大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念
一、Hadoop出现的前提环境
随着数据量的增大带来了以下的问题
(1)如何存储大量的数据?
(2)怎么处理这些数据?
(3)怎样的高效的分析这些数据?
(4)在数据增长的情况下如何构建一个解决方案?
在大数据领域提出了两个概念
(1)分布式文件系统 用于存储大量的数据
(2)分布式计算框架MapReduce高效的分析数据
以上的两个概念组成一个名词 Hadoop
二、Hadoop的起源
谷歌发布了三篇论文 : GFS 分布式存储系统 , MapReduce 分布式计算框架 , BigTable
Hadoop Google
HDFS GFS
MapReduce MapReduce
Hbase BigTable
三、Hadoop与其他的分布式系统比较
(1)Hadoop集群的数据首先先进行分布式的存储
(2)Hadoop集群上通过HDFS分布式文件系统,会把存储的数据复制多份,保证了数据的安全性
(3)提供了一个简单的易用的分布式计算框架
(4)Hadoop扩展容易
四、Hadoop中的版本
Hadoop存在版本的区别:
Hadoop1x版本中核心组件就是为 HDFS ,MapReduce
Hadop2x 版本依然存在HDFS,MapReduce,新增加了一个YARN
五、YARN介绍
(1)云操作系统,理解为资源管理器,管理集群中的资源在增加了YARN操作系统之后,MapReduce任务就可以跑在YARN平台上,通过YARN平台进行MapReduce任务的管理,资源的分配
(2)例如 也可以通过YARN平台运行Spark任务,包括可以读取HDFS上的数据文件
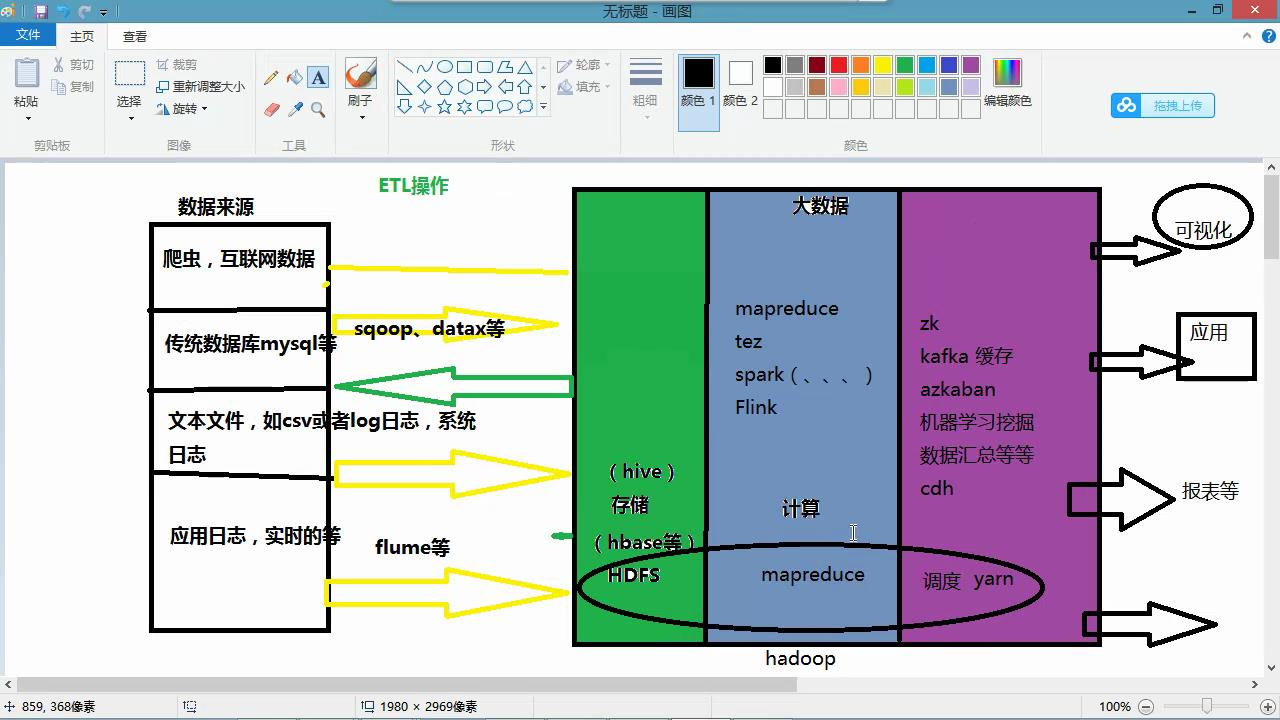
六、Hadoop生态圈的介绍
数据的来源,在企业中一般数据来源分为两种,第一种是企业内部的数据
例如:业务数据(保存在关系型数据库中),应用的服务器日志(日志文件),结构化数据
第二种是外部渠道获得:用户的行为记录(可以作为推荐系统的实现),通过搜索关键字,消费记录,爬虫技术,非结构化数据
数据要进行清洗 hive sqoop flume hbase hdfs mapreduce zookeeper
七、Hadoop的使用案例
现在使用Hadoop进行数据分析的公司越来越多,主要包括以下几种:
(1)为银行和信用卡公司进行欺诈性的检测
(2)社交媒体市场的分析
(3)电商网站的购物模式分析,用户行为分析
(4)城市的发展交通的模式识别
八、Hadoop的企业级应用主要包括四个层次
(1)存储层(HDFS Hbase)
(2)数据处理层 (Hive MapReduce)
(3)实时访问层(Spark Flink)
九、Hadoop中的组件信息
Hadoop中核心组件HDFS,YARN ,MapReduce
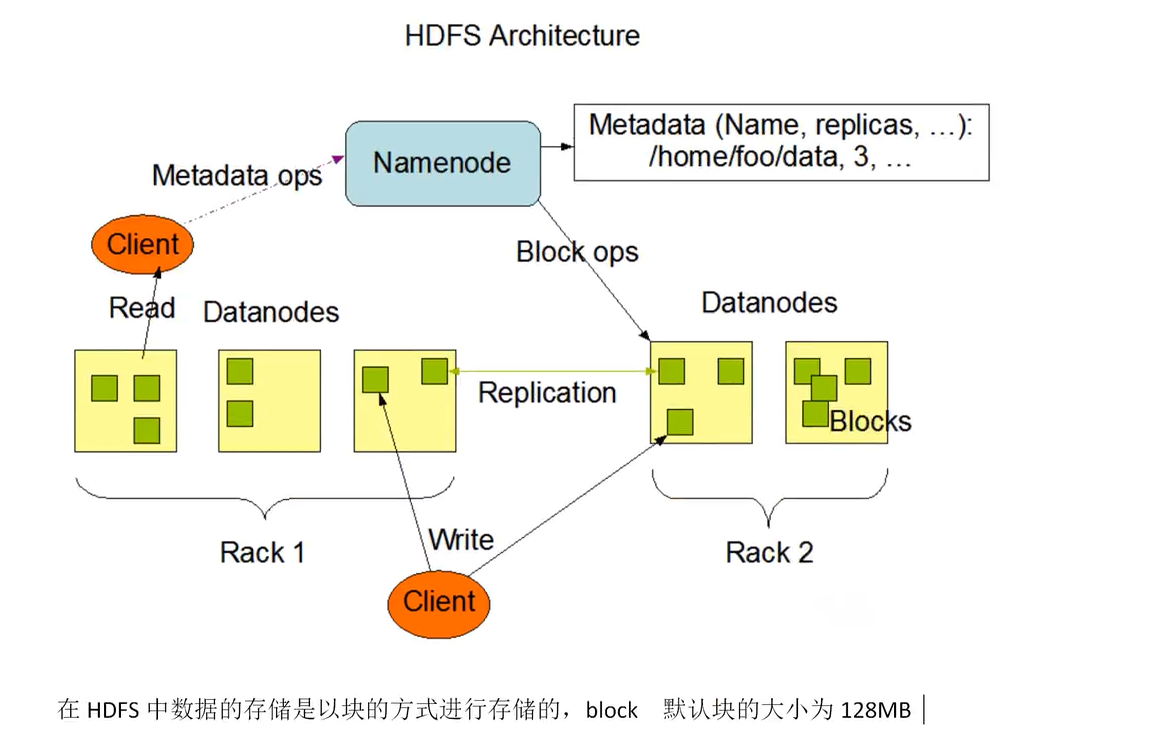
(1)HDFS架构
分布式存储系统,分布式的架构上存在 主/从 的架构关系在HDFS文件系统上存在主节点,以及从节点
主节点:namenode 负责管理HDFS集群文件中的元数据(文件的名称,文件的位置,文件的副本)
从节点:datanode负责存储真正的数据
(2)YARN架构
分布式的架构,分为主从架构
主节点 resourceManager负责管理集群中的所有资源(cpu,内存,磁盘,网络I/O)
从节点 nodeManager负责管理集群中每一台服务器的资源

(3)MapReduce 架构 核心思想 分而治之
Map端和Reduce端进行数据分析
数据在Map阶段进行分开处理,处理完成之后,再交给reduce进行统计,在Map和Reduce中间的阶段通过shuffle来进行连接。
大数据之路week06--day07(Hadoop生态圈的介绍)的更多相关文章
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- 大数据之路week06--day07(Hadoop常用命令)
一.前述 分享一篇hadoop的常用命令的总结,将常用的Hadoop命令总结如下. 二.具体 1.启动hadoop所有进程start-all.sh等价于start-dfs.sh + start-yar ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- CentOS6安装各种大数据软件 第一章:各个软件版本介绍
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- 高级UI-事件传递
事件传递在Android中有着举足轻重的作用,那么事件的传递在Android中又是怎么样实现的呢,在这里我们将进一步探讨Android的事件传递机制 从一个例子入手 首先是一个简单的onTouch和o ...
- linux本地内核提权之CVE-2019-13272(鸡肋)
CVE-2019-13272 发布时间: 2019月7月17日 影响内核版本: Linux Kernel < 5.1.17 漏洞描述: 译文 kernel 5.1.17之前版本中存在安全漏洞,该 ...
- 如何理解MVC
在面试的时候,MVC这个概念考的次数很多,有许多人只能把三个字母解释成三个单词:model,view,controller,但是如果往深处说就说不出来什么东西了,对这个概念模糊不清,今天闲来无事看了一 ...
- Python进阶:metaclass谈
metaclass 的超越变形特性有什么用? 来看yaml的实例: import yaml class Monster(yaml.YAMLObject): yaml_tag = u'!Monster' ...
- WUSTOJ 1323: Repeat Number(Java)规律统计
题目链接:1323: Repeat Number Description Definition: a+b = c, if all the digits of c are same ( c is mor ...
- binlogserver搭建
在MySQL 5.7.x版本中,mysqlbinlog工具解析任何一个本地的binlog或relay log时,都不会在mysqlbinlog命令执行结束时追加rollback语句, 但在MySQL ...
- SQLSERVER远程链接Oracle数据库
原文地址: http://blog.sina.com.cn/s/blog_45eaa01a0102ywuk.html 使用SQL链接服务器远程访问Oracle数据库 在本机上通过SQL数据库的链接 ...
- xml文件中引用网址报红色如何解决
用了ideal的宝宝们一定遇到过配置文件网址报红的错误吧 其实解决很简单,就是网不好导致它没法补全,我们手动给他补全就好啦 复制报红的网址 点击File==>settings==>lang ...
- 多线程面试题之【三线程按顺序交替打印ABC的方法】
建立三个线程,线程名字分别为:A.B.C,要求三个线程分别打印自己的线程名字,但是要求三个线程同时运行,并且实现交替打印,即按照ABCABCABC的顺序打印.打印10轮,打印完毕控制台输出字符串:&q ...
- vue 写一个瀑布流插件
效果如图所示: 采用了预先加载图片,再计算高度的办法..网络差的情况下,可能有点卡 新建 vue-water-easy.vue 组件文件 <template> <div class ...