大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念
一、Hadoop出现的前提环境
随着数据量的增大带来了以下的问题
(1)如何存储大量的数据?
(2)怎么处理这些数据?
(3)怎样的高效的分析这些数据?
(4)在数据增长的情况下如何构建一个解决方案?
在大数据领域提出了两个概念
(1)分布式文件系统 用于存储大量的数据
(2)分布式计算框架MapReduce高效的分析数据
以上的两个概念组成一个名词 Hadoop
二、Hadoop的起源
谷歌发布了三篇论文 : GFS 分布式存储系统 , MapReduce 分布式计算框架 , BigTable
Hadoop Google
HDFS GFS
MapReduce MapReduce
Hbase BigTable
三、Hadoop与其他的分布式系统比较
(1)Hadoop集群的数据首先先进行分布式的存储
(2)Hadoop集群上通过HDFS分布式文件系统,会把存储的数据复制多份,保证了数据的安全性
(3)提供了一个简单的易用的分布式计算框架
(4)Hadoop扩展容易
四、Hadoop中的版本
Hadoop存在版本的区别:
Hadoop1x版本中核心组件就是为 HDFS ,MapReduce
Hadop2x 版本依然存在HDFS,MapReduce,新增加了一个YARN
五、YARN介绍
(1)云操作系统,理解为资源管理器,管理集群中的资源在增加了YARN操作系统之后,MapReduce任务就可以跑在YARN平台上,通过YARN平台进行MapReduce任务的管理,资源的分配
(2)例如 也可以通过YARN平台运行Spark任务,包括可以读取HDFS上的数据文件
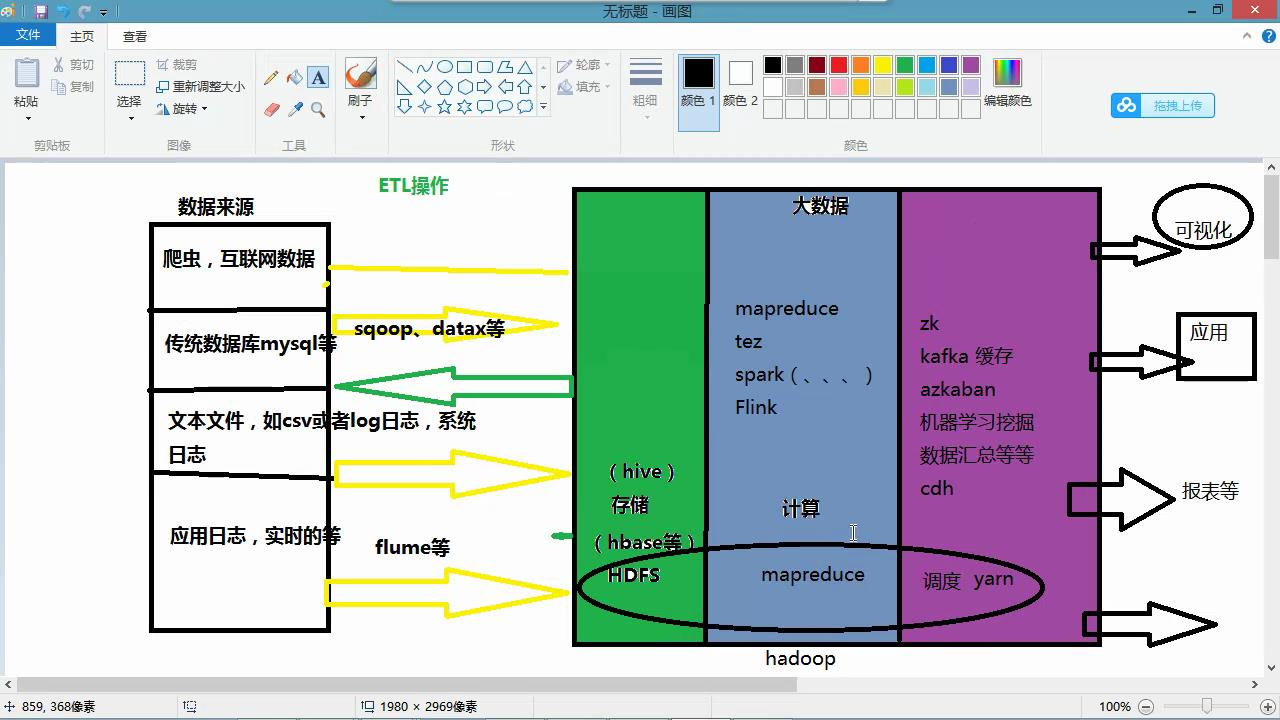
六、Hadoop生态圈的介绍
数据的来源,在企业中一般数据来源分为两种,第一种是企业内部的数据
例如:业务数据(保存在关系型数据库中),应用的服务器日志(日志文件),结构化数据
第二种是外部渠道获得:用户的行为记录(可以作为推荐系统的实现),通过搜索关键字,消费记录,爬虫技术,非结构化数据
数据要进行清洗 hive sqoop flume hbase hdfs mapreduce zookeeper
七、Hadoop的使用案例
现在使用Hadoop进行数据分析的公司越来越多,主要包括以下几种:
(1)为银行和信用卡公司进行欺诈性的检测
(2)社交媒体市场的分析
(3)电商网站的购物模式分析,用户行为分析
(4)城市的发展交通的模式识别
八、Hadoop的企业级应用主要包括四个层次
(1)存储层(HDFS Hbase)
(2)数据处理层 (Hive MapReduce)
(3)实时访问层(Spark Flink)
九、Hadoop中的组件信息
Hadoop中核心组件HDFS,YARN ,MapReduce
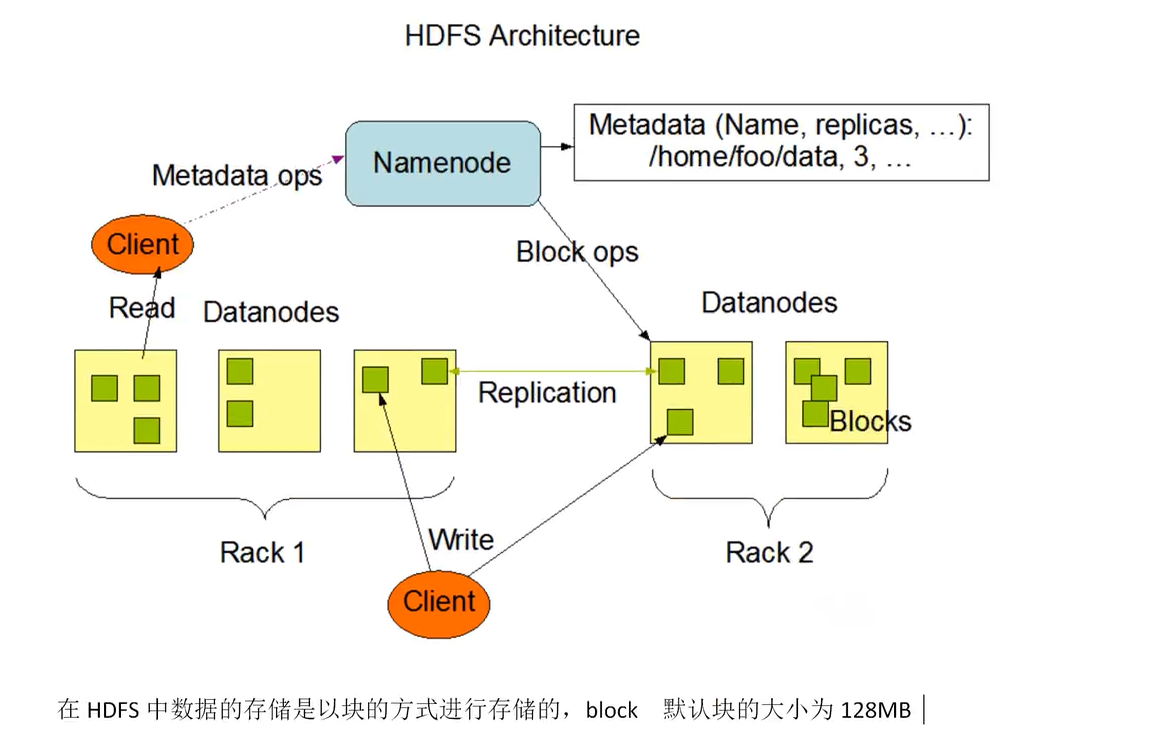
(1)HDFS架构
分布式存储系统,分布式的架构上存在 主/从 的架构关系在HDFS文件系统上存在主节点,以及从节点
主节点:namenode 负责管理HDFS集群文件中的元数据(文件的名称,文件的位置,文件的副本)
从节点:datanode负责存储真正的数据
(2)YARN架构
分布式的架构,分为主从架构
主节点 resourceManager负责管理集群中的所有资源(cpu,内存,磁盘,网络I/O)
从节点 nodeManager负责管理集群中每一台服务器的资源

(3)MapReduce 架构 核心思想 分而治之
Map端和Reduce端进行数据分析
数据在Map阶段进行分开处理,处理完成之后,再交给reduce进行统计,在Map和Reduce中间的阶段通过shuffle来进行连接。
大数据之路week06--day07(Hadoop生态圈的介绍)的更多相关文章
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- 大数据之路week06--day07(Hadoop常用命令)
一.前述 分享一篇hadoop的常用命令的总结,将常用的Hadoop命令总结如下. 二.具体 1.启动hadoop所有进程start-all.sh等价于start-dfs.sh + start-yar ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- CentOS6安装各种大数据软件 第一章:各个软件版本介绍
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- 关于tornado的raise gen.Retuen()
raise gen.Return(response.body)在python3.3以后作用相当于return, 在python3.3之前作用是返回一个异常值, 和返回一个value python 3. ...
- shell学习及脚步编写
目录: shell基础变量逻辑运算符 scp基础用法脚本 while+for+case基础用法脚本 内核优化脚本 自动修改本机ip脚本 for+case 查询日志脚本 一键yum安装lamp脚本 源码 ...
- 用pytorch1.0搭建简单的神经网络:进行多分类分析
用pytorch1.0搭建简单的神经网络:进行多分类分析 import torch import torch.nn.functional as F # 包含激励函数 import matplotlib ...
- nlp算法
人工智能算法大体上来说可以分类两类:基于统计的机器学习算法(Machine Learning)和深度学习算法(Deep Learning) 总的来说,在sklearn中机器学习算法大概的分类如下: 1 ...
- netty-websocket简单的使用方法
最便捷使用netty-websocket方法 1.pom添加依赖 <dependency> <groupId>org.yeauty</groupId> <ar ...
- Linux shell 中 & && [] [[]] () [] 含义
| 语法:command 1 | command 2 功能:把第一个命令 command 1 执行的结果作为 command 2 的输入传给 command 2 & & 放在启动参数后 ...
- Matlab R2017b 打开后一直显示“正在初始化”,导致无法运行命令
1. 前言 Matlab R2017b打开后一直显示"正在初始化",导致无法运行命令. 2. 解决方案 1. 找到并记录授权文件license_standalone.lic的路径. ...
- visio 绘图素材
1. 前言 visio是个绘图的好工具,可是自带图形元素有限,没有还要自己画. 推荐几个矢量图形素材库,里边有很多图形,很方便的导入到visio中,放大也不失真. 阿里巴巴矢量图库网 stockio ...
- dedecms5.7怎么安装百度编辑器
用过dedecms的朋友都知道dede自带的文本编辑器很不好用,且有些功能还需要我们自己手动去修改源码,才能完成我们想要的效果.现在广大用dedecms的朋友们,你们有福啦!我们可以利用百度的Uedi ...
- Django框架1——视图和URL配置
三个命令 1.创建一个django项目 在cmd中:django-admin.py startproject project_name D:\python\django_site>django- ...