中文NER的那些事儿2. 多任务,对抗迁移学习详解&代码实现
第一章我们简单了解了NER任务和基线模型Bert-Bilstm-CRF基线模型详解&代码实现,这一章按解决问题的方法来划分,我们聊聊多任务学习,和对抗迁移学习是如何优化实体识别中边界模糊,垂直领域标注样本少等问题的。Github-DSXiangLi/ChineseNER中提供了bert_bilstm_crf_mtl多任务, 和bert_bilstm_crf_adv对抗迁移两个模型,支持任意NER+NER,CWS+NER的Joint Training。
多任务学习
以下Reference中1,2,3都是有关多任务学习来提升NER效果的,简单说多任务的好处有两个:
- 引入额外信息:帮助学习直接从主任务中难以提取出的特征
- 学到更通用的文本特征:多个任务都需要的信息才是通用信息,也可以理解成正则化,也可以理解为不同任务会带来噪声起到类似bagging的作用
MTL有很多种模型结构,之后我们主要会用到的是前三种,hard,Asymemetry和Customized Sharing, 下面让我们具体看下MTL在NER任务中的各种使用方式。
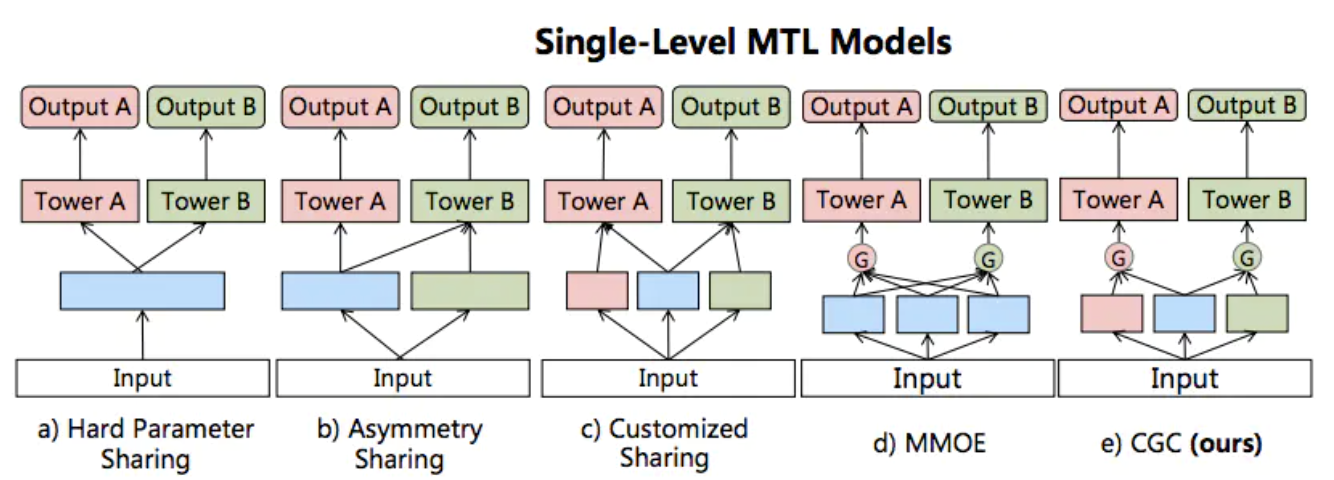
词边界增强:ner+cws
paper: Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning,2016
分词任务和实体识别任务进行联合训练主要体现了以上第一个优点’增加额外信息‘,让分词样本的词边界标注信息来提高NER边界识别的准确率。以下是Ref1中的模型结构,基本就是上面的Asymmetry Sharing。NER和CWS共享character embedding,在NER的CRF层,除了使用character emebdding, NER相关特征以外,还会使用CWS包含分词信息的最后一层。这里我对使用Asymmetry结构是存疑的,如果CWS和NER任务是对相同样本分别标注了分词和实体的话,用Asy确实更合理,但paper中一个是新闻样本一个是社交领域的样本,感觉asy会比hard sharing引入更多的噪音,后面我们会用MSRA和MSR数据来做测试。

训练时因为CWS和NER的样本量差异较大,作者提出在每个iteration,subsample大样本会显著加快模型收敛。我用的样本本身相差不大,所以也没有做相应的处理,感觉subsample,或者用不同的batch_size+task weight应该会有相似的效果。
跨领域半监督学习:ner+ner
paper: A unified Model for Cross-Domain and Semi-Supervised Named entity Recognition in Chinese Social Media, 2017
不同领域的NER任务进行联合学习主要体现了第二个优点‘通用文本特征提取’,用领域外标注样本和领域内未标注样本来帮助该领域标注样本,学习更加通用的文本特征和实体特征。
领域外到内的迁移,主要需要解决样本差异性问题,毕竟最终目标是希望帮助领域内文本学到合理的文本表达,所以需要penalize和目标领域差异过大的领域外样本。作者对比了3种方式来衡量样本x和目标领域的相似度\(func(x, IN)\),其中cosine距离效果最好
- cross-entropy: 用目标领域n-gram模型计算x的熵
- Gaisssian: 用所有目标领域文本embedding求平均构建\(v_{IN}\), 计算\(v_x\)和\(v_{IN}\)的欧式距离
- Polynomial Kernel:\(v_x\)和\(v_{IN}\)的cosine距离
领域内未标注样本的半监督学习,因为是直接用模型预测来做真实label,因此需要penalize预测置信度低的样本,这里作者用最优预测,相对次优预测提升的百分比做\(confid(x)\),置信度是动态的需要在每个iteration先对未标注进行预测再得到\(confid(x)\)
\]
整个模型框架是领域内标注/未标注样本和领域外标注样本的联合训练,以上相似度和置信度用于调整每个iteration训练时,不同样本的学习率\(lr = lr_0 *weight(x,t)\)
\begin{array}{align=left}
1.0 \quad \text{x 是领域内}\\
func(x, IN) \quad \text{x 是领域外}\\
confid(x,t) \quad \text{x 是未标注}
\end{array}
\right.
\]
这篇论文的创新一个在于对无标注样本的使用,不过个人认为在实际应用时直接使用的概率比较小,因为NER是token级别的分类任务,样本噪音对全局表现的干扰是比较大,不过用\(confid(x)\)作为主动学习的选择策略来筛选样本,让标注同学进行标注倒是一个可以尝试的思路。
其二是提出了要用领域相似度来调整lr,虽然考虑到了领域差异,不过解决方案还是相对简单,只能降低并不能排除领域差异的影响。这里只它当作引子,看之后的对抗迁移学习是如何解决领域差异问题的。
模型实现
repo里的model/bert_bilstm_crf_mtl实现了基于bert-bilstm-crf的多任务联合训练框架,根据传入数据集是ner+ner还是ner+cws可以实现以上的词增强和跨领域学习。MTL的相关参数主要是task_weight控制两个任务的loss权重,asymmetry控制模型结构是hard sharing(多任务只共享bert),还是asymmetry(task2使用task1的hidden output)。这里默认传入数据集顺序对应task1&2。
def build_graph(features, labels, params, is_training):
input_ids = features['token_ids']
label_ids = features['label_ids']
input_mask = features['mask']
segment_ids = features['segment_ids']
seq_len = features['seq_len']
task_ids = features['task_ids']
embedding = pretrain_bert_embedding(input_ids, input_mask, segment_ids, params['pretrain_dir'],
params['embedding_dropout'], is_training)
load_bert_checkpoint(params['pretrain_dir']) # load pretrain bert weight from checkpoint
mask1 = tf.equal(task_ids, 0)
mask2 = tf.equal(task_ids, 1)
batch_size = tf.shape(task_ids)[0]
with tf.variable_scope(params['task_list'][0], reuse=tf.AUTO_REUSE):
task_params = params[params['task_list'][0]]
lstm_output1 = bilstm(embedding, params['cell_type'], params['rnn_activation'],
params['hidden_units_list'], params['keep_prob_list'],
params['cell_size'], params['dtype'], is_training)
logits = tf.layers.dense(lstm_output1, units=task_params['label_size'], activation=None,
use_bias=True, name='logits')
add_layer_summary(logits.name, logits)
trans1, loglikelihood1 = crf_layer(logits, label_ids, seq_len, task_params['label_size'], is_training)
pred_ids1 = crf_decode(logits, trans1, seq_len, task_params['idx2tag'], is_training, mask1)
loss1 = tf.reduce_sum(tf.boolean_mask(-loglikelihood1, mask1, axis=0)) * params['task_weight'][0]
tf.summary.scalar('loss', loss1)
with tf.variable_scope(params['task_list'][1], reuse=tf.AUTO_REUSE):
task_params = params[params['task_list'][1]]
lstm_output2 = bilstm(embedding, params['cell_type'], params['rnn_activation'],
params['hidden_units_list'], params['keep_prob_list'],
params['cell_size'], params['dtype'], is_training)
if params['asymmetry']:
# if asymmetry, task2 is the main task using task1 information
lstm_output2 = tf.concat([lstm_output1, lstm_output2], axis=-1)
logits = tf.layers.dense(lstm_output2, units=task_params['label_size'], activation=None,
use_bias=True, name='logits')
add_layer_summary(logits.name, logits)
trans2, loglikelihood2 = crf_layer(logits, label_ids, seq_len, task_params['label_size'], is_training)
pred_ids2 = crf_decode(logits, trans2, seq_len, task_params['idx2tag'], is_training, mask2)
loss2 = tf.reduce_sum(tf.boolean_mask(-loglikelihood2, mask2, axis=0)) * params['task_weight'][1]
tf.summary.scalar('loss', loss2)
loss = (loss1+loss2)/tf.cast(batch_size, dtype=params['dtype'])
pred_ids = tf.where(tf.equal(task_ids, 0), pred_ids1, pred_ids2) # for infernce all pred_ids will be for 1 task
return loss, pred_ids, task_ids
这里我在NER(MSRA)+NER(people_daily), NER+CWS(MSR)上分别尝试了hard和asymmetry sharing的多任务学习,和前一章的Bert-Bilstm+CRF的benchmark进行对比,整体上来看MTL对MSRA样本基本没啥提升,但是对样本更小的people daily任务有非常显著约3~4%F1的提升。不过以上paper中使用的asy的多任务结构显著被没有带来显著提升,反倒是hard sharing只引入辅助任务来帮助bert finetune的效果更好些。不过MTL和任务选择关系很大,所以以上结论并不能直接迁移到其他任务。


对抗迁移学习
以上多任务学习还有一个未解决的问题就是hard和asymmmetry对共享参数层没有任何约束,在多任务训练时任务间的差异会导致带来信息增益的同时也带来了额外的噪音,抽取通用特征的同时也抽取了任务相关的私有特征。当辅助任务和主任务差异过大,或者辅助任务噪声过多时,MTL反而会降低主任务效果

这里任务差异可能是分词任务和实体识别词粒度的差异,不同领域NER任务文本的差异等等。前面提到的用领域相似度来对lr加权的方法只能缓解并不能解决问题,下面我们来看下对抗学习是如何把任务相关特征/噪音和通用特征区分开来的。
梯度反转 GRL
paper: Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism, 2018
这里就需要用到以上第三种MTL结构Customized Sharing。我们以NER+CWS任务为例,保留之前的NER tower和CWS tower,加入一个额外的share tower。理想情况是所有通用特征例如粒度相同的词边界信息都被share tower学到,而ner/cws任务相关的私有特征分别被ner/cws tower学到。作者通过对share tower加入对抗学习机制,来限制share tower尽可能保留通用特征。模型结构如下【我们用了Bert来抽取信息,self-attention层就可以先忽略了】

中间的share tower是一个task descriminator,先不看Gradient Reversal。其实是从输入文本中提取双向文本特征,过maxpooling层得到\(2*d_h\)领域特征,过softmax识别样本是来自NER还是CWS任务的二分类问题(或多分类问题如果有多个任务)
s &= MaxPooling(s)\\
D(s) &= softmax(Ws+b)\\
\end{align}
\]
从propensity score的角度,如果softmax得到的概率都在0.5附近,说明share tower学到的特征无法有效区分task,也就是我们希望得到的通用特征。为了实现这一效果,作者引入minmax对抗机制,softmax判别层尽可能去识别task,share-bilstm特征抽取层尽可能抽取混淆task的通用特征。
\]
其中K是任务,\(N_k\)是任务k的样本,\(E_s\)是用于通用信息提取的bilstm,\(x_i^k\)是任务k的第i个样本,以上公式是按多分类任务给出的。
这里作者用了GRL梯度反转层来实现minmax。softmax学到的用于识别task的特征梯度,反向传播过gradient reversal层会调转正负\(-1 * gradient\)再对share-bilstm的参数进行更新,有点像生成器和判别器按相同步数进行同步训练的GAN的另一种工程实现。之前有评论说梯度反转有些奇怪,因为目标是让share-bilstm学到通用特征,而不是学到把CWS判断成NER,把NER判断是CWS这种颠倒黑白的特征,个人感觉其实不会因为有minmax对抗机制在,在实际训练过程中task descriminator确实在一段时间后就会到达probability=0.5 cross-entropy=0.7上下的动态平衡。

模型实现
def build_graph(features, labels, params, is_training):
input_ids = features['token_ids']
label_ids = features['label_ids']
input_mask = features['mask']
segment_ids = features['segment_ids']
seq_len = features['seq_len']
task_ids = features['task_ids']
embedding = pretrain_bert_embedding(input_ids, input_mask, segment_ids, params['pretrain_dir'],
params['embedding_dropout'], is_training)
load_bert_checkpoint(params['pretrain_dir']) # load pretrain bert weight from checkpoint
mask1 = tf.equal(task_ids, 0)
mask2 = tf.equal(task_ids, 1)
batch_size = tf.shape(task_ids)[0]
with tf.variable_scope('task_discriminator', reuse=tf.AUTO_REUSE):
share_output = bilstm(embedding, params['cell_type'], params['rnn_activation'],
params['hidden_units_list'], params['keep_prob_list'],
params['cell_size'], params['dtype'], is_training) # batch * max_seq * (2*hidden)
share_max_pool = tf.reduce_max(share_output, axis=1, name='share_max_pool') # batch * (2* hidden) extract most significant feature
# reverse gradient of max_output to only update the unit use to distinguish task
share_max_pool = flip_gradient(share_max_pool, params['shrink_gradient_reverse'])
share_max_pool = tf.layers.dropout(share_max_pool, rate=params['share_dropout'],
seed=1234, training=is_training)
add_layer_summary(share_max_pool.name, share_max_pool)
logits = tf.layers.dense(share_max_pool, units=len(params['task_list']), activation=None,
use_bias=True, name='logits')# batch * num_task
add_layer_summary(logits.name, logits)
adv_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=features['task_ids'], logits=logits)
adv_loss = tf.reduce_mean(adv_loss, name='loss')
tf.summary.scalar('loss', adv_loss)
with tf.variable_scope('task1_{}'.format(params['task_list'][0]), reuse=tf.AUTO_REUSE):
task_params = params[params['task_list'][0]]
lstm_output = bilstm(embedding, params['cell_type'], params['rnn_activation'],
params['hidden_units_list'], params['keep_prob_list'],
params['cell_size'], params['dtype'], is_training)
lstm_output = tf.concat([share_output, lstm_output], axis=-1) # bath * (4* hidden)
logits = tf.layers.dense(lstm_output, units=task_params['label_size'], activation=None,
use_bias=True, name='logits')
add_layer_summary(logits.name, logits)
trans1, loglikelihood1 = crf_layer(logits, label_ids, seq_len, task_params['label_size'], is_training)
pred_ids1 = crf_decode(logits, trans1, seq_len, task_params['idx2tag'], is_training, mask1)
loss1 = tf.reduce_sum(tf.boolean_mask(-loglikelihood1, mask1, axis=0)) * params['task_weight'][0]
tf.summary.scalar('loss', loss1)
with tf.variable_scope('task2_{}'.format(params['task_list'][1]), reuse=tf.AUTO_REUSE):
task_params = params[params['task_list'][1]]
lstm_output = bilstm(embedding, params['cell_type'], params['rnn_activation'],
params['hidden_units_list'], params['keep_prob_list'],
params['cell_size'], params['dtype'], is_training)
lstm_output = tf.concat([share_output, lstm_output], axis=-1) # bath * (4* hidden)
logits = tf.layers.dense(lstm_output, units=task_params['label_size'], activation=None,
use_bias=True, name='logits')
add_layer_summary(logits.name, logits)
trans2, loglikelihood2 = crf_layer(logits, label_ids, seq_len, task_params['label_size'], is_training)
pred_ids2 = crf_decode(logits, trans2, seq_len, task_params['idx2tag'], is_training, mask2)
loss2 = tf.reduce_sum(tf.boolean_mask(-loglikelihood2, mask2, axis=0)) * params['task_weight'][1]
tf.summary.scalar('loss', loss2)
loss = (loss1+loss2)/tf.cast(batch_size, dtype=params['dtype']) + adv_loss * params['lambda']
pred_ids = tf.where(tf.equal(task_ids, 0), pred_ids1, pred_ids2)
return loss, pred_ids, task_ids
这里我们对比下adv和mtl的效果,。。。不排除我们用了强大的Bert做底层抽取,以及这里的3个任务本身差异并不太大,毕竟在people daily上MTL的效果提升已经十分显著,所以adv和mtl的差异感觉也就是个随机波动,之后要是有比较垂的样本再试试看吧~


Reference
- 【CWS+NER MTL】Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning,2016
- 【Cross-Domain LR Adjust】A unified Model for Cross-Domain and Semi-Supervised Named entity Recognition in Chinese Social Media, 2017
- 【MTL】Multi-Task Learning for Sequence Tagging: An Empirical Study, 2018
- 【CWS+NER Adv MTL】Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism, 2018
- 【Adv MTL】Adversarial Multi-task Learning for Text Classification, 2017
- Dual Adversarial Neural Transfer for Low-Resource Named Entity Recognition, 2019
- 【GRL】Unsupervised Domain Adaptation by Backpropagation,2015
- 【GRL】Domain-Adversarial Training of Neural Networks, 2016
- https://www.zhihu.com/question/266710153
中文NER的那些事儿2. 多任务,对抗迁移学习详解&代码实现的更多相关文章
- 中文NER的那些事儿3. SoftLexicon等词汇增强详解&代码实现
前两章我们分别介绍了NER的基线模型Bert-Bilstm-crf, 以及多任务和对抗学习在解决词边界和跨领域迁移的解决方案.这一章我们就词汇增强这个中文NER的核心问题之一来看看都有哪些解决方案.以 ...
- 中文NER的那些事儿4. 数据增强在NER的尝试
这一章我们不聊模型来聊聊数据,解决实际问题时90%的时间其实都是在和数据作斗争,于是无标注,弱标注,少标注,半标注对应的各类解决方案可谓是百花齐放.在第二章我们也尝试通过多目标对抗学习的方式引入额外的 ...
- 中文NER的那些事儿1. Bert-Bilstm-CRF基线模型详解&代码实现
这个系列我们来聊聊序列标注中的中文实体识别问题,第一章让我们从当前比较通用的基准模型Bert+Bilstm+CRF说起,看看这个模型已经解决了哪些问题还有哪些问题待解决.以下模型实现和评估脚本,详见 ...
- 中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有 ...
- # 中文NER的那些事儿6. NER新范式!你问我答之MRC
就像Transformer带火了"XX is all you need"的论文起名大法,最近也看到了好多"Unified XX Framework for XX" ...
- java中文乱码解决之道(二)-----字符编码详解:基础知识 + ASCII + GB**
在上篇博文(java中文乱码解决之道(一)-----认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述字符集.字符编码等基础知识和ASCII.GB的详情. 一.基 ...
- java中文乱码解决之道(二)—–字符编码详解:基础知识 + ASCII + GB**
原文出处:http://cmsblogs.com/?p=1412 在上篇博文(java中文乱码解决之道(一)—–认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述 ...
- 生成对抗网络GAN详解与代码
1.GAN的基本原理其实非常简单,这里以生成图片为例进行说明.假设我们有两个网络,G(Generator)和D(Discriminator).正如它的名字所暗示的那样,它们的功能分别是: G是一个生成 ...
- 采用Google预训bert实现中文NER任务
本博文介绍用Google pre-training的bert(Bidirectional Encoder Representational from Transformers)做中文NER(Name ...
随机推荐
- Pandas文件读取——Pandas.read_sql() 详解
目录 一.函数原型 二.常用参数说明 三.连接数据库方式--MySQL ①用sqlalchemy包构建数据库链接 ②用DBAPI构建数据库链接 ③将数据库敏感信息保存在文件中 一.函数原型 panda ...
- Dotnet洋葱架构实践
一个很清晰的架构实践,同时刨刨MySQL的坑. 一.洋葱架构简介 洋葱架构出来的其实有一点年头了.大约在2017年下半年,就有相关的说法了.不过,大量的文章在于理论性的讨论,而我们今天会用一个项目 ...
- 解Bug之路-主从切换"未成功"?
解Bug之路-主从切换"未成功"? 前言 数据库主从切换是个非常有意思的话题.能够稳定的处理主从切换是保证业务连续性的必要条件.今天笔者就来讲讲主从切换过程中一个小小的问题. 故障 ...
- 整合一套高性能网关Kong
前言 相信大家对Api网关都比较的熟悉,我们之前的文章也介绍过ASP.NET Core的网关Ocelot,也介绍过Spring Cloud Gateway.说到网关的主要功能,其实总结起来就两个字&q ...
- AgileConfig - 轻量级配置中心1.2.0发布,全新的UI✨✨✨
AgileConfig自发布以来有个"大问题"-UI太丑.因为当初这个项目是给自己用的,连UI界面都没有,全靠手动在数据库里改配置.后来匆匆忙忙使用bootstrap3简单的码了一 ...
- Dynamics CRM证书更换
Dynamics CRM产品一般有两种认证方式.第一种是基于声明的内部访问也就是无证书单纯用账号密码验证.第二种就是联合身份认证,需要安装网站证书. 对于联合身份认证的情况因为需要安装证书,而且证书是 ...
- OO第三单元小结
目录 JML理论基础 JML工具链 openjml使用 openjml总结 jmlunitng使用 代码分析 第一次作业 第二次作业 第三次作业 测试&bug分析 黑盒测试 白盒测试(Juni ...
- python基础(补充):lambda匿名函数,用了的,都说好!
lambda函数又叫做"匿名函数".当你完成一件小工作时,直接使用该函数可以让你的工作得心应手. lambda函数介绍 在Python中,定义函数使用的是def关键字,但是通过la ...
- 迷宫问题(BFS)
给定一个n* m大小的迷宫,其中* 代表不可通过的墙壁,而"."代表平地,S表示起点,T代表终点.移动过程中,如果当前位置是(x, y)(下标从0开始),且每次只能前往上下左右.( ...
- 自动化kolla-ansible部署ubuntu20.04+openstack-victoria之裸金属-20
自动化kolla-ansible部署ubuntu20.04+openstack-victoria之裸金属-20 欢迎加QQ群:1026880196 进行交流学习 近期我发现网上有人转载或者复制原创博客 ...