大数据学习day24-------spark07-----1. sortBy是Transformation算子,为什么会触发Action 2. SparkSQL 3. DataFrame的创建 4. DSL风格API语法 5 两种风格(SQL、DSL)计算workcount案例
1. sortBy是Transformation算子,为什么会触发Action
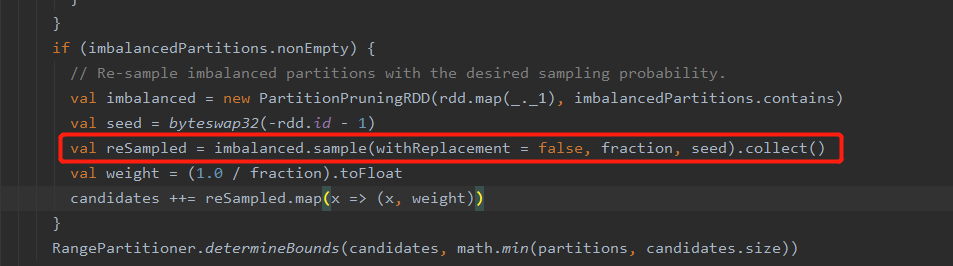
sortBy需要对数据进行全局排序,其需要用到RangePartitioner,而在创建RangePartitioner时需要大概知道有多少数据,以及数据的范围(采样),其内部获取这个范围(rangeBounds)是通过调用sample方法得到,在调用完sample后会调用collect方法,所以会触发Action
2. Spark SQL概述
2.1 Spark SQL定义:
Spark SQL是Spark用来处理结构化数据的一个模块
2.1.1 什么是DataFrames:
与RDD类似,DataFrame也是一个分布式数据容器【抽象的】。然而DataFrame更像DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也是支持嵌套数据类型(struct、array和map)。从API易用性角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好的继承了传统单机数据分析的开发体验
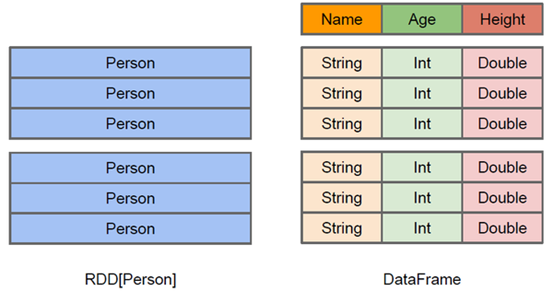
DataFrame = RDD + Schema【更加详细的结构化描述信息】,以后在执行就可以生成执行计划,进行优化。它提供了一个编程抽象叫做DataFrame/Dataset,它可以理解为一个基于RDD数据模型的更高级数据模型,带有结构化元信息(schema),以及sql解析功能
Spark SQL可以将针对DataFrame/Dataset的各类SQL运算,翻译成RDD的各类算子执行计划,从而大大简化数据运算编程(请联想Hive)
3 DateFrame的创建
3.1 sparksql1.x创建DataFrame(SQLContext)
这种形式的写法能更好的理解SQLContext就是对SparkContext的包装增强
package com._51doit.spark07 import com._51doit.spark05.Boy
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SQLContext,DataFrame} object DataFrameDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkSQL1x").setMaster("local[*]")
//sc是sparkcore,是用来创建RDD的
val sc = new SparkContext(conf)
// 要创建SQLContext,其相当于是对SparkContext包装增强
//SQLContext就可以创建DataFrame
val sqlContext: SQLContext = new SQLContext(sc)
// 使用SQLContext创建DataFrame(RDD+Schema)
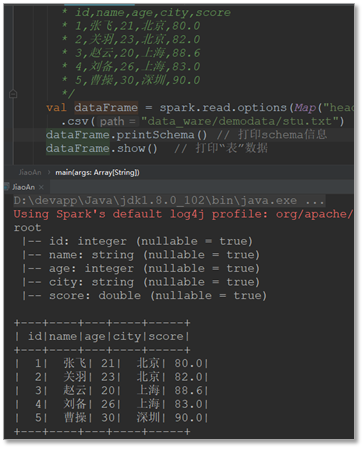
val rdd = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99"))
//RDD跟schema
val rdd1: RDD[Boy] = rdd.map(line => {
val fields = line.split(",")
val n = fields(0)
val a = fields(1)
val f = fields(2)
Boy(n, a.toInt, f.toDouble)
})
//导入隐式转换
import sqlContext.implicits._
//将RDD转成DataFrame
val df = rdd1.toDF
// 使用SQL风格的API
df.registerTempTable("boy")
// 传入SQL
// sql方法是Transformation
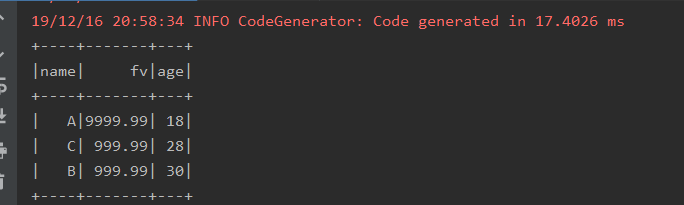
val res: DataFrame = sqlContext.sql("SELECT name, fv, age FROM boy ORDER BY fv DESC, age ASC")
//触发Action,将sql运行的结果收集到Driver端返回
res.show()
//释放资源
sc.stop()
}
}
运行结果
3.2 sparksql2.x创建DataFrame(SparkSession)
SparkSession是对SparkContext的封装,里面有SparkContext的引用,想获得sc直接使用SparkSession调用sparkContext
package com._51doit.spark07 import com._51doit.spark05.Boy
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession} object SparkSQL2x {
def main(args: Array[String]): Unit = {
// 编程SparkSQL程序,创建DataFrame
val session: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate()
// SparkSession 是对SparkContext的封装,里面持有SparkContext的引用
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99"))
val boyRDD: RDD[Boy] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val n = fields(0)
val a = fields(1)
val f = fields(2)
Boy(n, a.toInt, f.toDouble)
})
// 导入隐式转换
import session.implicits._
// 使用SparkSession创建DataFrame
val df: DataFrame = boyRDD.toDF()
df.createTempView("v_boy")
// 写SQL
val res: DataFrame = session.sql("SELECT name, fv, age FROM v_boy ORDER BY fv DESC, age ASC")
// 触发action
res.show()
session.stop()
}
}
运行结果同上
3.3 使用Scala的case class方式创建DataFrame
Boy
case class Boy(name:String, age:Int, fv: Double)
DataFrameDemo1(同2.2.2)
此处创建DF的方法
可变成如下(完整的写法):

3.4 使用Scala的 class方式创建DataFrame
Man(此处要用到set方法设置属性,所以需要用@BeanProperty)
class Man {
@BeanProperty
var name:String = _
@BeanProperty
var age:Integer = _
@BeanProperty
var fv:Double = _
def this(name: String, age: Int, fv: Double) {
this()
this.name = name
this.age = age
this.fv = fv
}
}
DataFrameDemo2
package com._51doit.spark07 import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession} object DataFrameDemo2 {
def main(args: Array[String]): Unit = {
//编程SparkSQL程序,创建DataFrame
val session: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate()
// 获取SparkContext
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9"))
val manRDD: RDD[Man] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val name: String = fields(0)
val age: Int = fields(1).toInt
val fv: Double = fields(2).toDouble
new Man(name, age, fv)
})
// 创建DataFrame
// import session.implicits._
// manRDD.toDF()
val df: DataFrame = session.createDataFrame(manRDD, classOf[Man])
//建df创建一个视图
df.createTempView("v_boy")
//写SQL
val result: DataFrame = session.sql("SELECT name, fv, age FROM v_boy ORDER BY fv DESC, age ASC")
//触发Action
result.show()
session.stop()
}
}
注意,此处用不了rdd.toDF的形式来创建DataFrame

3.5 使用java的 class方式创建DataFrame
形式和scala的class几乎一样
package com._51doit.spark07 import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession} object DataFrameDemo3 {
def main(args: Array[String]): Unit = {
//编程SparkSQL程序,创建DataFrame
val session: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate()
// 获取SparkContext
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9"))
val jPersonRDD: RDD[JPerson] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val name: String = fields(0)
val age: Int = fields(1).toInt
val fv: Double = fields(2).toDouble
new JPerson(name, age, fv)
})
// 创建DateFrame
val df: DataFrame = session.createDataFrame(jPersonRDD, classOf[JPerson])
// 创建一个视图
df.createTempView("v_person")
//写SQL
val result: DataFrame = session.sql("SELECT name, fv, age FROM v_person ORDER BY fv DESC, age ASC") //触发Action
result.show() session.stop()
}
}
3.6 使用scala元组的方式创建DataFrame
创建形式如下:
object DataFrame4 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("DataFrame4")
.master("local[*]")
.getOrCreate()
// 获取SparkSession
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9"))
val tpRDD: RDD[(String, Int, Double)] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val n = fields(0)
val a = fields(1)
val f = fields(2)
(n, a.toInt, f.toDouble)
})
// 创建DataFrame
import session.implicits._
val df: DataFrame = tpRDD.toDF
// 使用df创建一个视图
df.createTempView("v_person")
df.printSchema()
}
}
打印结果

这样写想要从表中获取数据是就只能使用_n,非常不方便
简单改变,在DF()方法中加入参数,如下
object DataFrame4 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("DataFrame4")
.master("local[*]")
.getOrCreate()
// 获取SparkSession
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9"))
val tpRDD: RDD[(String, Int, Double)] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val n = fields(0)
val a = fields(1)
val f = fields(2)
(n, a.toInt, f.toDouble)
})
// 创建DataFrame
import session.implicits._
val df: DataFrame = tpRDD.toDF("name", "age", "face_value")
df.createTempView("v_person")
val result: DataFrame = session.sql("SELECT name, age, face_value FROM v_person ORDER BY face_value DESC, age ASC")
//触发Action
result.show()
session.stop()
}
3.7 通过row方法的形式创建DataFrame
代码如下
package cn._51doit.spark.day07 import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** *
* 使用SparkSQL的ROW的方式
*/
object DataFrameDemo5 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame
val session: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate() //SparkSession是对SparkContext的封装,里面持有SparkContext的引用
val sc = session.sparkContext val rdd = sc.parallelize(List("laozhao,18,9999.99", "laoduan,30,999.99", "nianhang,28,999.99")) //RowRDD
val rowRDD: RDD[Row] = rdd.map(line => {
val fields = line.split(",")
val n = fields(0)
val a = fields(1)
val f = fields(2)
Row(n, a.toInt, f.toDouble)
}) //schema
// val schema = StructType(
// List(
// StructField("name", StringType),
// StructField("age", IntegerType),
// StructField("fv", DoubleType)
// )
// ) val schema = new StructType()
.add(StructField("name", StringType))
.add(StructField("age", IntegerType))
.add(StructField("fv", DoubleType)) val df: DataFrame = session.createDataFrame(rowRDD, schema)
df.printSchema()
session.stop()
}
}
3.8 通过解析json文件的形式创建DataFrame
package cn._51doit.spark.day07 import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** *
* 读取JSON文件创建DataFrame
*/
object DataFrameDemo6 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame
val spark: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate() //从JSON文件中读取数据,并创建DataFrame
//RDD + Schema【json文件中自带Schema】
//
val df: DataFrame = spark.read.json("/Users/star/Desktop/user.json") //df.printSchema()
df.createTempView("v_user")
val result: DataFrame = spark.sql("SELECT name, age, fv FROM v_user WHERE _corrupt_record IS NULL")
result.show()
spark.stop()
}
}
3.9 读取csv文件的形式创建DataFrame
package cn._51doit.spark.day07
import org.apache.spark.sql.{DataFrame, SparkSession}
/** *
* 读取csv文件创建DataFrame
*/
object DataFrameDemo7 {
def main(args: Array[String]): Unit = {
//编程SparkSQL程序,创建DataFrame
val spark: SparkSession = SparkSession.builder()
.appName("SparkSQL2x")
.master("local[*]")
.getOrCreate()
//从JSON文件中读取数据,并创建DataFrame
//RDD + Schema【csv文件中自带Schema】
//
val df: DataFrame = spark.read
.option("header", true) //将第一行当成表头
.option("inferSchema",true) //推断数据的类型,默认都是string
.csv("/Users/star/Desktop/user.csv")
//默认指定名称为 _c0, _c1, _c2
//val df1: DataFrame = df.toDF("name", "age", "fv")
//给指定字段重命名
//val df1 = df.withColumnRenamed("_c0", "name")
df.printSchema()
//df.createTempView("v_user")
//val result: DataFrame = spark.sql("SELECT name, age, fv FROM v_user WHERE _corrupt_record IS NULL")
df.show()
spark.stop()
}
}
4. DSL风格API语法
DSL风格API,就是用编程api的方式,来实现sql语法
使用DSL风格API【就是直接调用DataFrame的算子,Transformation和Action】

DataFrameDSLAPI
object DataFrameDSLAPI {
def main(args: Array[String]): Unit = {
// 编程SparkSQL程序,创建DataFrame
val session: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// 获取SparkContext
val sc: SparkContext = session.sparkContext
val rdd: RDD[String] = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99"))
val boyRDD: RDD[Boy] = rdd.map(line => {
val fields: Array[String] = line.split(",")
val name: String = fields(0)
val age: String = fields(1)
val fv: String = fields(2)
Boy(name, age.toInt, fv.toDouble)
})
// 导入隐式转换,创建DF
import session.implicits._
val df: DataFrame = boyRDD.toDF()
// 使用DSL风格API
val result: Dataset[Row] = df.select("name","fv").where($"fv" >= 1000)
//触发Action
result.show()
session.stop()
}
}
5.案例
wordcount案例
5.1 SQL风格
(1)结合flatmap算子(DSL风格的API,即算子)进行操作
package com._51doit.spark07
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object SQLWordCount {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// Dataset是更加智能的RDD,只有一列,命名默认为value
val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt")
// 导入隐式转换
import spark.implicits._
val words: Dataset[String] = lines.flatMap(_.split(" "))
// 将words注册成视图
words.createTempView("v_words")
// 写SQL
val res: DataFrame = spark.sql("SELECT value word, count(1) counts FROM v_words GROUP BY word ORDER BY counts DESC")
res.write.csv("E:/javafile/out1")
spark.stop()
}
}
(2)直接通过SQL的形式
object SQLWordCountAdv {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// Dataset是更加智能的RDD,只有一列,命名默认为value
val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt")
// 将words注册成视图
lines.createTempView("v_lines")
// 写SQL
spark.sql(
s"""
|SELECT word, COUNT(1) counts FROM
| (SELECT EXPLODE(words) word FROM
| (SELECT SPLIT(value, ' ') words FROM v_lines)
| )
| GROUP BY word ORDER BY counts DESC
|""".stripMargin
).show()
spark.stop()
}
}
5.2 DSL风格(更方便)
(1)
object DataSetWordCount1 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// Dataset是更加智能的RDD,只有一列,命名默认为value
val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt")
// 导入隐式转换
import spark.implicits._
// 调用DSL风格的API
val words: Dataset[String] = lines.flatMap(_.split(" "))
words.groupBy("value")
.count()
.orderBy($"count" desc)
.show()
spark.stop()
}
}
这种写法只能使用默认的列名,若想自己命名列的话可以使用withColumnRenamed,如下
(2)将结果写入数据库(Mysql)
package com._51doit.spark07
import java.util.Properties
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
object DataSetWordCount2 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// Dataset是更加智能的RDD,只有一列,命名默认为value
val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt")
// 导入隐式转换
import spark.implicits._
// 调用DSL风格的API
val words: DataFrame = lines.flatMap(_.split(" ")).withColumnRenamed("value", "word")
//使用DSL风格的API
//导入agg里面使用的函数
import org.apache.spark.sql.functions._
val result: DataFrame = words.groupBy("word").agg(count("*") as "counts").sort($"counts" desc)
//将数据保存到MySQL
val props = new Properties()
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", "root")
props.setProperty("password", "feng")
//触发Action
result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8&useSSL=true", "words", props)
println("haha")
spark.stop()
}
}
运行结果

大数据学习day24-------spark07-----1. sortBy是Transformation算子,为什么会触发Action 2. SparkSQL 3. DataFrame的创建 4. DSL风格API语法 5 两种风格(SQL、DSL)计算workcount案例的更多相关文章
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- 大数据学习day21-----spark04------1. 广播变量 2. RDD中的cache 3.RDD的checkpoint方法 4. 计算学科最受欢迎老师TopN
1. 广播变量 1.1 补充知识(来源:https://blog.csdn.net/huashetianzu/article/details/7821674) 之所以存在reduce side jo ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
随机推荐
- vim 脚本,自动添加文件头部信息
相信很多人编写脚本的时候都会在脚本头部写一些信息,记录文件生成时候,生成人姓名等 建议在自己的家目录下的 .vimrc 文件 下添加以下内容 [ autocmd BufNewFile *.sh exe ...
- Filter学习笔记
博客园的编辑器太丑了,所以我换用了别的Markdown编辑器,并用图片形式上传.
- docker file 笔记
FROM # FROM scratch, FROM centos, FROM ubuntu:latest LABEL RUN # 每运行一次RUN,image都会生成新的一层,为了美观,避免 ...
- 在dotnet6发布之际,FastNat内网穿透,给开发人员送的硬货福利
一.FastNat可为您解决的问题 1.没有公网服务器,但是想发布共享本地的站点或网络程序到公网上,以供他人访问: 此项功能大大方面开发人员进行远程调试,微信小程序等开发工作进行. 2.需要远程到在其 ...
- c++学习笔记2(const关键词的用法)
定义常量指针 优势(便于类型检查,define无类型检查(目前不是很理解)) (函数参数为常量指针时,可避免函数内部不小心改变参数指针所指的地方,如有出现此类语句,编译则会报错) strcpy:复制字 ...
- Python知识整理(一)
一.Python交互模式(终端上进行) python # 进入到Python交互模式,提示符是 >>> exit() # 退出Python交互模式 python xxx.py # 执 ...
- MYSQL数据库重新初始化
前言 我们在日常开发过程中,可能会遇到各种mysql服务无法启动的情况,各种百度谷歌之后,依然不能解决的时候,可以考虑重新初始化mysql.简单说就是重置,"恢复出厂设置".重置之 ...
- [ccBB]Billboards
参考loj2265中关于杨表的相关知识 先来考虑$m\mid n$的情况: 记$t=\frac{n}{m}$,将序列划分为$[1,m],[m+1,2m],...,[(t-1)m+1,tm]$这$t$段 ...
- [loj6051]PATH
(不妨将下标改为从1开始) 参考loj2265中关于杨表的相关知识 构造一个$n$行且第$i$行有$a_{i}$个格子的杨表,依次记录其每一次增加的时间(范围为$[1,\sum_{i=1}^{n}a_ ...
- [noi239]count
将每一个ai表示为$ai=ki\cdot m+ri$,即满足$m\sum ki+\sum ri=n$且$0<ri<m$枚举$S=\sum ri$(S范围是$k\le S\le k(m-1) ...