[炼丹术]UNet图像分割模型相关总结
UNet图像分割模型相关总结
1.制作图像分割数据集
1.1使用labelme进行标注
(注:labelme与labelImg类似,都属于对图像数据集进行标注的软件。但不同的是,labelme更关心对象的边缘和轮廓细节,也即通过生成和训练图像对应的mask来实现图像分割的目的。这里的分割一般使用的是闭合多边形折线来进行标注,每张图片标注完成后,按下Ctrl+S来进行保存,此时存储的文件是与图片同名的.json格式文件。)
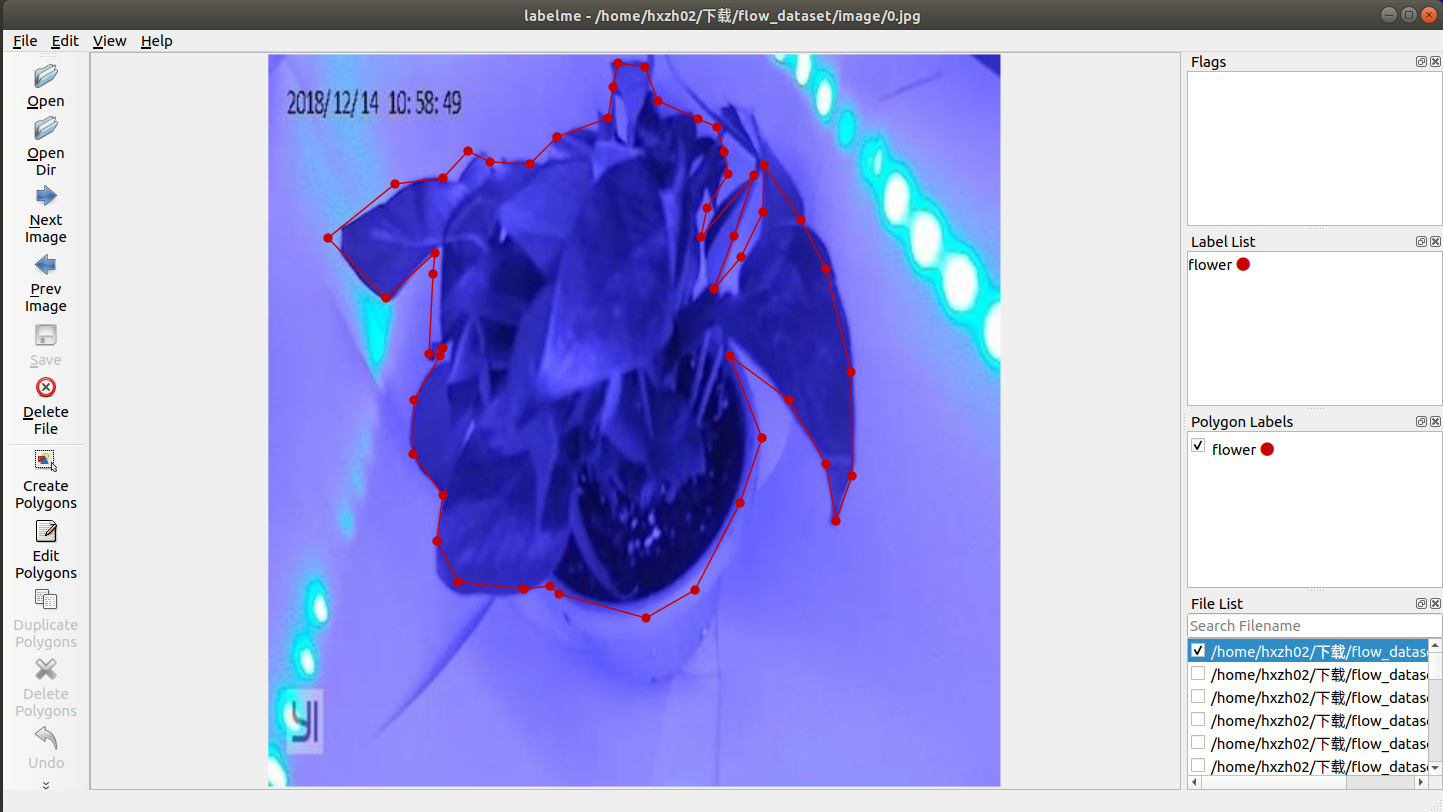
我们要得到的结果是mask,保存生成的.json文件还需要通过转换得到对应的mask图像。
(这里的转换有两种方式,一种是找到当前python环境下的labelme_json_to_dataset.py进行修改,二是直接在命令行中调用对应的接口labelme_json_to_dataset {file}生成mask,由于单命令行直接执行一个文件的生成,因此这里考虑编写对应的脚本,对当前目录下的.json进行批量处理。)
1.2生成mask文件
使用第二种方式,步骤如下:
1.新建.sh脚本文件
touch json2mask.sh
2.编辑.sh脚本文件
将下列内容复制进.sh脚本文件中
gedit json2mask.sh
#!/bin/bash
let i=1
path=./
cd ${path}
for file in *.json
do
labelme_json_to_dataset ${file}
let i=i+1
done
3.执行脚本
bash json2mask.sh
对.json文件进行转换生成之后,会得到对应名称的文件夹
如图所示
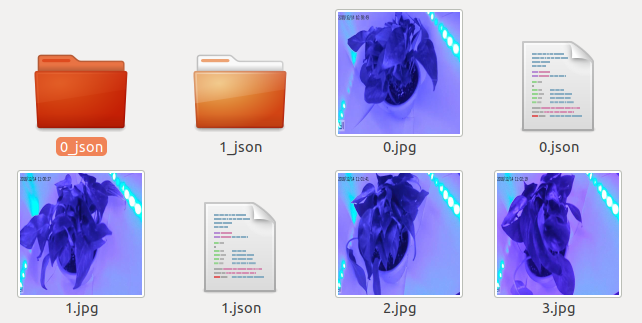
查看文件夹,发现存在四个文件:
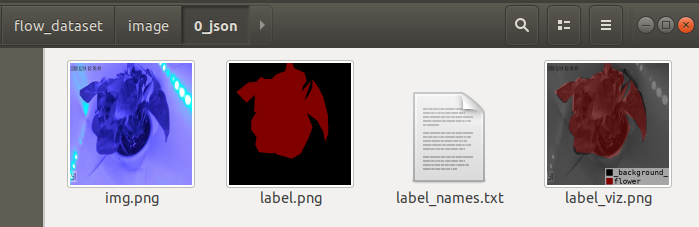
分别为以下:
- img.png,源文件图像
- label.png,标签图像
- label_names.txt,标签中的各个类别的名称
- label_viz.png,源文件与标签融合文件
其中的label.png即是我们要的想要的标签文件。如果本来的源文件图像为jpg格式,我们会发现生成的png格式源文件图像大小会大很多,不必惊慌。JPG质量不会有变化,但大小通常会增加几倍左右,这是因为JPG是有损压缩,而PNG是无损压缩。
1.3 转换二值图像并批量整理
得到以上这些结果是不是意味着结束了呢?
事实上,到这里才仅仅完成的一半,我们还需要对label.png图片进行转换为二值图片,最后我们可以遍历文件夹内所有小文件夹,分别对其中的img和转换后的label进行重命名存储到对应的imgs和masks文件目录下,到这一步整个数据集制作才算全部完成。
通过执行下面代码可以批量的对各个小文件夹下的图片进行重命名和整理:
'''
@author: linxu
@contact: 17746071609@163.com
@time: 2021-08-21 上午11:54
@desc: 将多通道mask图像批量转换为单通道二值化图像并存放到指定位置
'''
import cv2
import numpy as np
import os
import os
def os_mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部/符号
path = path.rstrip("/")
# 判断路径是否存在
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
def mask2binimg(path,show=False):
for root, dirs, files in os.walk(path):
print('################################################################')
for name in files:
# 遍历label生成的{x}_json目录
if len(dirs) == 0:
# print('root', root)
# 字符分割,得到label排序序号
filepath = os.path.split(root)[0]
numname = os.path.split(root)[1]
n_name = numname.replace('_json','')
# 处理原图img
if name == 'img.png':
fname = os.path.join(root, name)
print('INFO[img]', fname)
img = cv2.imread(fname)
img_dst = cv2.resize(img, (640, 480))
# img = cv2.resize(img, (0, 0), fx=0.3, fy=0.3, interpolation=cv2.INTER_NEAREST)
if show:
cv2.imshow('img', img_dst)
cv2.waitKey()
# 根据指定路径存取二值化图片
img_path = filepath + '/imgs/'
os_mkdir(img_path)
cv2.imwrite(img_path + str(n_name) + '.png', img_dst)
# 处理label标签图
if name == 'label.png':
fname = os.path.join(root, name)
print('INFO[label]', fname)
label = cv2.imread(fname)
label = cv2.resize(label, (640, 480))
gray = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
retVal, dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
# 显示图片
if show:
cv2.imshow('label', label)
cv2.imshow('dst', dst)
if cv2.waitKey(1) & 0xff == ord("q"):
break
# 根据指定路径存取二值化图片
mask_path = filepath + '/masks/'
os_mkdir(mask_path)
cv2.imwrite(mask_path + str(n_name) + '.png', dst)
print('当前图片转换完成...')
pass
if __name__ == '__main__':
path = '/home/linxu/下载/flow_dataset/image/'
mask2binimg(path,False)
运行结束后,会发现目录下多了两个文件夹,一个是imgs,用来存放原图;另外一个是masks,用来存放二值化标注图像。
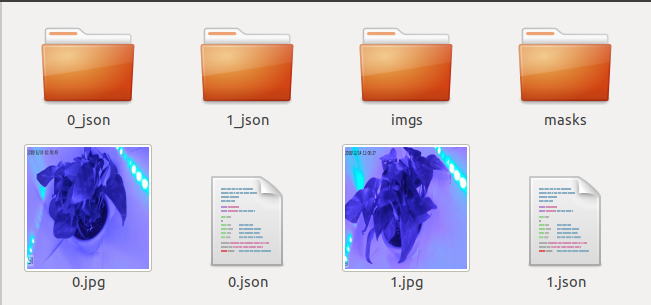
文件目录imgs下内容如下图所示:
文件目录masks下内容如下图所示:

确认imgs与masks内容无误之后,将这两个文件夹拷贝到UNet模型源码目录下的data路径,如下图所示:
至此,数据集制作完毕并放置到指定训练路径下。
2.Train训练
制作完数据集之后,下一步就是对数据集进行训练
python train.py -h
2.1 用法
train.py [-h] [-e E] [-b [B]] [-l [LR]] [-f LOAD] [-s SCALE] [-v VAL]
在图像和目标掩码上训练 UNet
可选参数:
- -h , --help 显示此帮助信息并退出
- -e E, --epochs E 时期数(默认值:5)
- -b [B], --batch-size [B]
批量大小(默认值:1) - -l [LR], --learning-rate [LR]
学习率(默认:0.1) - -f LOAD, --load LOAD 从 .pth 文件加载模型(默认:False)
- -s SCALE, --scale SCALE
图像的缩小因子(默认值:0.5) - -v VAL, --validation VAL
用作验证的数据百分比 (0-100)
(默认值:10.0)
默认情况下,该scale值为 0.5,因此如果您希望获得更好的结果(但使用更多内存),请将其设置为 1。
输入图像和目标掩码应分别位于data/imgs和data/masks文件夹中。
2.2 调用示例
python train.py -e 200 -b 1 -l 0.1 -s 0.5 -v 15.0
3.Predict预测
python predict.py -h
3.1 用法
predict.py [-h] [--model FILE] --input INPUT [INPUT ...]
[--output INPUT [INPUT ...]] [--viz] [ --no-save]
[--mask-threshold MASK_THRESHOLD] [--scale SCALE]
可选参数:-h , --help 显示此帮助消息并退出
--model FILE, -m FILE
指定文件在该模型被存储(默认值:MODEL.pth)--input INPUT [INPUT ...],-i INPUT [INPUT ...]
的输入图像的文件名(默认值:无)--output INPUT [INPUT ...], -o INPUT [INPUT ...]
输出图像的文件名(默认值:无)--
viz,-v 在处理图像时可视化(默认值:False)-- no -save, -n 不保存输出掩码 (默认: False)
--mask-threshold MASK_THRESHOLD, -t MASK_THRESHOLD
考虑掩码像素 白色的最小概率值(默认: 0.5)--scale SCALE, -s SCALE 比例因子对于输入图像(默认值:0.5)
3.2 调用示例
- 要预测单个图像并保存它:
python predict.py -i image.jpg -o output.jpg
- 要预测多个图像并显示它们而不保存它们:
python predict.py -i image1.jpg image2.jpg --viz --no-save
3.3 融合预览
为更加直观地感受分割后得到的结果,下面采用图像融合的方式进行预览
(说明:其中img1为图像原图,img2为预测的二值图像,image为两者根据一定比例融合之后得到的结果。)
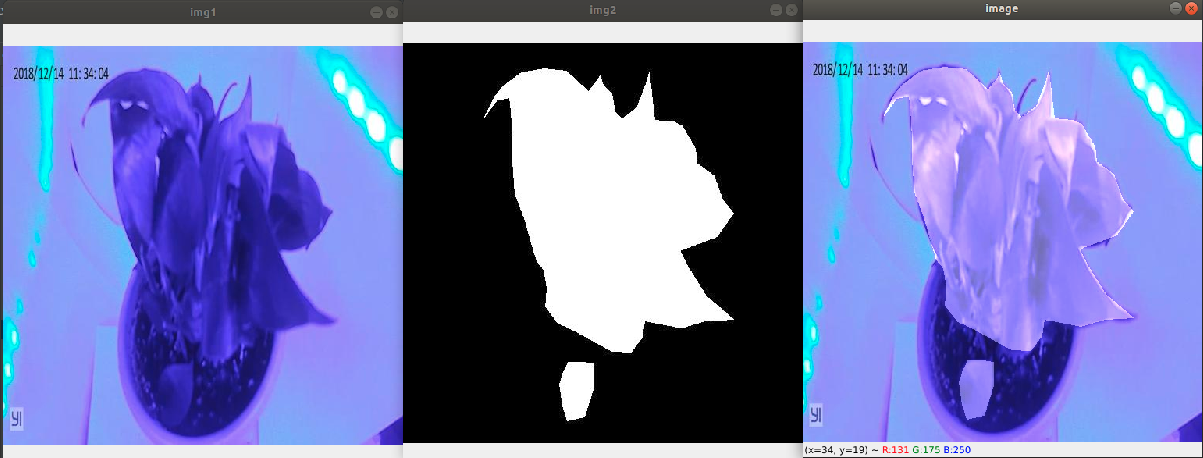
- 下面一并附上图像融合代码
import cv2
import numpy as np
src = "/home/linxu/下载/flow_dataset/image/30.jpg"
mask = "/home/linxu/下载/flow_dataset/output.png"
# 使用opencv叠加图片
img1 = cv2.imread(src)
img2 = cv2.imread(mask)
alpha = 1
meta = 0.4
gamma = 0
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
image = cv2.addWeighted(img1,alpha,img2,meta,gamma)
cv2.imshow('image', image)
cv2.waitKey(0)
参考:https://blog.csdn.net/jcfszxc/article/details/106289555
[炼丹术]UNet图像分割模型相关总结的更多相关文章
- Java内存模型相关原则详解
在<Java内存模型(JMM)详解>一文中我们已经讲到了Java内存模型的基本结构以及相关操作和规则.而Java内存模型又是围绕着在并发过程中如何处理原子性.可见性以及有序性这三个特征来构 ...
- U-net图像分割
[Keras]基于SegNet和U-Net的遥感图像语义分割 2014 年,加州大学伯克利分校的 Long 等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN ...
- css 盒模型相关样式
话不多说,一切还是从最基础的说起. 盒的类型 1.盒的基本类型 在css中,用display定义盒的类型,一般分为block类型与inline类型. 例如div属于block类型,span属于in ...
- django模型相关的知识点
定义属性 概述: django根据属性的类型确定以下信息 当前选择的数据库支持字段的类型 渲染管理表单时使用的默认html控件 在管理站点最低限度的验证 django会为表增加自动增长的主键列,每个模 ...
- Huber-Markov先验模型相关
随机概率重建-MAP算法 随机概率重建:利用贝叶斯理论作为框架,理想图像的先验知识作为约束条件进行图像重建.常用的随机概率超分辨率重建包括最大后验概率估计法(MAP)和极大似然估计法(ML). MAP ...
- UVM——寄存器模型相关的一些函数
0. 引言 在UVM支持的寄存器操作中,有get.update.mirror.write等等一些方法,在这里整理一下他们的用法. 寄存器模型中的寄存器值应该与DUT保持同步,但是由于DUT的值是实时更 ...
- django—模型相关
配置数据库信息 1.settings配置 DATABASES = { "default": { "ENGINE": "djan ...
- JMM内存模型相关笔记整理
JMM 内存模型是围绕并发编程中原子性.可见性.有序性三个特征来建立的 原子性:就是说一个操作不能被打断,要么执行完要么不执行,类似事务操作,Java 基本类型数据的访问大都是原子操作,long 和 ...
- iscsi模型相关点
1.iscsi即ip scsi,按架构分为控制器架构.链接桥系统架构.pc系统架构.这里主要说明一下pc系统架构. 所谓的pc系统架构,就是利用target软件存储端+initiator客户端+tcp ...
随机推荐
- CentOS7 安装配置RocketMQ --主从模式(master-slave)异步复制
机器信息 192.168.119.129 主 192.168.119.128 从 配置host[两台机器] vim /etc/hosts 添加 192.168.119.129 rocketmq-nam ...
- [PE结构]导出表结构浅析
导出函数的总数-->以导出函数序号最大的减最小的+1,但导出函数序号是可自定义的,所以NumbersOfFunctions是不准确的 1.根据函数名称找,函数名称表->对应索引函数序号表中 ...
- 在JTable单元格上 加入组件,并赋予可编辑能力 [转]
表格(单元格放置组件) 对于JTable单元格的渲染主要是通过两个接口来实现的,一个是TableCellRenderer另一个是TableCellEditor,JTable默认是用的是DefaultC ...
- C++中union相关
前两天做阿里笔试遇到一个选择题题目大概是 #include <iostream> #include <stdlib.h> using namespace std; union ...
- 4.3 rust func closure
fn add_one_v1 (x: u32) -> u32 { x + 1 } let add_one_v2 = |x: u32| -> u32 { x + 1 }; let add_on ...
- Output of C++ Program | Set 6
Predict the output of below C++ programs. Question 1 1 #include<iostream> 2 3 using namespace ...
- Spring是如何保证同一事务获取同一个Connection的?使用Spring的事务同步机制解决:数据库刚插入的记录却查询不到的问题(转)
前言 关于Spring的事务,它是Spring Framework中极其重要的一块.前面用了大量的篇幅从应用层面.原理层面进行了比较全方位的一个讲解.但是因为它过于重要,所以本文继续做补充内容:Spr ...
- 特定场景下的PLC 远程控制和数据读取
最近有位博友提出了一种应用场景,根据工作中实际遇到的类似的产品应用场景,记录下自己的解决方案. 场景: 需要在云端控制和采集各个站点的PLC数据.各个站点是分散的,每个站点有公网访问能力,但是分散站点 ...
- Python基础入门(5)- 函数的定义与使用
定义函数 函数的定义 函数的分类 函数的创建方法 函数的返回return 函数的定义 将一件事情的步骤封装在一起并得到最终结果 函数名代表了这个函数要做的事情 函数体是实现函数功能的流程 函数可以帮助 ...
- Git忽略提交规则 .gitignore文件
在使用Git的过程中,我们喜欢有的文件比如日志,临时文件,编译的中间文件等不要提交到代码仓库,这时就要设置相应的忽略规则,来忽略这些文件的提交.简单来说一个场景:在你使用git add .的时候,遇到 ...