Redis源码分析(adlist)
源码版本:redis-4.0.1
源码位置:
一、adlist简介
Redis中的链表叫adlist(A generic doubly linked list implementation 一个通用的双端链表实现),和普通单链表相比,它的方向可以向前或者向后,这是由于数据结构中定义了next和prev两个指针决定的,下面看下它的数据结构实现。
二、数据结构定义
typedef struct listNode {
struct listNode *next; //next指针,指向下一个元素
struct listNode *prev; //prev指针,指向上一个元素
void *value; //void *类型的数据域
} listNode;
typedef struct list {
struct listNode *head; //head指针指向链表头部
struct listNode *tail; //tail指针指向链表尾部
void *(*dup)(void *ptr); //自定义的复制函数,如果不定义,默认策略的复制操作会让原链表和新链表共享同一个数据域
void (*free)(void *ptr); //自定义free操作
int (*match)(void *ptr, void *key); //search操作的时候比较两个value是否相等,默认策略是比较两个指针的值
unsigned long len; //记录链表的长度,获取长度操作可以O(1)返回
} list;三、创建、头插、查找、反转输出、复制、拼接
老规矩,我们还是以一个例子来分析源码,这个例子中会设计到adlist的创建、头插、查找、反转输出、复制、拼接这些操作,例子的代码如下所示:
int keyMatch(void *ptr, void *key) {
return strcmp(ptr, key) == 0 ? 1 : 0;
}
void printList(list *li) {
printf("li size is %d, elements:", listLength(li));
listIter iter;
listNode *node;
listRewind(li, &iter);
while ((node = listNext(&iter)) != NULL) {
printf("%s ", (char*)node->value);
}
printf("\n");
}
int main(int argc, char **argv)
{
char b[][10] = {"believe", "it", "or", "not"};
listIter iter;
listNode *node;
list *li = listCreate();
for (int i = 0; i < sizeof(b)/sizeof(*b); ++i) {
listAddNodeHead(li, b[i]);
}
printList(li);
printf("\nSearch a key :\n");
listSetMatchMethod(li, keyMatch);
listNode *ln = listSearchKey(li, "believe");
if (ln != NULL) {
printf("find key is :%s\n", (char*)ln->value);
} else {
printf("not found\n");
}
printf("\nReverse output the list :\n");
printf("li size is %d, elements:", listLength(li));
listRewindTail(li, &iter);
while ((node = listNext(&iter)) != NULL) {
printf("%s ", (char*)node->value);
}
printf("\n");
printf("\nduplicate a new list :\n");
list *lidup = listDup(li);
printList(lidup);
printf("\nConnect two linked lists :\n");
listJoin(li, lidup);
printList(li);
listRelease(li);
return 0;
}
Out >
li size is 4, elements:not or it believe
Search a key :
find key is :believe
Reverse output the list :
li size is 4, elements:believe it or not
duplicate a new list :
li size is 4, elements:not or it believe
Connect two linked lists :
li size is 8, elements:not or it believe not or it believe - 创建
list *li = listCreate(); 创建了一个list,并且返回了指针,代码如下所示:
list *listCreate(void)
{
struct list *list;
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}- 头插
listAddNodeHead(li, b[i]);然后将预先定义好的数组元素依次头插入了list,与之对应的还有一个尾插的函数listAddNodeTail(),我们先看下头插listAddNodeHead()的代码:
list *listAddNodeTail(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++;
return list;
}函数首先申请了一个listNode节点,然后用list->len == 0判断了是不是首节点,然后根据不同的策略交换指针,将元素头插入链表,将长度增加,循环插入所有元素之后链表目前情况如下图所示:
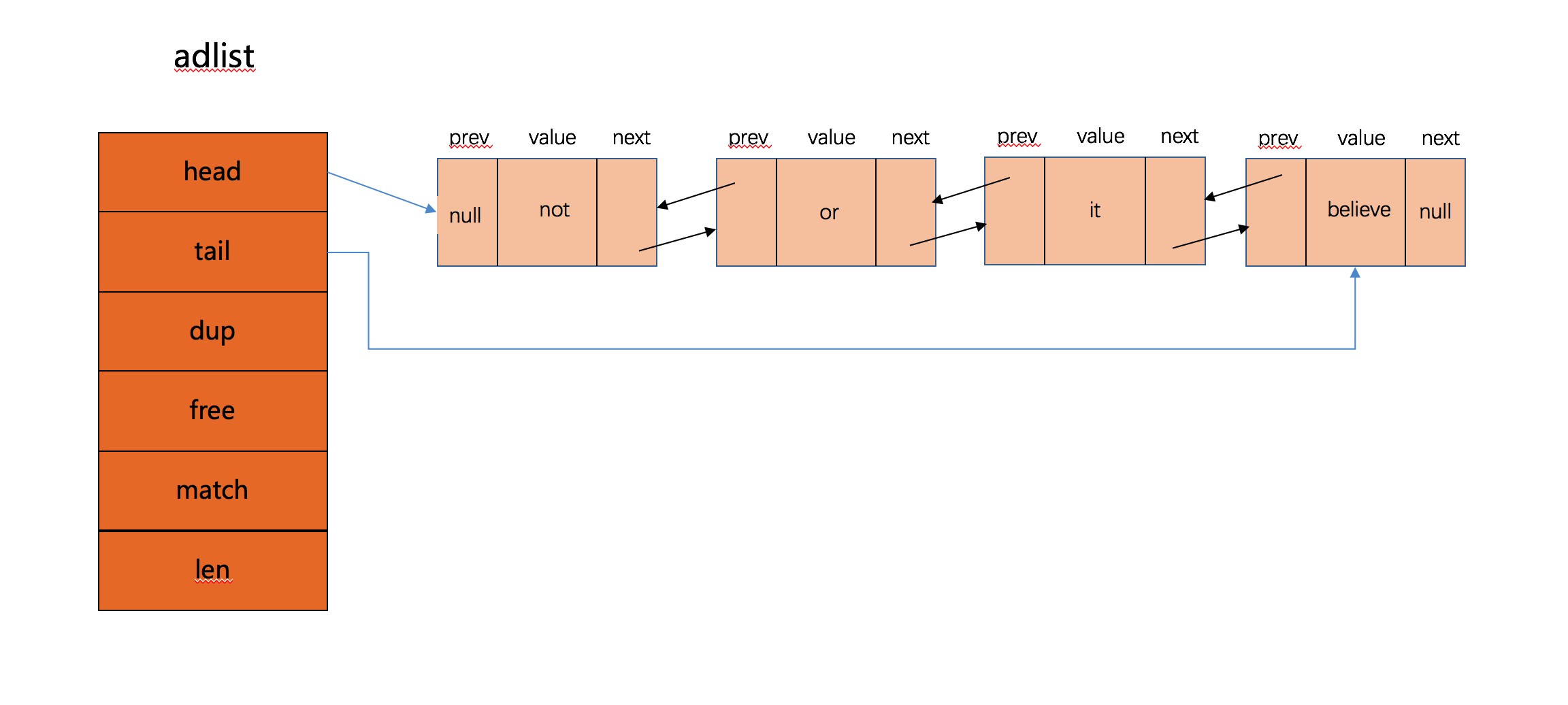
- 查找
listNode *ln = listSearchKey(li, "believe");可以查找第二个参数指定的字符串,默认的匹配原则是比较指针是否相等,但是可以自定义match函数,因为我们的例子中需要比较字符串,我自定义了keyMatch函数如下所示:
match函数的声明是:int (*match)(void *ptr, void *key);
int keyMatch(void *ptr, void *key) {
return strcmp(ptr, key) == 0 ? 1 : 0;
}
listSetMatchMethod(li, keyMatch);可以指定match函数,下面我们看下listSearchKey()函数的实现:
listNode *listSearchKey(list *list, void *key)
{
listIter iter;
listNode *node;
listRewind(list, &iter);
while((node = listNext(&iter)) != NULL) {
if (list->match) {
if (list->match(node->value, key)) { //如果用户自定义了比较函数,就直接使用
return node;
}
} else {
if (key == node->value) { //默认的比较策略是比较指针
return node;
}
}
}
- 翻转
因为adlist是双端链表,所以翻转操作十分简单,我们直接将迭代器初始化成从链表尾部开始遍历就完成了翻转操作。
listRewindTail(li, &iter); //将迭代器从尾部迭代- 复制
list *lidup = listDup(li);会创建一条新的链表返回给用户,但是需要注意默认的复制策略,如果用户不自定义dup()函数,默认返回的复制链表和原始链表共用相同的数据节点,这样对于一个节点修改会导致原始链表发生变化。如下所示:
list *lidup = listDup(li); //使用默认的复制操作
strncpy(listIndex(lidup, 0)->value, "abc", 3); //修改复制返回的链表的值
printList(lidup);
printList(li);
Out >
li size is 4, elements:abc or it believe
li size is 4, elements:abc or it believe //可以看到原始链表也受了影响,not 修改为了 abc
但是如果自定义dup函数,不再使得复制之后的链表和原始链表公用节点就可以避免这个问题:
void *strDup(void *ptr) {
return sdsnew(ptr);
}
listSetDupMethod(li, strDup); //设置自定义的dup函数
list *lidup = listDup(li);
strncpy(listIndex(lidup, 0)->value, "abc", 3);
printList(lidup);
printList(li);
Out >
li size is 4, elements:abc or it believe
li size is 4, elements:not or it believe //还是原始的值没有变化- 拼接
listJoin(li, lidup);可以将两个链表做连接操作:
void listJoin(list *l, list *o) {
if (o->head)
o->head->prev = l->tail; //将第二个链表链在第一个链表后边
if (l->tail)
l->tail->next = o->head;
else
l->head = o->head;
l->tail = o->tail;
l->len += o->len;
/* Setup other as an empty list. */
o->head = o->tail = NULL;
o->len = 0;
}- 释放
listRelease(li);函数负责释放链表,首先会调用listEmpty()函数释放掉所有listNode,最后再释放掉list本身的空间。
四、总结
adlist的实现相对来说较简单,我们上面分析了它的创建、插入、查找、反转等操作,基本上熟悉了API和底层数据结构的原理,但是由于链表新增节点时候(无论头插尾插)每次都是申请新的空间,所以比较容易造成内存碎片。这方面想想有无办法优化。
[完]
Redis源码分析(adlist)的更多相关文章
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- redis源码分析之事务Transaction(下)
接着上一篇,这篇文章分析一下redis事务操作中multi,exec,discard三个核心命令. 原文地址:http://www.jianshu.com/p/e22615586595 看本篇文章前需 ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- redis源码分析之发布订阅(pub/sub)
redis算是缓存界的老大哥了,最近做的事情对redis依赖较多,使用了里面的发布订阅功能,事务功能以及SortedSet等数据结构,后面准备好好学习总结一下redis的一些知识点. 原文地址:htt ...
- redis源码分析之事务Transaction(上)
这周学习了一下redis事务功能的实现原理,本来是想用一篇文章进行总结的,写完以后发现这块内容比较多,而且多个命令之间又互相依赖,放在一篇文章里一方面篇幅会比较大,另一方面文章组织结构会比较乱,不容易 ...
- redis源码分析之有序集SortedSet
有序集SortedSet算是redis中一个很有特色的数据结构,通过这篇文章来总结一下这块知识点. 原文地址:http://www.jianshu.com/p/75ca5a359f9f 一.有序集So ...
- Redis源码阅读-Adlist双向链表
Redis源码阅读-链表部分- 链表数据结构在Adlist.h Adlist.c Redis的链表是双向链表,内部定义了一个迭代器. 双向链表的函数主要是链表创建.删除.节点插入.头插入.尾插入. ...
- Redis源码分析(dict)
源码版本:redis-4.0.1 源码位置: dict.h:dictEntry.dictht.dict等数据结构定义. dict.c:创建.插入.查找等功能实现. 一.dict 简介 dict (di ...
- Redis源码分析系列
0.前言 Redis目前热门NoSQL内存数据库,代码量不是很大,本系列是本人阅读Redis源码时记录的笔记,由于时间仓促和水平有限,文中难免会有错误之处,欢迎读者指出,共同学习进步,本文使用的Red ...
随机推荐
- JDBC 基础入门
由于我也是初学参考的是网上的或者是培训机构的资料所以可能会有错误的信息,仅供参考 一.什么是JDBC(Java Data Base Connectivity)? java程序连接数据库,JDBC是由S ...
- aws中centos登陆连接设置
第一步:使用aws密钥文件(.pem)登陆(*在shell中需使用新建的会话,不能直接,使用原来的会话进行修改,否则无法进入) 点击浏览器,点添加,再点击导入,选择.pem 文件 第二步: 登陆后,使 ...
- AT3950-[AGC022E]Median Replace【贪心,dp】
正题 题目链接:https://www.luogu.com.cn/problem/AT3950 题目大意 一个包含\(?,0,1\)的长度为奇数的序列,把\(?\)替换为\(0/1\).每次可以选择三 ...
- Ybt#452-序列合并【期望dp】
正题 题目链接:https://www.ybtoj.com.cn/contest/113/problem/2 题目大意 一个空序列,每次往末尾加入一个\([1,m]\)中的随机一个数.如果末尾两个数相 ...
- GitHub 和 Gitee 开源免费 10 个超赞后台管理面板,看完惊呆了!
软件工程师在实际项目开发中不可避免需要依赖一些前后端的后台管理系统框架,而不是从零开始一点点的搭建,浪费人力.目前市面上有很多开放源码.且免费的后台管理面板,样式色彩也比较丰富美观. 今天整理 ...
- Winform 窗体自适应
前言 在使用 Winform 开发过程中,经常发些因为显示器分辨率.窗体大小改变,控件却不能自适应变化,几经查找资料,和大佬的代码.经过细小修改,终于可以让窗体在外界影响下,窗体内背景图片.控件都会自 ...
- docker-compose 搭建mongo集群
创建目录 在每台机器上操作此步骤 一.在编写容器文件之前的注意事项: 1.yaml文件的指令前端不能使用tab键只能使用空格 2.storage: 指令的对接只能使用 : 不能使用 = 冒号的后面要跟 ...
- Serverless 架构到底要不要服务器?
作者 | aoho 来源 | Serverless 公众号 Serverless 是什么? Serverless 架构是不是就不要服务器了?回答这个问题,我们需要了解下 Serverless 是什么. ...
- linux主机互信操作
一.主机互信原理两个主机之间ssh登录需要提示输入对方的密码,当频繁需要登录操作时,可以通过linux公钥和秘钥,建立双机信任关系.把你源主机的公钥文件内容追加到目的主机对应用户下的authorize ...
- 前段---css
css主要是用来做如何显示html元素的 当浏览器读到一个样式表,它就会按照这个样式表来对文档做渲染 注意:每一个css样式表都是由两个部分组成的, 1,选择器 2,声明 声明又包括属性值和属性,每个 ...