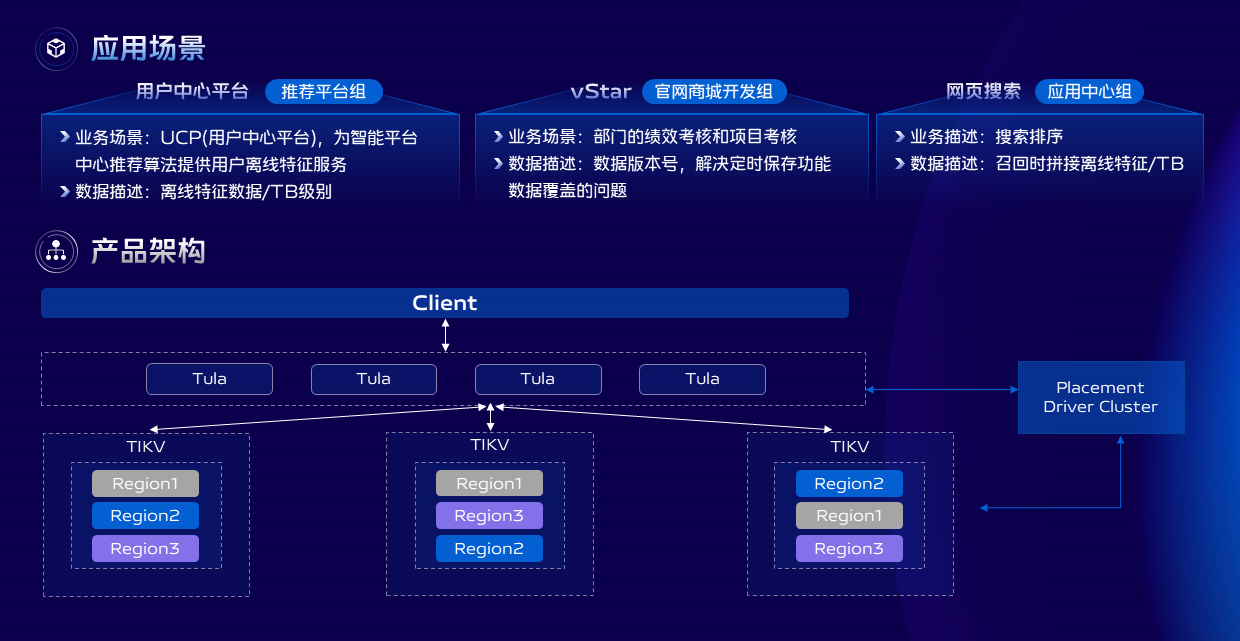
我们在启动磁盘KV存储服务研发项目时就明确了业务对存储的基本诉求。
第一是是兼容Redis协议,可以很方便的从原来使用Redis服务的项目中切换过来。
第二是存储成本要低,存储空间要大,性能要高,结合运维的一些基本诉求比如故障自动转移,能够快速的扩缩容等。
最终我们选择了以TIKV作为底层存储引擎实现的磁盘KV存储服务,我们在上层封装了Redis指令和Redis协议。其中选择TIKV还有一个原因是我们整体的存储产品体系中有使用到TiDB产品,这样可以降低运维人员学习成本,能够快速上手。
我们还开发了一系列周边工具,比如Bulk load批量导入工具,支持从大数据生态中导入数据到磁盘KV存储,数据备份还原工具,Redis到磁盘KV同步工具等,这些工具大大的降低了业务的迁移成本,目前我们的磁盘KV存储产品已经在内部广泛使用,支撑了多个TB级别的存储场景。

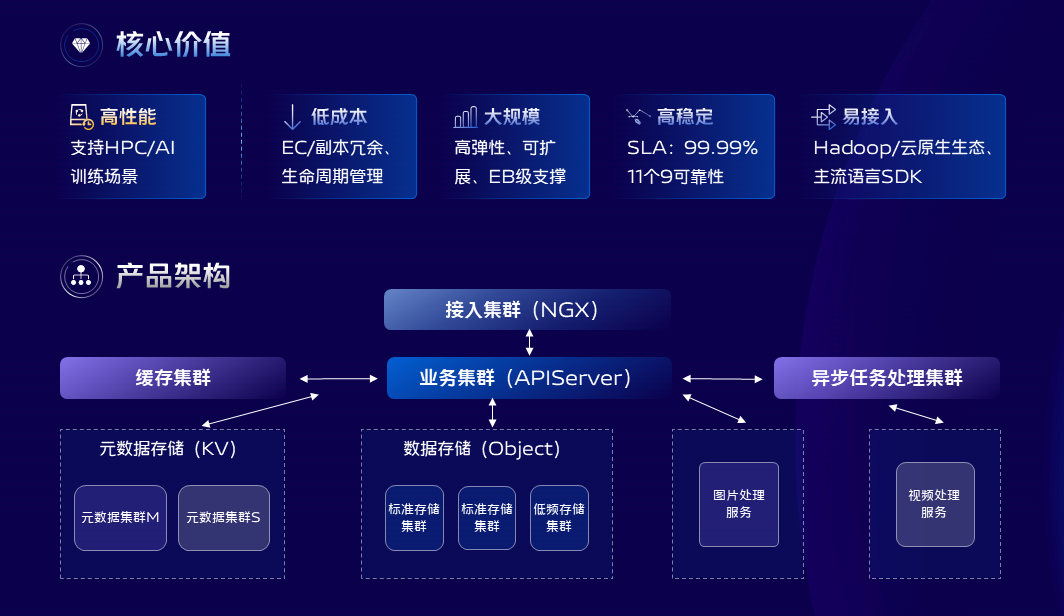
我们知道业务运行过程中除了需要对一些结构化或者半结构化的数据有存取需求之外,还有大量的非结构化数据存取需求。vivo的对象与文件存储服务正是在这样的背景下去建设的。
对象和文件存储服务使用统一的存储底座,存储空间可以扩展到EB级别以上,上层对外暴露的有标准对象存储协议和POSIX文件协议,业务可以使用对象存储协议存取文件、图片、视频、软件包等,标准的POSIX文件协议可以使得业务像使用本地文件系统一样扩展自己的存取需求,比如HPC和AI训练场景,可以支撑百亿级别小文件的GPU模型训练。
针对图片和视频文件,还扩展了一些常用的图片和视频处理能力,比如水印,缩略图、裁剪、截祯、转码等。前面简单介绍了vivo数据库与存储平台的一些产品能力,那么下面我们再来聊聊在平台建设过程中,我们对一些技术方向的探索和思考。
三、数据库与存储技术探索和思考


在平台建设方面,运维研发效率提升是老生常谈的话题,在业内也有很多建设得不错的平台和产品,但是关于数据存储这块怎么提升运维研发效率讲的比较少。
我们的理解是:
首先是资源的交付要足够的敏捷,要屏蔽足够多的底层技术细节,为此我们将IDC自建数据库、云数据库、云主机自建数据库进行云上云下统一管理,提供统一的操作视图,降低运维和研发的使用成本。
其次要提升效率就不能只关注生产环境,需要有有效的手段将研发、测试、预发、生产等多种环境统一管控起来,做到体验统一,数据和权限安全隔离。
最后是我们运用DevOps解决方案的思想,将整个平台逻辑上分为两个域,一个是研发域,一个是运维域:
在研发域,我们需要思考如何解决研发同学关于数据库和存储产品的效率问题。交付一个数据库实例和支持他们在平台上可以建库建表是远远不够的,很多操作是发生在编码过程中的,比如构造测试数据,编写增删改查的逻辑代码等等。
我们希望在这些过程中就和我们的平台发生交互,最大程度的提升研发效率。
在运维域,我们认为目前有一个比较好的衡量指标就是日常运维过程中需要登录服务器操作的次数,将运维的动作全部标准化、自动化,并且未来有一些操作可以智能化。在研发和运维交互的部分,我们的建设目标是减少交互,流程中参与的人越少效率就越高,让系统来做决策,实现的方案是做自助化。下面我们在看看安全这块的一些探索和思考。

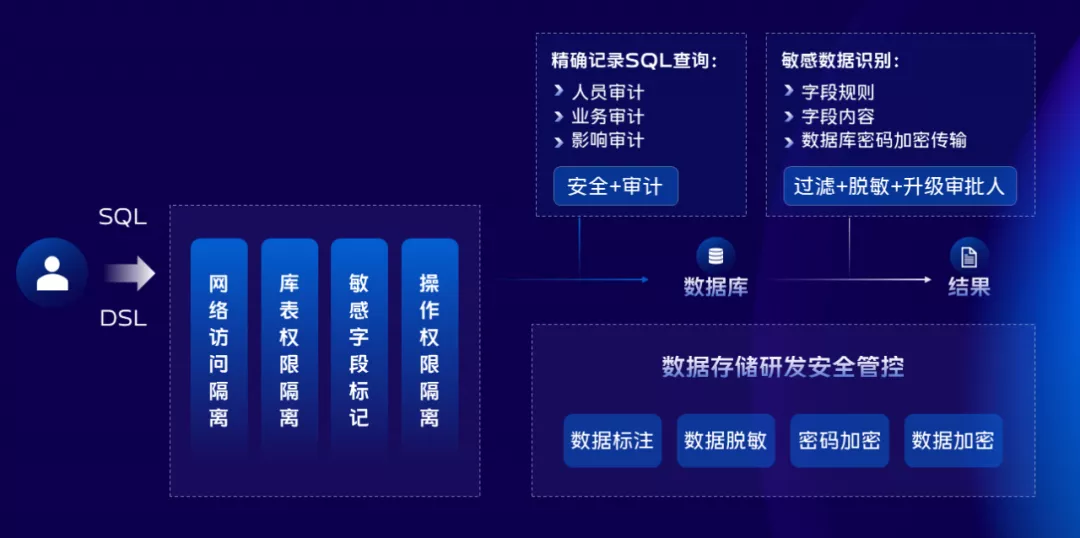
安全无小事,为此我们将数据库安全和数据安全的部分单独拿出来进行规划和设计,基本的原则就是权责分明,数据库体系涉及到账号密码等。
我们联合SDK团队共同研发了密码加密传输使用方案,数据库的密码对研发、运维而言都是密文,在项目的配置文件中依然是密文,使用时对接公司的密钥管理系统进行解密。
针对数据的部分,我们联合安全团队对敏感数据做了自动标注识别,分类分级,对敏感数据的查询、导出、变更上做了严格的管控,比如权限管控、权限升级、通过数字水印技术进行使用追踪,通过事后的审计可以追溯到谁在什么时刻查看了什么数据。针对敏感数据我们也做了透明加解密操作,落盘到存储介质的数据是经过加密存储的。
同理,备份的数据和日志也做了加密存储,这些是目前我们做的事情,未来安全这块还有很多的能力需要建设。下面我们再来看看变更这块。

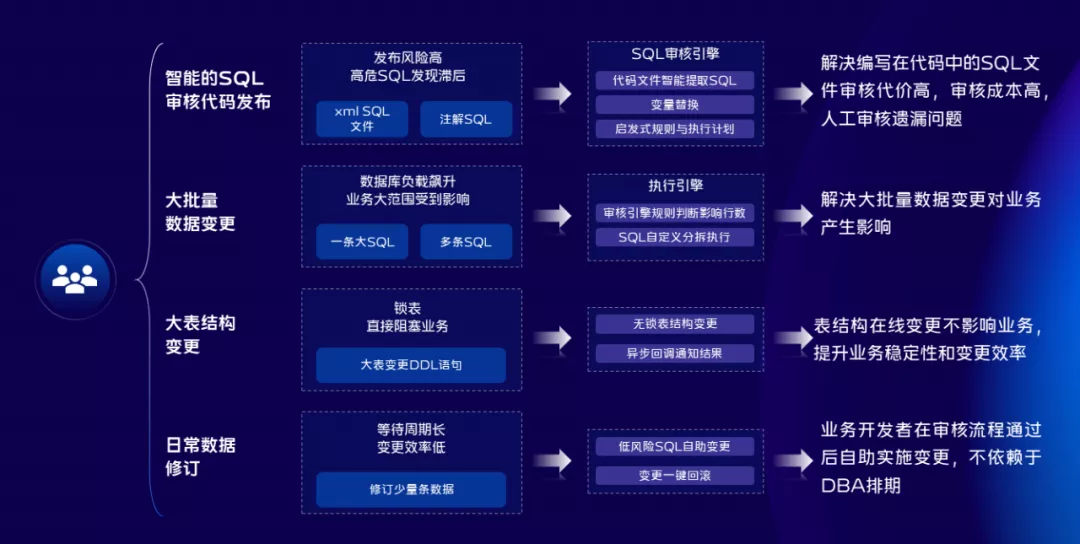
针对数据变更的场景,我们关注的主要有两点;
第一是数据变更本身会不会影响已有的业务,为此我们建设了不锁表结构、不锁表数据的变更能力,针对上线前、上线中、上线后三个环节设置三道防线。杜绝一些不好的SQL或者Query流入到生产环境,针对变更过程中或者变更结束后如果想回滚,我们也做了一键回滚方案。
第二是变更效率问题,针对多个环境、多个集群我们提供了一键同步数据变更方案,同时为了更好的提升用户体验,我们也提供了GUI的库表设计平台。有了这些基础之后,我们将整个场景的能力全部开放给研发同学,现在研发同学可以24小时自助进行数据变更操作,极大的提升了变更效率。
四、探索和思考
接下来我们再介绍下成本这块的一些思考。
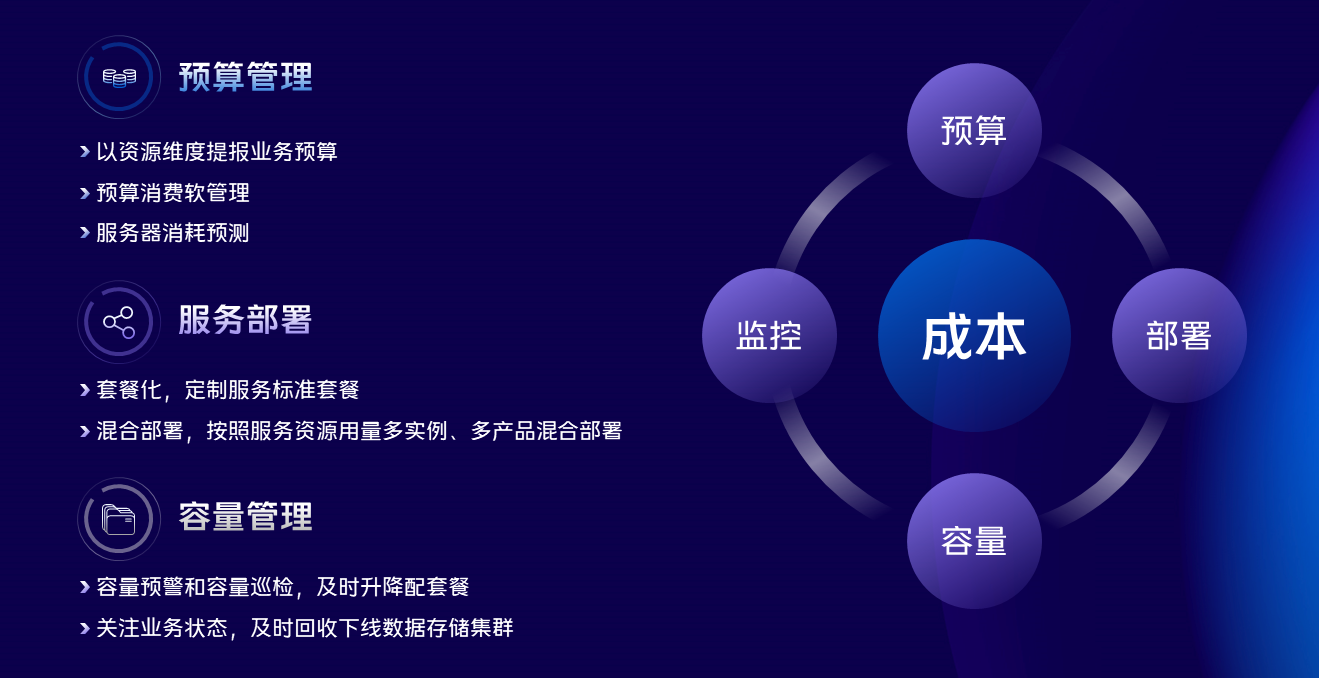
关于成本这块我们主要从四个方面进行管理;
第一是预算的管控,资源去物理化,业务以资源为粒度进行预算提报,在预算管控层面对服务器的消耗进行预测和不断的修正,保证水位的健康。
第二是数据库服务的部署,这块我们经历了几个阶段,最早期是单机单实例,浪费了很多资源,后面发展为标准化套餐部署,同一类型的存储资源不同的套餐混合,通过算法的优化不断的提升资源的使用效率。
第三是我们做了一系列不同属性资源的混合部署,比如数据库的代理层和对象存储的数据节点混合部署,这两种资源一个是CPU型的,一个是存储型的,正好可以互补,再往后发展的下一个阶段应该是云原生存储计算分离,还在探索中。
第四是服务部署之后还需要不断的关注运行中的状况,对容量做巡检和预警,对集群及时的做升降配操作,保障整个运行状态有序。同时需要关注业务运行状态,及时回收下线数据存储集群,减少僵尸集群的存在。
成本这块还有一点就是硬件资源的迭代,这块也很关键,这里就不做过多的介绍。然后我们再来看下存储服务体系这块。

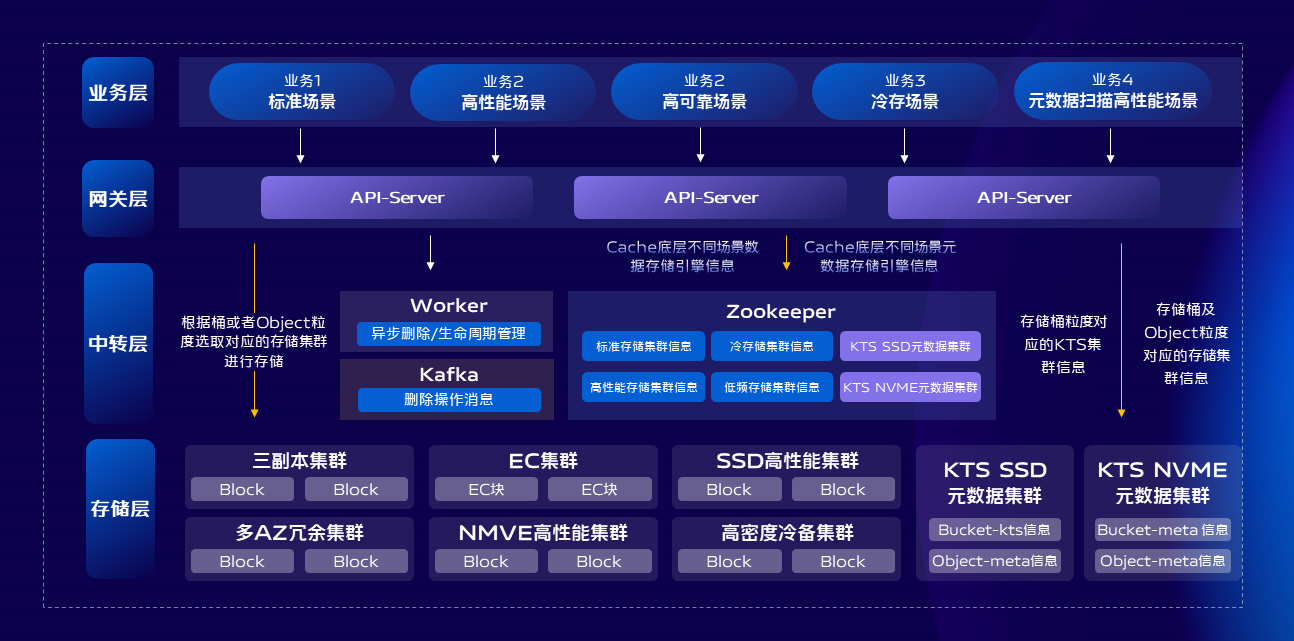
对象与文件存储这块我们主要关注的是两个点;
第一个是成本,关于成本这块我们在数据冗余策略这块使用了EC,并且做了跨IDC的EC,单个IDC全部故障也不会影响我们的数据可靠性。我们还引入了高密度大容量存储服务器,尽可能多的提升单机架存储密度,需要注意的是服务器采购之后的运行成本也不可忽视,依然有很大的优化空间。我们还提供了数据无损和透明压缩的能力和生命周期管理的能力,及时清理过期数据和对冷数据进行归档。通过多种手段持续降低存储成本。
第二是性能,关于性能这块我们提供了桶&对象粒度底层存储引擎IO隔离,通过引入一些开源组件如alluxio等提供了服务端+客户端缓存,提升热点数据读取性能,在底层存储引擎这块我们引入了opencas和IO_URING技术,进一步提升整机的磁盘IO吞吐。
以上就是我们目前在建设的能力的一些探索和思考,最后再来看下我们未来的规划。
五、未来的规划
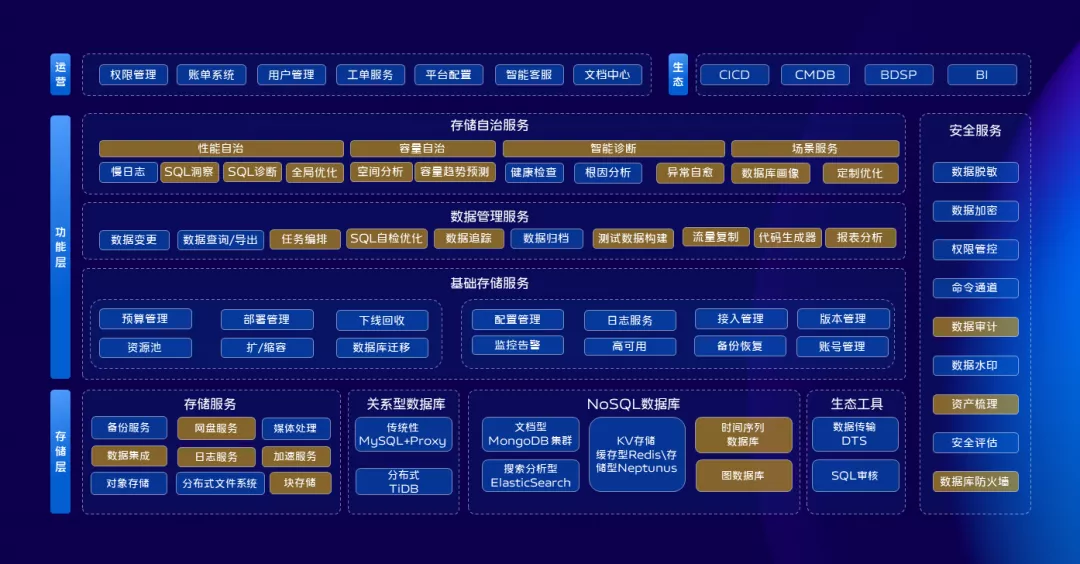
在整个存储服务层,我们会不断的完善存储服务矩阵,打磨产品,提供更多元的存储产品,更好的满足业务发展诉求。同时在存储服务层会基于现有存储产品做一些SAAS服务来满足更多的业务诉求。在功能层,我们拆解为4部分:
数据基础服务,这部分提供存储产品基本功能,包括部署、扩缩容、迁移、监控告警、备份恢复,下线回收等等。
数据服务,存储产品本质上是存储数据的载体,针对数据本身我们也有一些规范,最基本的比如数据的查询变更性能优化,数据治理和如何深入到业务编码过程中去。
存储自治服务,初步划分为性能自治、容量自治、智能诊断、场景服务四大块,通过自治服务一方面可以提升DBA工作的幸福感,一方面也可以大大的提升我们系统本身的健壮性和稳定性。
数据安全服务,目前虽然建设了一些能力,但是不够体系,未来还需要加大投入。
未来整个存储服务体系会融入到公司整体的混合云架构中,给用户提供一站式和标准化的体验。以上就是分享的全部内容。
作者:vivo互联网数据库团队-Xiao Bo
vivo数据库与存储平台的建设和探索的更多相关文章
- vivo互联网机器学习平台的建设与实践
vivo 互联网产品团队 - Wang xiao 随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中.业务的不断增长,模型的训练.产出迫切需要进行平台化管理.vivo互联网机器学习平台主要业务 ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- MySQL更改数据库数据存储目录
MySQL数据库默认的数据库文件位于/var/lib/mysql下,有时候由于存储规划等原因,需要更改MySQL数据库的数据存储目录.下文总结整理了实践过程的操作步骤. 1:确认MySQL数据库存储目 ...
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- SQLite数据库如何存储和读取二进制数据
SQLite数据库如何存储和读取二进制数据 1. 存储二进制数据 SQLite提供的绑定二进制参数接口函数为: int sqlite3_bind_blob(sqlite3_stmt*, int, co ...
- C# 在SQLite数据库中存储图像 z
C# 在SQLite数据库中存储图像 更多 0 C# SQLite 建表语句 CREATE TABLE [ImageStore]([ImageStore_Id] INTEGER NOT NULL ...
- 数据库的存储引擎和SQL语言
数据库的存储引擎就是管理数据存储的东西,它完成下面的工作: 1)存储机制 2)索引方式 3)锁 4)等等 SQL语言:-----关系型数据库所使用的数据管理语言 1)数据定义语言(DDL):DROP. ...
- 数据库中存储日期的字段类型究竟应该用varchar还是datetime ?
背景: 前段时间在百度经验看到一篇文章<如何在电脑右下角显示你(爱人)的名字>,之前也听过这个小技巧,但没真正动手设置过.所以出于好奇就实践了一下. 设置完成后的效果例如以下.右下角的时间 ...
随机推荐
- 手把手教你如何使用 webpack5 的模块联邦新特性
想象一下,在webpack5还没出来前,前端使用第三方组件库,例如使用 dayjs 日期处理库,都是通过 npm i dayjs -s 安装 dayjs 模块到项目里,然后就可以通过 require ...
- 【LeetCode】476. 数字的补数 Number Complement
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 公众号:负雪明烛 本文关键词:Leetcode, 力扣,476, 补数,二进制,Pyth ...
- 【LeetCode】1005. Maximize Sum Of Array After K Negations 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 小根堆 日期 题目地址:https://leetco ...
- 【LeetCode】762. Prime Number of Set Bits in Binary Representation 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历数字+质数判断 日期 题目地址:https:// ...
- 【LeetCode】873. Length of Longest Fibonacci Subsequence 解题报告(Python)
[LeetCode]873. Length of Longest Fibonacci Subsequence 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: ...
- 使用.NET 6开发TodoList应用(10)——实现DELETE请求以及HTTP请求幂等性
系列导航及源代码 使用.NET 6开发TodoList应用文章索引 需求 先说明一下关于原本想要去更新的PATCH请求的文章,从目前试验的情况来看,如果是按照.NET 6的项目结构(即只使用一个Pro ...
- Propensity Scores
目录 基本的概念 重要的结果 应用 Propensity Score Matching Stratification on the Propensity Score Inverse Probabili ...
- An Introduction to Measure Theory and Probability
目录 Chapter 1 Measure spaces Chapter 2 Integration Chapter 3 Spaces of integrable functions Chapter 4 ...
- CS5216|DP1.2转HDMI1.4音视频转换芯片|CS5216参数
Capstone CS5216是一款用于DP1.2转HDMI1.4音视频转换芯片.CS5216是HDMI 电平移位器/中继器专为2型双模Display Port(DP++)电缆适配器应用而设计.它设计 ...
- Linux磁盘实用指令
磁盘情况查询 df/du 查询磁盘整体占用情况 df 指令:df -h 查询目录磁盘占用情况 du 基本语法 指令:du [选项] 指定目录 常用选项 指定目录不填则默认当前目录 选项 功能 -s 指 ...