#LOF算法
a.每个数据点,计算它与其他点的距离
b.找到它的K近邻,计算LOF得分
clf=LocalOutlierFactor(n_neighbors=20,algorithm='auto',contamination=0.1,n_jobs=-1,p=2)
参数含义
●n_neighbors=20:即LOF算法中的k的值,检测的邻域点个数超过样本数则使用所有的样本进行检测
●algorithm = 'auto':使用的求解算法,使用默认值即可
●contamination = 0.1:范围为 (0, 0.5),表示样本中的异常点比例,默认为 0.1
● n_jobs = -1:并行任务数,设置为-1表示使用所有CPU进行工作
● p = 2:距离度量函数,默认使用欧式距离。
def localoutlierfactor(data, predict, k):
from sklearn.neighbors import LocalOutlierFactor
clf = LocalOutlierFactor(n_neighbors=k + 1, algorithm='auto', contamination=0.1, n_jobs=-1)
clf.fit(data)
# 记录 k 邻域距离
predict['k distances'] = clf.kneighbors(predict)[0].max(axis=1)
# 记录 LOF 离群因子,做相反数处理
predict['local outlier factor'] = -clf._decision_function(predict.iloc[:, :-1])
return predict
def plot_lof(result, method):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(8, 4)).add_subplot(111)
plt.scatter(result[result['local outlier factor'] > method].index,
result[result['local outlier factor'] > method]['local outlier factor'], c='red', s=50,
marker='.', alpha=None,
label='离群点')
plt.scatter(result[result['local outlier factor'] <= method].index,
result[result['local outlier factor'] <= method]['local outlier factor'], c='black', s=50,
marker='.', alpha=None, label='正常点')
plt.hlines(method, -2, 2 + max(result.index), linestyles='--')
plt.xlim(-2, 2 + max(result.index))
plt.title('LOF局部离群点检测', fontsize=13)
plt.ylabel('局部离群因子', fontsize=15)
plt.legend()
plt.show()
def lof(data, predict=None, k=5, method=1, plot=True):
import pandas as pd
# 判断是否传入测试数据,若没有传入则测试数据赋值为训练数据
try:
if predict == None:
predict = data.copy()
except Exception:
pass
predict = pd.DataFrame(predict)
# 计算 LOF 离群因子
predict = localoutlierfactor(data, predict, k)
if plot == True:
plot_lof(predict, method)
# 根据阈值划分离群点与正常点
outliers = predict[predict['local outlier factor'] > method].sort_values(by='local outlier factor')
inliers = predict[predict['local outlier factor'] <= method].sort_values(by='local outlier factor')
return outliers, inliers
import numpy as np
import pandas as pd
import xlrd
# 根据文件位置自行修改
posi = pd.read_excel(r'./已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
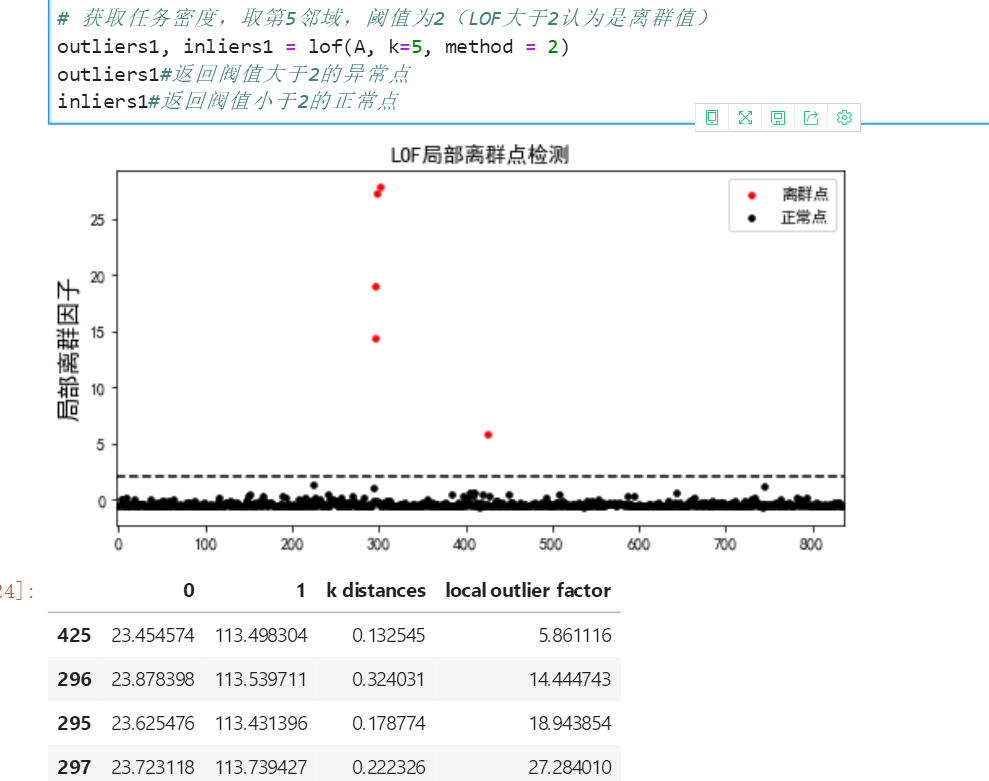
# 获取任务密度,取第5邻域,阈值为2(LOF大于2认为是离群值)
outliers1, inliers1 = lof(A, k=5, method = 2)
参考链接:
https://www.jianshu.com/p/8c5c0c903f27
https://zhuanlan.zhihu.com/p/28178476
异常检测的几种方法
https://xz.aliyun.com/t/5378
#LOF算法的更多相关文章
- 异常点/离群点检测算法——LOF
http://blog.csdn.net/wangyibo0201/article/details/51705966 在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异 ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 异常检测LOF
局部异常因子算法-Local Outlier Factor(LOF)在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据.异常检测也是数据挖掘的一个方向,用于反作弊 ...
- k-means算法的优缺点以及改进
大家接触的第一个聚类方法,十有八九都是K-means聚类啦.该算法十分容易理解,也很容易实现.其实几乎所有的机器学习和数据挖掘算法都有其优点和缺点.那么K-means的缺点是什么呢? 总结为下: (1 ...
- C#下实现的K-Means优化[1]-「离群点检测」
资源下载 #本文PDF版下载 C#下实现的K-Means优化[1]-「离群点检测」 前言 在上一篇博文中,我和大家分享了「C # 下实现的多维基础K-MEANS聚类」的[C#下实现的基础K-MEANS ...
- C#下实现的基础K-MEANS多维聚类
资源下载 #本文PDF版下载 C#下实现的基础K-MEANS多维聚类PDF #本文代码下载 基于K-Means的成绩聚类程序 前言 最近由于上C # 课的时候,老师提到了-我们的课程成绩由几个部分组成 ...
- [译]用R语言做挖掘数据《六》
异常值检测 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: ...
- 【R笔记】使用R语言进行异常检测
本文转载自cador<使用R语言进行异常检测> 本文结合R语言,展示了异常检测的案例,主要内容如下: (1)单变量的异常检测 (2)使用LOF(local outlier factor,局 ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
随机推荐
- 【AI教育】可以看看行业痛点分析
http://www.woshipm.com/it/2801582.html 至于解决方案嘛,还在堆砌技术的阶段.
- linux 安装网易云音乐
1.首先去官网下载最新的网易云 网易云音乐曾经推出官方Linux版本,提供的下载安装包有:deepin15(32位):http://s1.music.126.net/download/pc/net . ...
- JBPM使用
jbpm+mysql5.7 https://blog.csdn.net/tyn243222791/article/details/79033555
- Eclipse Mars配置tomcat 7
进入Eclipse,点击"Window"-->"Preferences". 在出现的弹窗的左侧面板选择"Server"-->&q ...
- Python3之类和实例访问限制
在Class内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑. 但是,从前面的Student类定义来看,外部代码还是可以自由地修改一个实例的na ...
- .git泄露及利用php弱类型松散比较构造json的payload
一道ctf题,文章搬运到了自己的网站上: http://101.132.137.140:202/archives/2019-11-16
- 【miscellaneous】基于gstreamer的实时转码
目标是实现一个实时转码,可用于IPTV提供节目源.相关工作在ubuntu操作系统下进行.需要对源代码进行修改的时候,直接采用apt-get source命令获取源代码,根据需要进行修改,然后安装,这样 ...
- javascript DOM和DOM操作的四种基本方法
在了解了javascript的语言特性后,javascript真正大放光彩的地方来了——这就是javascript DOM Javascript DOM DOM(Document Object Mod ...
- mysql 查询结果为null 或 空字符串时,返回指定字符串
直接上代码, 亲测可用: SELECT IF ( ifnull( 字段, '' ) = '', '返回的字符串', 字段) AS 别名(或者不要也可以) FROM table
- nginx 进程管理-信号
进程结构:一个master进程和多个子进程. 子进程分两类:一种是 Worker 进程,另一种是 Cache 相关的进程. master进程:管理 Worker 进程,发送信号. 接收信号: TERM ...