【论文阅读】End to End Learning for Self-Driving Cars
前言引用
[1] End to End Learning for Self-Driving Cars从这里开始
[1.1] 这个是相关的博客:2016:DRL前沿之:End to End Learning for Self-Driving Cars
[1.2] 其中提到的视频:GTC 2016: Self-Driving Car Demo, Roborace and Wrapping Up (part 11)
摘要
万事从摘要开始:
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads.
The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads.
Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e. g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn't automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps.
We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVETM PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).
碎碎念:这一篇不是专门的会议或者是期刊论文,所以我觉得看起来没啥难度?毕竟本科毕设的时候看了3、4篇关于slam的 一脸懵逼 真的是一脸懵逼; 这一篇呢,也是因为随意点,所以摘要比以往要长,做的事:直接拿CNN 卷积网络来走,测试场景有晴天、雨天、雾天、黑夜、白天等,一共72个小时的人开数据,论文中公式也不多,非常适合了解end-to-end的第一篇,(所以我其实是偷偷改了改顺序的,从简单的开始比较适合... 初入)
Purpose
1.The primary motivation for this work is to avoid the need to recognize specific human-designed features
2. avoid having to create a collection of "if, then, else" rules 这个好真实哦 hhh
Method
1.首先介绍了CNN -> pattern recognition;这是总图 其实神经网络和卷积学过可能都能看懂?然而我学卷积的时候太快了,基本忘完了 也不影响整体的阅读(但是复现要求肯定还是需要理论彻底)
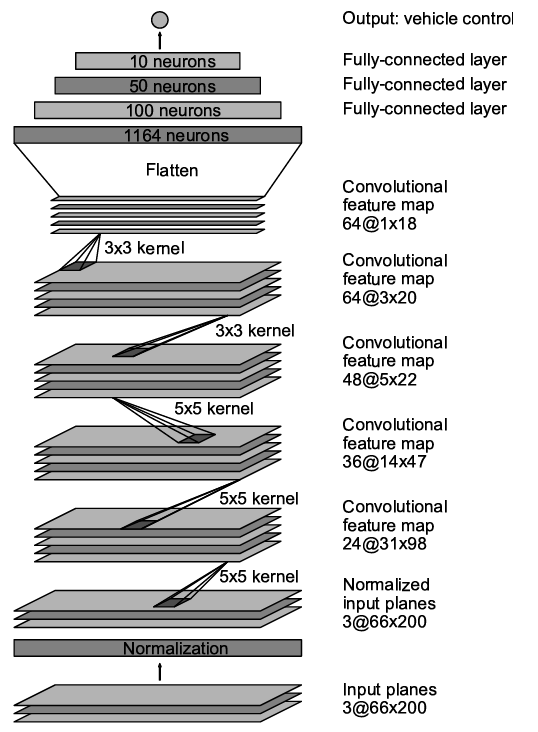
2.一句话分析了89年的那一篇就是从0开始的那里提到的ALVINN【ALVINN used a fully-connected network which is tiny by today's standard】从这句话里听到了NVIDIA的设备高级感
3.steering command 在这里是以\(\frac{1}{r}\),\(r\)是转弯的半径 用分号的形式是为了避免singularity. 【其实我这里想问为什么嘛不直接以方向盘的旋转角度?】
4. We train the weights of our network to minimize the mean squared error between the steering command output by the network and the command of either the human driver, or the adjusted steering command for off-center and rotated images. 通过系统学习的和人开的图的中心偏移的方差误差进行学习调整steering command【这里我对于学习所获的图表示怀疑,就是系统学习输出的动作,作为图像的输入,怎么得出的动作后的图像从而进行对比? 这一点论文里没有提?在simulation 就说了一个词generates images emmm 这个我就很疑惑】
5.就是对autonomy 的定义公式:
\]
到这里就是最后一步了,都到评价了(人工介入的次数)
6. 是有趣的发现,发现第一二个特征识别的layers学习后的权重输出的特征图 恰巧就是路边边缘,也侧面证实了 确实是按着人的思路去开的(就是我们开车也是第一步识别路边缘,进行跟随路边缘行驶)
Limitation
1.It's not possible to make a clean break between which parts of the network function primarily as feature extractor and which serve as controller. 就是有点分不清哪里是决定特征的哪里是决定动作的(决定性输出 毕竟是端到端嘛)
2.more work is needed to improve the robustness of the network to find methods to verify the robustness, and to improve visualization of the network-internal processing steps. 系统的鲁棒性问题,不过这个点出来有点笼统
以上,遗留的两个问题看我后面能不能回来回答它们了,另外大概的顺序都是从以前的到现在的,这样也好看出一步步的进步。
自己的一些想法
1.和师兄讨论发现,这个点主要是缺乏可解释性,从而让很多学者不敢在实车上进行测试后,在实车上测试end2end都是一大群公司的工程师 - 比如这篇论文NVIDIA 我取的名字是暴力学习hhhh,而end2end这个方向也是一个很大的工程类方向,大是因为他不好划分,比如细致的划分(因为这样我们就又回到传统了)所以怎么把握这个点 emm
2.还有就是limitation提到的第一点,这也就是上一点,有重复之处,cpd哥后面指出了uber那边2020年的论文里有细分,但是还是在end2end 所以那么下一次见
【论文阅读】End to End Learning for Self-Driving Cars的更多相关文章
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- 论文阅读 | Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition
源地址 arXiv:1712.07465: Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- [论文阅读] A Discriminative Feature Learning Approach for Deep Face Recognition (Center Loss)
原文: A Discriminative Feature Learning Approach for Deep Face Recognition 用于人脸识别的center loss. 1)同时学习每 ...
- 论文阅读 | DeepDrawing: A Deep Learning Approach to Graph Drawing
作者:Yong Wang, Zhihua Jin, Qianwen Wang, Weiwei Cui, Tengfei Ma and Huamin Qu 本文发表于VIS2019, 来自于香港科技大学 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
随机推荐
- H.264/H265码流解析
H.264/H265码流解析 一.H.264码流解析 一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成 一个原始的 ...
- Linux内存技术分析(上)
Linux内存技术分析(上) 一.Linux存储器 限于存储介质的存取速率和成本,现代计算机的存储结构呈现为金字塔型.越往塔顶,存取效率越高.但成本也越高,所以容量也就越小.得益于程序访问的局部性原理 ...
- 使用Keil语言的嵌入式C编程教程(下)
使用Keil语言的嵌入式C编程教程(下) 用8051单片机进行定时器/计数器的计算与编程 延迟是应用软件开发中的重要因素之一.然而,在实现定时延迟的过程中,正常的延迟并不能给出克服这一问题的宝贵结果. ...
- 工作流Activiti框架中的LDAP组件使用详解!实现对工作流目录信息的分布式访问及访问控制
Activiti集成LDAP简介 企业在LDAP系统中保存了用户和群组信息,Activiti提供了一种解决方案,通过简单的配置就可以让activit连接LDAP 用法 要想在项目中集成LDAP,需要在 ...
- Spring Cloud Alibaba(15)---Sleuth+Zipkin
SpringCloudAlibaba整合Sleuth+Zipkin 有关Sleuth之前有写过两篇文章 Spring Cloud Alibaba(13)---Sleuth概述 Spring Cloud ...
- 【题解】Luogu p2016 战略游戏 (最小点覆盖)
题目描述 Bob喜欢玩电脑游戏,特别是战略游戏.但是他经常无法找到快速玩过游戏的办法.现在他有个问题. 他要建立一个古城堡,城堡中的路形成一棵树.他要在这棵树的结点上放置最少数目的士兵,使得这些士兵能 ...
- Java并发编程--基础进阶高级(完结)
Java并发编程--基础进阶高级完整笔记. 这都不知道是第几次刷狂神的JUC并发编程了,从第一次的迷茫到现在比较清晰,算是个大进步了,之前JUC笔记不见了,重新做一套笔记. 参考链接:https:// ...
- C++中指针与引用详解
在计算机存储数据时必须要知道三个基本要素:信息存储在何处?存储的值为多少?存储的值是什么类型?因此指针是表示信息在内存中存储地址的一类特殊变量,指针和其所指向的变量就像是一个硬币的两面.指针一直都是学 ...
- Oracle数据泵导出数据库
Oracle数据泵导出数据库 特别注意:如果后续要导入的数据库版本低,所有导出命令就需要在后面加一个version=指定版本. 例如从11g导出数据导入到10g,假设10g具体版本为10.2.0.1, ...
- Kubernetes之deployment
Kubernetes实现了零停机的升级过程.升级操作可以通过使用ReplicationController或者ReplicaSet实现,但是Kubernetes提供了另一种基于ReplicaSet的资 ...