You Only Look One-level Feature
你只需要看一个层次的特征
摘要:本文回顾了单阶段检测器的特征金字塔网络(FPN),指出FPN的成功在于其对目标检测优化问题的分治解决,而不是多尺度特征融合。从优化的角度来看,我们引入了一种替代的方法来解决这个问题,而不是采用复杂的特征金字塔,这个方法就是利用一个层次的特征进行检测。在简单有效的基础上,提出了You Only Look One-level Feature (YOLOF)。在我们的方法中,提出了两个关键组件,膨胀编码器和均匀匹配,并带来了相当大的改进。在COCO基准上的大量实验证明了所提模型的有效性。我们的YOLOF与它的特征金字塔对应的RetinaNet取得了相当的结果,而且速度快2.5倍。在没有transformer层的情况下,YOLOF可以以单级特征方式匹配DETR的性能,训练迭代次数少于7。在608 × 608的图像尺寸下,YOLOF在2080Ti上以60fps的速度实现了44.3 mAP,比YOLOv4快13%。代码可在https://github.com/megvii-model/YOLOF获得。
1.引言
在最先进的两级检测器[22,13,3]和一级检测器[23,38]中,特征金字塔成为一个重要组成部分。构建特征金字塔最常用的方法是特征金字塔网络(FPN)[22],其主要带来两个好处:(1)多尺度特征融合:融合多个低分辨率和高分辨率特征输入,获得更好的表征;(2)分治法:对不同层次的目标进行检测与目标尺度有关。人们普遍认为FPN的成功依赖于多层特征的融合,由此引出了一系列人工设计复杂融合方法的研究[25,17,28],或通过神经结构搜索(Neural Architecture Search, NAS)算法[9,37]。然而,这种忽略了分治法在FPN中的作用。这导致关于 这两种益处如何促进FPN成功的研究较少,并可能阻碍新的进展。
本文研究了FPN的两大优点对单级探测器的影响。我们通过将多尺度特征融合和分治功能与RetinaNet[23]解耦设计实验。详细地说,我们认为FPN是一种多入多出(MiMo)编码器,它编码来自主干网的多尺度特征,并为解码器(检测头)提供特征表示。我们在图1对多入多出(MiMo)、单入多出(SiMo)、多入单出(MiSo)和单入单出(SiSo)进行对比。令人惊讶的是,只有一个输入特征C5且没有进行特征融合的SiMo编码器可以达到与MiMo编码器(即FPN)相当的性能。性能差距小于1 mAP。相比之下,MiSo和SiSo编码器的性能显著下降(≥12 mAP)。这些现象表明了两个事实:(1)C5特征携带了足够的上下文来检测各种尺度上的对象,这使SiMo编码器能够获得可比的结果;(2)多尺度特征融合的效益远不如分治的效益重要,多尺度特征融合可能不是FPN的最大效益,ExFuse[50]在语义分割方面也证明了这一点。再深入一点,分治法与目标检测中的优化问题有关。它将复杂的检测问题按目标尺度划分为若干个子问题,便于优化过程。
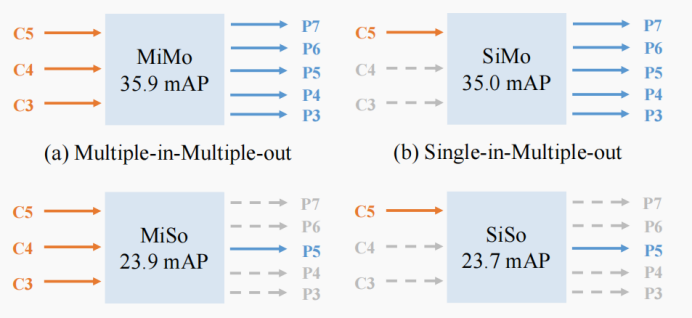
图1所示:比较在COCO验证集上多入多出(MiMo)、单入多出(SiMo)、多入单出(MiSo)和单入单出(SiSo)编码器之间的框AP。这里,我们采用原始的RetinaNet[23]作为我们的基线模型,其中C3, C4, C5表示骨干输出特征,下采样率为{8,16,32},P3 ~ P7表示用于最终检测的特征级别。图中报告的所有结果都使用相同的主干ResNet-50[14]。MiMo的结构与RetinaNet[23]中的FPN相同。所有编码器的结构的详细说明见图8。
上述分析表明,FPN成功的根本因素是它解决了目标检测中的优化问题。分治法是一种好方法。但是它带来了内存负担,减慢了探测器的速度,使像RetinaNet[23]这样的一级探测器的探测器结构变得复杂。鉴于C5特性携带了足够的检测上下文,我们展示了一种简单的方法来解决优化问题。
我们提出You Only Look one -level Feature (YOLOF),它只使用一个C5特征(下采样率为32)进行检测。为了弥补SiSo编码器和MiMo编码器之间的性能差距,我们首先设计了适当的编码器结构,以提取不同尺度上的目标的多尺度上下文,弥补多尺度特征的不足;然后,我们采用统一匹配机制来解决稀疏锚点在单一特征中引起的正锚点不平衡问题。
没有铃声和哨子,YOLOF实现了与它的特征金字塔对应的RetinaNet[23]相当的结果,但快2.5倍。在单一的特征方式下,YOLOF匹配了最近提出的DETR[4]的性能,同时收敛速度更快(7×)。利用608×608的图片大小和其他技术[1,47],在2080Ti上实现44.3 mAP,以60帧每秒的速度运行,比YOLOv4[1]快13%。简而言之,本文的贡献是:
1)我们证明了FPN最显著的优点是它的分治解决优化问题的密集目标检测,而不是多尺度特征融合。
2)我们提出了YOLOF,这是一个简单而有效的基线,不使用FPN。在YOLOF,我们提出了两个关键组件,膨胀编码器和统一匹配,弥合了SiSo编码器和MiMo编码器之间的性能差距。
3)对COCO基准的大量实验表明了各构件的重要性。此外,我们还与RetinaNet[23]、DETR[4]和YOLOv4[1]进行了比较。我们可以在gpu上用更快的速度实现类似的结果。
2.相关工作
多层次特征检测器。利用多特征进行目标检测是一种传统的方法。构造多特征的典型方法可以分为图像金字塔法和特征金字塔法。在前深度学习时代,基于图像金字塔的检测器(如DPM[8])占据了检测的主导地位。在基于CNN的检测器中,图像金字塔方法也获得了一些研究人员的好评[34,35],因为它可以实现更高的性能开箱即用。然而,图像金字塔法并不是获取多种特征的唯一方法;在CNN模型中,利用特征金字塔的能力是更加有效和自然的。SSD[26]首先利用多尺度特征,针对不同尺度的对象在每个尺度上进行目标检测。FPN[22]遵循SSD[26]和UNet[33],结合浅层特征和深层特征构建语义丰富的特征金字塔。在此之后,一些工作[17,25,9,37]遵循FPN,关注如何获得更好的表示。FPN成为现代探测器的重要组成部分。它也适用于流行的一级探测器,如RetinaNet[23],FCOS[38]和它们的变体[48]。另一种获取特征金字塔的方法是利用多分支扩张卷积[20]。与上述工作不同的是,我们的方法是一个单层的特征检测器。
单一特征的探测器。早期的R-CNN系列[11,10,31]和R-FCN[6]只在单个特征上提取RoI特征,其性能落后于多特征检测器[22]。此外,在一级检测器中,YOLO[29]和YOLOv2[30]只使用骨干的最后一个输出特征。它们可以非常快,但在检测时必须承受性能下降。CornerNet[19]和CenterNet[51,7]遵循这种方式,并在使用一个降采样率为4的单一特征来检测所有目标时获得竞争结果。使用高分辨率特征图进行检测会带来巨大的内存成本,并且对部署不友好。最近,DETR[4]引入了transformer[39]来检测,并表明它只使用一个C5特性就可以达到最先进的结果。由于完全无锚机制和transformer学习阶段,DETR需要长时间训练才能收敛。由于长时间训练的特点,进一步改进非常繁琐。与这些论文不同的是,我们研究了多级检测的工作机制。从优化的角度出发,为广泛应用的FPN提供了一种替代方案。此外,YOLOF收敛速度更快,具有良好的性能;因此,YOLOF可以作为快速、准确检测的简单基线。
3.MiMo编码器的成本分析
如第1节所述,FPN在密集目标检测中的成功在于它解决了优化问题。然而,多级特征范式不可避免地会使检测器变得复杂,带来内存负担,并使检测器速度变慢。在本节中,我们对MiMo编码器的成本进行了定量研究。
我们设计了基于RetinaNet的ResNet-50[14]的实验。具体地说,我们将检测任务的管道格式化为三个关键部分的组合:骨干网络、编码器和解码器(图2)。在这个视图中,我们在图3中显示了每个组件的FLOPs。与SiSo编码器相比,MiMo编码器给编码器和解码器带来了巨大的内存负担(134G vs. 6G)(图3)。携带MiMo编码器的检测器比SiSo运行慢得多(13 FPS与34 FPS)(图3)。速度慢是由于检测对象检测器的高分辨率特征图谱与MiMo编码器,如C3特性(下采样率为8)。鉴于上述缺点的MiMo编码器,我们的目的是在保持检测器简单、准确和快速的同时,寻找另一种方法来解决优化问题。

图2:检测管道的图解。在本文中,我们将检测管道分为三部分:(1)骨干;(2)编码器,其接收来自主干网的输入并分发表征以进行检测;(3)解码器,执行分类和回归任务,生成最终的预测框。编码器的颜色与图1中的颜色相对应。
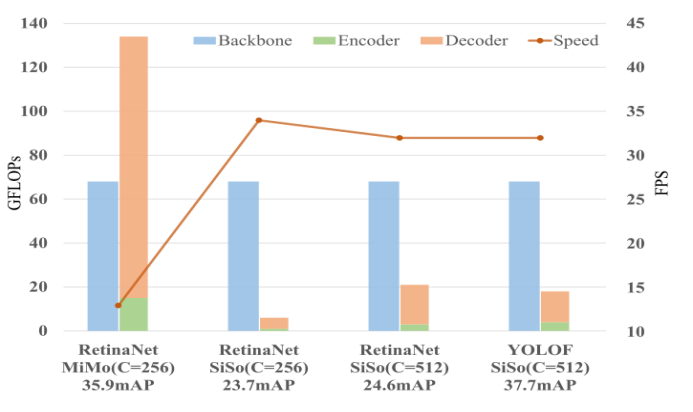
图3:对采用MiMo和SiSo编码器的模型进行了FLOPs、精度和速度的比较。由于译码器的FLOPs受到编码器输出的影响,为了更好地理解编码器对FLOPs的影响,我们将编码器的FLOPs和译码器的FLOPs叠加在图中。所有模型使用相同的骨干ResNet-50。在COCO val2017的前100张图片中,所有的FLOPs都采用了较短的边缘尺寸800。FPS是根据Detectron2[42]中报告的总推断纯计算时间在2080Ti上以批量大小为1计算的。在图中,C表示模型的编码器和解码器中使用的通道数。
4.思想
基于上述目的,以及发现C5特性包含足够的上下文来检测众多对象,我们在本节中尝试用简单的SiSo编码器来替代复杂的MiMo编码器。但是这种替换并不简单,因为根据图3中的结果,当应用SiSo编码器时,性能会大幅下降。在这种情况下,我们仔细分析了阻碍SiSo编码器比MiMo编码器获得相当性能的原因。我们发现SiSo编码器带来的两个问题是导致性能下降的原因。第一个问题是与C5特征的接受域匹配的尺度范围有限,这阻碍了对不同尺度目标的检测性能。二是单级特征中稀疏锚点引起的正锚点不平衡问题。接下来,我们将对这两个问题进行详细的讨论并给出我们的解决方案。
4.1 限制尺度范围
在不同的尺度下识别目标是目标检测的一个基本挑战。一个可行的解决方案是利用多级特性。在采用MiMo或SiMo编码器的探测器中,它们利用不同的接受域(P3-P7)构建多层次特征,并在接受域与其尺度匹配的水平上检测物体。然而,单一级别的功能设置改变了游戏。在SiSo编码器中只有一个输出特性,它的接收域是一个常量。如图4(a)所示,C5功能的感受域只能覆盖一个有限的范围,如果物体的尺度与感受域不匹配,就会导致表现不佳。为了实现用SiSo编码器检测所有对象的目标,我们必须找到一种方法来生成具有不同接受域的输出特征,以弥补多层特征的不足。
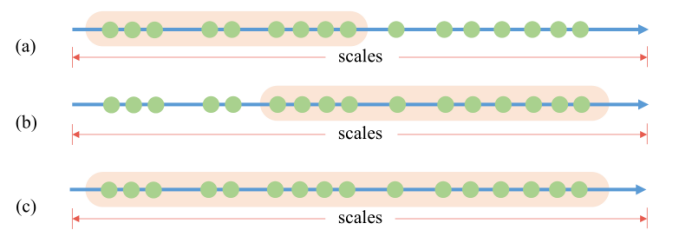
图4:一个简单的例子,演示了对象尺度和单个特性覆盖的尺度范围之间的关系。图中的轴表示刻度。(a)表示特征的接受域只能覆盖有限的范围;(b)表明放大的比例尺范围使特征能够覆盖大的目标,而没有覆盖小的目标;(c)表示所有量表都可以覆盖有多个接受域的特征。
我们首先通过堆叠标准卷积和扩张卷积[45]来扩大C5功能的接受域。覆盖的尺度范围虽然有所扩大,但仍不能覆盖所有对象的尺度,因为扩大过程将大于1的因子乘以原来覆盖的所有尺度。我们举例说明图4(b)的情况,整个标度范围比图4(a)的更大。然后,通过添加相应的特征,将原尺度范围和扩大的尺度范围相结合,得到一个包含多个接受域的输出特征,覆盖所有对象尺度(图4(c))。通过在中间3 × 3卷积层上构造膨胀的残差块[14],可以很容易地实现上述操作。
扩张型编码器:基于上述设计,我们提出了图5中的SiSo编码器,命名为扩张型编码器。它包含两个主要组件:投影仪和剩余块。投影层首先应用一个1 × 1卷积层来降低信道维数,然后添加一个3×3卷积层来细化语义上下文,这与FPN的[22]相同。然后,我们在3 × 3卷积层中逐次叠加4个不同膨胀率的膨胀残块,生成具有多个接受域的输出特征,覆盖所有对象的尺度。

图5:放大编码器的结构说明。其中1×1、3×3为1×1、3×3卷积层,×4为连续四个残块。在残差块中,所有的卷积层后面都有一个批范层[15]和一个ReLU层[27],而在投影仪中,我们只使用卷积层和批范层[15]。
讨论:扩张卷积[45]是在目标检测中扩大特征接收场的常用策略。如第2节所述,TridentNet[20]使用扩展卷积来生成多尺度特征。通过多分支结构和权值共享机制实现目标检测中的尺度变化问题,有别于我们的单级特征设置。此外,扩展编码器堆栈逐个扩展剩余块而不共享权值。虽然DetNet[21]也陆续应用了膨胀残块,但其目的是保持特征的空间分辨率,并在主干输出中保留更多的细节,而我们的目的是在主干之外生成具有多个接受域的特征。膨胀编码器的设计使我们可以检测所有对象的单一层次的特征,而不是多层次的特征,如TridentNet[20]和DetNet[21]。
4.2 正锚框的不平衡问题
正锚的定义是目标检测优化问题的关键。在基于锚点的检测器中,定义阳性的策略主要是通过测量锚点和ground-truth boxes之间的IoUs。在视网膜网络[23]中,如果anchor和groundtruth box的max IoU大于阈值0.5,则将该anchor设置为正。我们称之为最大匹配。
在MiMo编码器中,锚点以密集铺装的方式预先定义在多个层次上,ground-truth box在特征层次上生成与其尺度相对应的正锚点。基于分治机制,Max-IoU匹配可以使每个尺度的ground-truth box产生足够数量的正锚。然而,当我们采用SiSo编码器时,锚点数量比MiMo编码器中锚点数量大大减少,从100k减少到5k,导致了稀疏锚点1。在使用Max-IoU匹配时,稀疏锚点给检测器带来了匹配问题,如图6所示。在自然界中,大的地物箱比小地物箱诱导更多的正锚,这导致了正锚不平衡的问题。这种不平衡使得探测器在训练时只注意大的ground-truth boxes而忽略了小的ground-truth boxes。
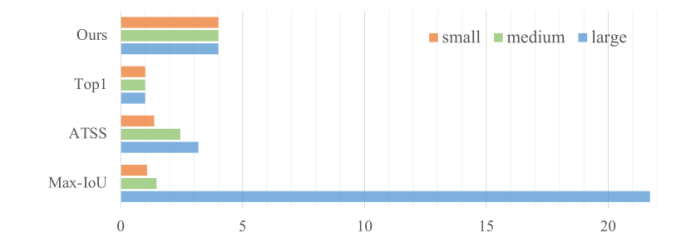
图6:生成的正锚点在单一特征的各种匹配方法中的分布。此图旨在显示产生的正锚的平衡性。Max-IoU中的正锚被大型的ground-truth box所主导,导致了物体尺度上的巨大不平衡。ATSS通过在训练时自适应抽取正锚来缓解不平衡问题。Top1和Ours采用统一匹配,以平衡的方式产生积极的锚点,无论大小物体。
均匀匹配:为了解决正锚不平衡的问题,我们提出了均匀匹配策略:采用k最近的锚作为每个真实积极的锚箱,确保所有groundtruth盒子可以与相同数量的积极锚均匀不管他们的大小(图6)。平衡真实积极确保所有样品盒参与培训和同样的贡献。此外,在Max-IoU匹配[23]之后,我们在均匀匹配中设置IoU阈值,忽略大IoU(>0.7)的负锚和小IoU(<0.15)的正锚。
讨论:与其他匹配方法的关系。在匹配过程中应用topk并不是什么新鲜事。TSS[48]首先在L个特征层次上为每个ground-truth box选择topk锚点,然后通过动态IoU阈值在k × L个候选对象中抽取正锚点。然而,A TSS侧重于自适应地定义正样本和负样本,而我们的统一匹配侧重于用稀疏锚点在正样本上实现平衡。虽然以前的几种方法在阳性样本上实现了平衡,但它们的匹配过程并没有针对这种不平衡问题设计。例如,YOLO[29]和YOLOv2[30]将ground-truth box与最匹配的cell或anchor匹配;DETR[4]和[36]采用匈牙利算法[18]进行匹配。这些匹配方法可以被视为top1匹配,这是我们统一匹配的具体情况。更重要的是,统一的匹配和learning-to-match方法之间的区别是:learning-to-match方法,如FreeAnchor[49]和PAA[16],自适应显示单独的锚为阳性和阴性的学习状态,而统一的匹配是固定的,不发展与培训。针对SiSo设计中存在的锚点不平衡问题,提出了均匀匹配方法。图6与表5e结果的对比说明了在SiSo编码器平衡正样本上的重要性。
4.3 YOLOF
在上述解决方案的基础上,我们提出了一个快速和简单的框架单级特征,表示为YOLOF。我们将YOLOF格式化为三部分:骨干、编码器和解码器。YOLOF示意图如图9所示。在本节中,我们将简要介绍YOLOF的主要组成部分。
骨干网络。在所有的模型中,我们简单地采用ResNet[14]和ResNeXt[43]系列作为我们的骨干。所有模型都在ImageNet上进行预训练。主干的输出是C5 feature map,它有2048个通道,下采样率为32。为了与其他探测器进行公平比较,骨干中的所有批规范层默认都是冻结的。
编码器。对于编码器(图5),我们首先按照FPN,在主干后添加两个投影层(一个1 × 1和一个3 × 3卷积),得到一个512通道的feature map。然后,为了使编码器的输出特征覆盖各种尺度上的所有对象,我们提出添加残差块,残差块由三个连续卷积组成:前1 × 1卷积对接收场进行信道减少,减少率为4;后3 × 3卷积对接收场进行扩张性放大;最后1 × 1卷积恢复接收场的信道数。
译码器。对于解码器,我们采用了retina et的主要设计,它由两个并行的任务特定的头组成:分类头和回归头(图9)。我们只增加了两个小的修改。第一个是我们遵循DETR[4]中FFN的设计,使两个头部的卷积层数不同。在回归头上有四个卷积,然后是批处理归一化层和ReLU层,而在分类头上只有两个。第二,我们遵循Autoassign[52],并为回归头上的每个锚添加一个隐式对象预测(没有直接监督)。所有预测的最终分类分数是通过将分类输出与相应的隐式目标度相乘而产生的。
其他细节。如前所述,在YOLOF中预定义的锚点是稀疏的,降低了锚点与ground-truth box之间的匹配质量。我们在图像上添加一个随机移位操作来规避这个问题。该操作将图像在左、右、上、下三个方向随机移动,最大移动32个像素,目的是将噪声注入到图像中目标的位置,增加ground-truth box与高质量锚点匹配的概率。此外,我们发现在使用单一层次特征时,对锚点中心位移的限制也有助于最终的分类。我们增加了一个限制,所有锚点的中心位移应该小于32像素。
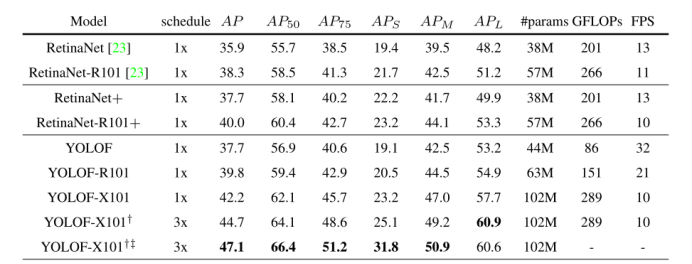
表1:与RetinaNet在COCO2017验证集上的比较。上面的部分显示了视网膜网络的结果。中间部分给出了改进的RetinaNet(带“+”)的结果,即GIoU[32]、GN[41]和隐式objectness的RetinaNet。最后一节展示了各种YOLOF模型的结果。表中以R101或X101为后缀的模型表示使用ResNet-101[14]或RetNeXt-101-64×4d[43]作为骨干。对于没有后缀的,默认采用ResNet-50[14]。在最后两行中,我们使用了多尺度训练和测试技术(†表示多尺度训练,传统意味着多尺度测试),其设置跟随HTC[5]。关于设置的更多细节可以在附录中找到。在最后三列中,我们展示了模型的参数数量(#params)、GFLOPs和推理速度。在COCO val2017的前100张图片中,所有的FLOPs都采用了较短的边缘尺寸800。此外,表中的FPS是根据Detectron2[42]中报告的总推断纯计算时间在2080Ti上以批大小1计算的。
5.实验
我们在MS COCO[24]基准上评估我们的YOLOF,并与RetinaNet[23]和DETR[4]进行比较。然后,我们提供了详细的烧蚀研究各部件的设计和定量的结果和分析。最后,为进一步研究单水平检测,我们提供了误差分析,并指出了与DETR[4]相比的不足之处。具体情况如下。
实现细节。YOLOF在8个GPU上使用同步SGD进行训练,每个小批总共64张图像(每个GPU 8张图像)。所有模型的初始学习率为0.12。此外,我们根据DETR[4]为骨干设置了一个更小的学习速率,即基础学习速率的1/3。为了在一开始稳定训练,我们将热身迭代的次数从500次增加到1500次。对于训练计划,随着batch size的增加,YOLOF中的“1×”计划设置总共是22.5k次迭代,在15k和20k次迭代中,基学习率下降了10。其他时间表根据detectron2[42]的原则进行调整。对于模型推理,我们使用阈值为0.6的NMS对结果进行后处理。对于其他超参数,我们遵循视网膜网络[23]的设置。
5.1 与之前工作比较
与RetinaNet比较:做一个公平的比较,我们使RetinaNet与YOLOF采用广义借据箱损失[32],添加一个隐式对象的预测和应用组标准化层[41]在正面(只有两个图片/ GPU和BN[15]和SyncBN[46]给贫穷导致RetinaNet2,我们用GN[41]代替BN[15])。结果如表1所示。所有的“1×”模型都以单一的比例进行训练,短边设置为800像素,长边最多为1333[23]。在上面的部分,我们给出了用Detectron2[42]训练的视网膜网络基线结果。在中间部分,我们展示了改进的视网膜网络基线的结果(带“+”),其设置与YOLOF对齐。在最后一节中,我们展示了来自多个YOLOF模型的结果。多亏了单级特性,YOLOF与RetinaNet+取得了相同的结果,减少了57%的错误次数(如图3所示),速度提高了2.5倍。由于C5特征的大步幅(32),在小物体上,YOLOF的性能(−3.1)低于retina et+。然而,由于我们在编码器中添加了膨胀的残块,YOLOF在大对象(+3.3)上取得了更好的性能。与ResNet-101[14]相比,RetinaNet+和YOLOF也有相似的证据。虽然在小对象上应用相同的骨干网时,YOLOF不如RetinaNet+,但是在相同的运行速度下,它可以用更强的骨干网ResNeXt[43]来匹配小对象的性能。并证明了该方法与现有的目标检测技术是兼容和互补的,在表1的最后两行中,我们展示了使用多尺度图像和更长的时间表进行训练的结果。最后,在多尺度测试的帮助下,我们得到了我们的最终结果为47.1 mAP和31.8 mAP在小目标上的竞争性能。
与DETR进行比较。DETR[4]是最近提出的一种检测器,它将变压器[39]引入对象检测。在COCO基准[24]上取得了令人惊讶的结果,并首次证明了仅采用一个C5特征,就可以达到与多级特征检测器(Faster R-CNN w/ FPN[22])相当的结果。考虑到这一点,人们可能会期望,需要像变压器层[39]这样的层来实现单层特征检测的有希望的结果。然而,我们证明了一个具有局部卷积层的传统网络也可以实现这一目标。我们在表2中比较了DETR与全局层、YOLOF与局部卷积层。研究结果表明,YOLOF匹配了DETR的性能,并且YOLOF比DETR (w/ ResNet-50(−0.4)vs. w/ ResNet-101(+0.2))从更深的网络中获得更多的收益。有趣的是,我们发现YOLOF在小对象(+1.9和+2.4)上优于DETR,而在大对象(-3.5和-2.9)上落后于DETR。这一发现与上述本地和全球的讨论一致。更重要的是,与DETR相比,YOLOF收敛速度快得多(约为7×),这使得它比DETR更适合作为单级检测器的简单基线。
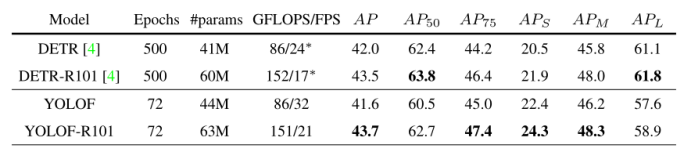
表2:与DETR在COCO2017验证集上的比较。我们对主干ResNet-50(无后缀)和ResNet-101(有后缀R101)进行了比较。为公平比较,YOLOF采用多尺度训练(同表1),训练时间为“6×”,约为72 epoch。对于DETR的FPS,∗意味着我们遵循原始论文[4]中的方法,并在2080Ti上重新测量它。
与YOLOv4进行比较。YOLOv4[1]是一种速度和精度最佳的多级特征检测器。它结合了许多技巧来达到最先进的结果。由于我们的目的是为单级检测器建立一个简单而快速的基线,对免费技巧包的调查超出了这项工作的范围。因此,我们不期望对性能进行严格一致的比较。比较与YOLOv4 YOLOF,我们应用YOLOv4数据扩增方法,采用三相培训管道,相应地修改培训设置,添加相呼应的最后阶段(表3)YOLOF-DC5支柱。更多关于模型和训练的技术细节设置在附录中给出。如表3所示,YOLOF-DC5的运行速度比YOLOv4快13%,整体性能提高了0.8 mAP。YOLOFDC5在小对象上的竞争结果低于YOLOv4 (24.0 mAP vs. 26.7 mAP),而在大对象上的性能则明显优于YOLOv4 (+7.1 mAP)。上述结果表明,单电平探测器具有同时达到最先进速度和精度的巨大潜力。

表3:与YOLOv4在COCO测试开发集上的比较。我们用“15×”(184 epoch)的时间表训练YOLOF-DC5,并将其与YOLOv4进行比较。在表中,†表示通过跟随YOLOv4[1]测量YOLOF-DC5的FPS。这与本文表1、表2的方法不同。在YOLOv4[1]中,作者融合了卷积层和批归一化层,然后将模型转换为半精度后度量推理时间。∗表示我们从官方回购协议中获得YOLOv4在2080Ti上的速度https: //github.com/AlexeyAB/darknet#geforce- rtx2080-ti。
5.2 消融实验
我们进行了多次烧蚀来分析YOLOF。我们首先提供对这两个提议的组件的总体分析。然后,通过烧蚀实验对各部件进行了详细设计。结果如表4、5所示,并在接下来进行了详细讨论。
膨胀编码器与均匀匹配:从表4可以看出,膨胀编码器与均匀匹配对YOLOF都是必要的,可以带来相当大的改进。其中,extended Encoder对大型对象的影响比较显著(43.8 vs. 53.2),对中小型对象的结果略有改善。结果表明,C5特征的尺度范围有限是一个严重的问题(Section 4.1)。我们的扩张式编码器提供了一个简单但有效的解决方案。另一方面,由于没有统一匹配,中小型对象的性能显著下降(约10AP),而大型对象的性能仅受到轻微影响。这一发现与4.2节中分析的正锚不平衡问题是一致的。阳性锚点以大物体为主,导致中小物体效果不佳。最后,当我们同时删除了expanded Encoder和Uniform Matching时,一个单一级别的特性检测器的性能将下降到图1和图3中所示的结果。
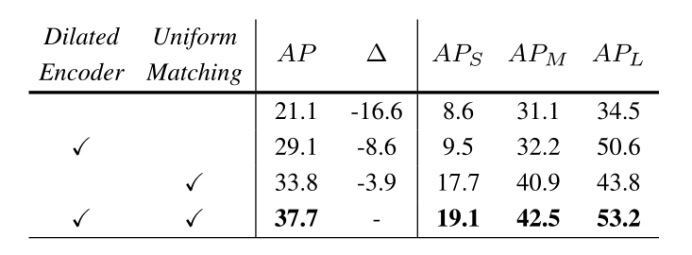
表4:ResNet-50扩张型编码器及均匀匹配的效果。这两个组件将原来的单电平检测器提高了16.6 mAP。注意,表中21.1 mAP的结果不是一个bug。它的性能略差于图1和图3中SiSo编码器的探测器,这是由于YOLOF中译码器的设计-在分类头中只有两个卷积层。
ResBlock的数量:YOLOF堆栈剩余的块在SiSo编码器。从表5a的结果可以看出,堆叠更多的block对于大的对象有很大的改善,这是由于feature scale range的增加。虽然我们观察到更多块的持续改进,但我们选择添加四个剩余块,以保持YOLOF简单和整洁。
不同的卷积层:根据4.1节的分析,为了使C5特征能够覆盖更大的尺度,我们将残差块中的标准3 × 3卷积层替换为相应的扩展层。我们在表5b中展示了剩余块体不同膨胀情况下的结果。对剩余块体进行膨胀可以改善YOLOF,但膨胀过大时,改善效果饱和。我们推测这种现象的原因是,2、4、6、8的膨胀足以匹配所有图像中的物体尺度。
是否添加快捷方式:表5c显示快捷方式在Dilated Encoder中起着至关重要的作用。如果我们删除残留块中的捷径,所有对象的性能都会显著下降。根据第4.1节,快捷键组合了不同的刻度范围。该特征覆盖的尺度范围大且密集,是以单一层次特征方式检测所有目标的关键因素。
正样本数量:ground-truth box诱导阳性锚的数量比较见表5d。从直观上看,越是积极的锚点,越能获得更好的性能,因为样本越多,学习就越容易。因此,在我们的统一匹配方式中,我们经验地增加了每个ground-truth box诱导的正锚的数量。如表5d所示,当k大于1时,超参数k对性能的鲁棒性非常强,这可能说明最重要的是YOLOF匹配方式的均匀性。我们选择top4作为我们的制服匹配,因为根据结果它是最好的选择。
均匀匹配与其他匹配:我们对YOLOF的均匀匹配与其他匹配策略进行了比较,结果见表5e。所提出的均匀匹配策略可以获得最好的结果,与图6中的不平衡分析相一致。值得注意的是,匈牙利的匹配策略可以粗略地视为Top1匹配(表5d),因此它们的性能相似。它们之间的区别是,在匈牙利匹配中,一个锚只匹配一个对象,而Top1匹配没有这个约束,实验表明这并不重要。原始的A TSS发现top9锚点是最好的选择,而我们发现top15锚点在单级特征检测器中要好得多。通过使用top15 anchor, ATSS取得了36.5 mAP的好成绩,但仍然落后于我们的uniform matching 1.2 mAP的差距。
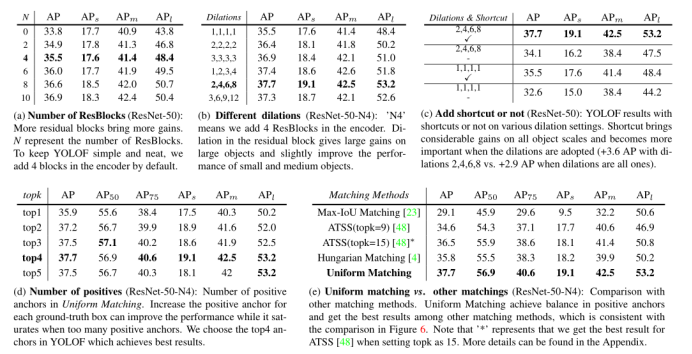
表5所示:消融。我们用ResNet-50在COCO2017 val上进行了膨胀编码器和均匀匹配的烧蚀实验。
5.3 误差分析
我们在本节中增加了对YOLOF的误差分析,以便为未来的单级特征检测研究提供见解。我们采用最近提出的工具TIDE[2]来比较YOLOF和DETR[4]。如图7所示,DETR比YOLOF在定位上有更大的误差,这可能与它的回归机制有关。DETR以完全自由锚点的方式回归目标,并对图像中的全局位置进行预测,这给定位带来了困难。相比之下,YOLOF依赖于预先定义的锚点,这是比DETR[4]在预测中更高的遗漏误差。根据4.2节的分析,在推断阶段,YOLOF的锚点较为稀疏,不够灵活。直觉上,有些情况下,没有预先定义的高质量锚。因此,在YOLOF中引入无锚定机制可能有助于缓解这一问题,我们将其留到以后的工作中。
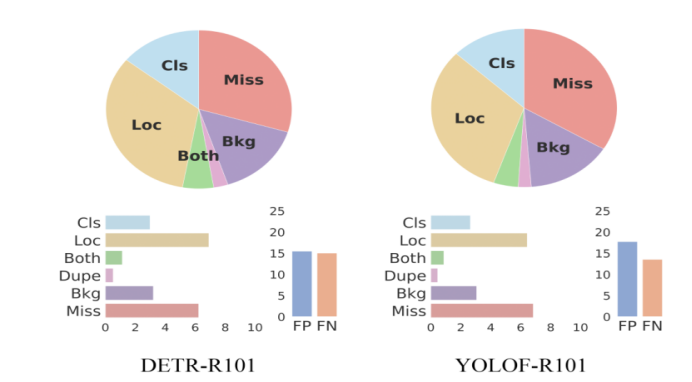
图7:DETR-R101和YOLOF-R101的误差分析。根据TIDE[2],图中显示了六种错误类型(Cls:分类错误;Loc:定位错误;Both: cls和loc错误;重复预测错误;Bkg:背景误差;小姐:失踪的错误)。饼图显示了每个误差的相对贡献,而柱状图显示了它们的绝对贡献。FP和FN分别为假阳性和假阴性。
6.结论
在这项工作中,我们发现FPN的成功是由于它的分治解决稠密目标检测的优化问题。考虑到FPN使网络结构复杂,内存负担大,检测器速度慢,我们提出了一种简单而高效的方法,即不使用FPN来解决不同的优化问题,称为YOLOF。我们通过与RetinaNet和DETR进行比较来证明其有效性。我们希望我们的YOLOF可以作为一个坚实的基线,并在未来的研究中为设计单级特征检测器提供见解。
You Only Look One-level Feature的更多相关文章
- Software: MPEG-7 Feature Extraction Library
Software MPEG-7 Feature Extraction Library : This library is adapted from MPEG-7 XM Reference Softwa ...
- Image Processing and Computer Vision_Review:Local Invariant Feature Detectors: A Survey——2007.11
翻译 局部不变特征探测器:一项调查 摘要 -在本次调查中,我们概述了不变兴趣点探测器,它们如何随着时间的推移而发展,它们如何工作,以及它们各自的优点和缺点.我们首先定义理想局部特征检测器的属性.接下来 ...
- CNN 入门学习资料整理
建议按序阅读 1. Convolutional Neural Networks卷积神经网络: http://blog.csdn.net/zouxy09/article/details/8781543 ...
- (转)The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
Adit Deshpande CS Undergrad at UCLA ('19) Blog About The 9 Deep Learning Papers You Need To Know Abo ...
- JavaScript Modules
One of the first challenges developers new to JavaScript who are building large applications will ha ...
- 第三弹:ZFNet
在所有深度网络中,卷积神经网和图像处理最为密切相关,卷积网在很多图片分类竞赛中都取得了很好的效果,但卷积网调参过程很不直观,很多时候都是碰运气.为此,卷积网发明者Yann LeCun的得意门生Matt ...
- R-CNN论文翻译
R-CNN论文翻译 Rich feature hierarchies for accurate object detection and semantic segmentation 用于精确物体定位和 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- DeconvNet 论文阅读理解
学习语义分割反卷积网络DeconvNet 一点想法:反卷积网络就是基于FCN改进了上采样层,用到了反池化和反卷积操作,参数量2亿多,非常大,segnet把两个全连接层去掉,效果也能很好,显著减少了参数 ...
随机推荐
- Docker+Nginx配置SSL
参考阿里云文档教程 前提条件 购买服务器的服务商开启443端口和服务器已开启443端口(https的默认端口) nginx容器已经安装http_ssl_module模块(启用SSL功能) 下面的教程基 ...
- linux中定时运行php(每分钟执行一次为例)
注:使用Crontab定时执行php脚本文件 1. 安装crontab yum install crontabs 说明:/sbin/service crond start //启动服务/sbin/se ...
- liunx服务器安装jdk
1.官网下载需要版本的jdk,官网地址 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.h ...
- 初探MFC
MFC MFC(Microsoft Foundation Classes) 是微软基础类库,也就是用c++类将win32API封装起来. 应用程序对象 MFC程序都是以应用程序对象为核心,且程序中只有 ...
- 逆向工程初步160个crackme-------3
这个Crackme3 涉及到浮点指令以及浮点数的存储与运算,我没学习过浮点指令,不得不从网上恶补了1个小时,一边看汇编指令一边百度其指令含义. 回头得好好补补这方面的知识了,太菜了! 我大致了解了一下 ...
- Codeforces Beta Round #73(Div2)
A - Chord 题意:就是环中有12个字符,给你三个字符,判断他们之间的间隔,如果第一个和第二个间隔是3并且第二个和第三个间隔是4,那么就输出minor,如果第一个和第二个间隔是4并且第二个和第三 ...
- 在Visual Studio 中使用git——文件管理-下(六)
在Visual Studio 中使用git--什么是Git(一) 在Visual Studio 中使用git--给Visual Studio安装 git插件(二) 在Visual Studio 中使用 ...
- CRM是什么意思,有哪些作用?
我们总会听到一些人提到CRM或CRM系统,但是通常不知道它的含义,所以今天小Z就来详细介绍一下CRM. GartnerGroup1993年首次提出了这一概念:所谓的客户关系管理就是为企业提供一个全面的 ...
- 『动善时』JMeter基础 — 21、HTTP Cookie管理器的使用
目录 1.在HTTP信息头管理器组件中添加Cookie信息 (1)测试计划内包含的元件 (2)请求取样器内容 (3)HTTP信息头管理器内容 (4)查看结果 2.使用HTTP Cookie管理器组件来 ...
- Linux下script命令录制、回放和共享终端操作script -t 2> timing.log -a output.session # 开始录制
Linux下script命令录制.回放和共享终端操作 [日期:2018-09-04] 来源:cnblogs.com/f-ck-need-u 作者:骏马金龙 [字体:大 中 小] 另一篇终端会话共 ...