MySql数据库 优化
MySQL数据库优化方案
Mysql的优化,大体可以分为三部分:索引的优化,sql慢查询的优化,表的优化。
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
Sql 慢查询优化步骤
先捕获低效SQL→慢查询优化方案→慢查询优化原则
MySQL数据库配置慢查询
参数说明:
1.查询慢查询配置
show variables like 'slow_query%';
slow_query_log 对应 开启状态
slow_query_log_file 对应 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
2.查询慢查询限制时间,查询超过多少秒才记录,默认是10s。
show variables like 'long_query_time';
3.将 slow_query_log 全局变量设置为“ON”状态
set global slow_query_log='ON';
4.查询超过1秒就记录
set global long_query_time=1;
5.查询日志,可根据自己查询出来的实际地址进行查看,该例子是以 linux 部署的 mysql 的日志存储位置。
cat /var/lib/mysql/localhost-slow.log
6. linux中 重启 mysql 命令
service mysqld restart
索引为什么会失效?注意那些事项?
1.索引无法存储null值
2.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因) 要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
3.对于多列索引,不是使用的第一部分,则不会使用索引
4.like查询以%开头 5.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
举栗子说明:
#### 创建表
CREATE TABLE `user_details` (
`id` int(11) not NULL,
`user_name` varchar(50) DEFAULT NULL,
`user_phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
select * from user_details;
#### 新建索引
ALTER TABLE `user_details` ADD INDEX user_name_index ( `user_name` );
### 查询索引
desc user_details;
insert into user_details values(1,'ming1','123456789');
insert into user_details values(2,'ming2','123456789');
insert into user_details values(3,'ming3','123456789');
insert into user_details values(4,'ming4','123456789');
insert into user_details values(5,'ming5','123456789');
insert into user_details values(6,'ming6','123456789');
### 全表扫描
explain select * from user_details where user_phone='123456789';
### 主键索引 type=const
EXPLAIN select * from user_details WHERE id=1
#### 普通索引 type=const
EXPLAIN select * from user_details WHERE id=1 and user_name='ming1';
#### 主键索引 不能使用 % 开头,全表扫描 type=all
EXPLAIN select * from user_details WHERE id like '%sss'
#### 主键索引 % 结尾 全表扫描 type=all
EXPLAIN select * from user_details WHERE id like '1%'
#### 普通索引 %开头 会导致 索引失效 type=all
EXPLAIN select * from user_details WHERE user_name like '%1'
#### 普通索引 %结果 会导致 索引不会失效 type=range
EXPLAIN select * from user_details WHERE user_name like '1%'
##### 条件字符串不加 '' 会导致索引失效 type=all
EXPLAIN select * from user_details WHERE user_name =1;
##### 索引不会失效 type=ref
EXPLAIN select * from user_details WHERE user_name ='1';
### 全表扫描 type=all
EXPLAIN select * from user_details WHERE id='1' or user_name='ming1';
联合索引为什么需要遵循左前缀原则?
如果在一张表中,存在联合索引的话,在根据条件查询的时候必须要加上第一个索引条件。
---索引生效
EXPLAIN select * from user_details WHERE id=1 and user_name=‘yushengjun1’;
索引是不生效的
EXPLAIN select * from user_details WHERE user_name=‘yushengjun1’;
举栗子说明:
###### 联合主键索引 id + user_name 组合索引 #########
#### 联合主键索引 只要 id + user_name 保证唯一即可
CREATE TABLE `userInfo` (
`id` int(11) not NULL,
`user_name` varchar(50) not NULL,
`user_phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (id,user_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SELECT * from userInfo;
insert into userInfo values(1,'明天','123456789');
insert into userInfo values(1,'小明','123456789');
insert into userInfo values(2,'小红','123456789');
insert into userInfo values(2,'大白','123456789');
insert into userInfo values(3,'小龙','123456789');
insert into userInfo values(3,'小菲','123456789');
#### 只能插入成功一条数据 ,因为 id + user_name 需要保证唯一性
insert into userInfo values(4,'小放','123456789');
insert into userInfo values(4,'小放','123456789');
####索引 有效 type=ref
EXPLAIN select * from userInfo WHERE id=1
####索引 有效 type=const
EXPLAIN select * from userInfo WHERE id=1 and user_name='明天';
#### 索引 无效 type=all
EXPLAIN select * from userInfo WHERE user_name='小明';
#### 索引有效 type=const
EXPLAIN select * from userInfo WHERE user_name='小明' and id=1
因为索引底层采用B+树叶子节点顺序排列,必须通过左前缀索引才能定位到具体的节点范围。
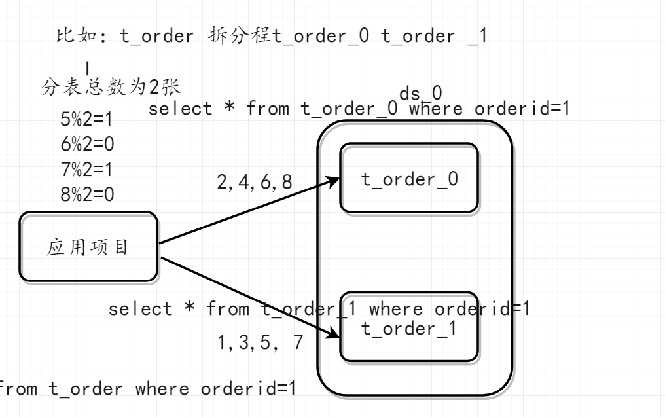
分表分库为什么能够提高数据库查询效率?
因为会将一张表的数据拆分成多个n张表进行存放,让后在使用第三方中间件(MyCat或者Sharding-JDBC)并行同时查询,让后在交给第三方中间进行组合返回给客户端。
MySql数据库 优化的更多相关文章
- 关于MySQL数据库优化的部分整理
在之前我写过一篇关于这个方面的文章 <[原创]为什么使用数据索引能提高效率?(本文针对mysql进行概述)(更新)> 这次,主要侧重点讲下两种常用存储引擎. 我们一般从两个方面进行MySQ ...
- 【MySQL】花10分钟阅读下MySQL数据库优化总结
1.花10分钟阅读下MySQL数据库优化总结http://www.kuqin.com2.扩展阅读:数据库三范式http://www.cnblogs.com3.my.ini--->C:\Progr ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 50多条mysql数据库优化建议
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存 ...
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- 30多条mysql数据库优化方法【转】
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 百万行mysql数据库优化和10G大文件上传方案
百万行mysql数据库优化和10G大文件上传方案 最近这几天正在忙这个优化的方案,一直没时间耍,忙碌了一段时间终于还是拿下了这个项目?项目中不要每次都把程序上的问题,让mysql数据库来承担,它只是个 ...
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- 关于mysql数据库优化
关于mysql数据库优化 以我之愚见,数据库的优化在于优化存储和查询速度 目前主要的优化我认为是优化查询速度,查询速度快了,提高了用户的体验 我认为优化主要从两方面进行考虑, 优化数据库对象, 优化s ...
- mysql数据库优化 pt-query-digest使用
mysql数据库优化 pt-query-digest使用 一.pt-query-digest工具简介 pt-query-digest是用于分析 mysql慢查询的一个工具,它可以分析binlog.Ge ...
随机推荐
- OpenTK学习笔记(2)-工作窗口的三种方法创建方法(winfrom窗体控件形式创建)
参考资料: https://social.msdn.microsoft.com/Forums/zh-TW/1b781685-c670-4338-953d-1957a8f24a66/opentkglco ...
- Django 测试开发1
笔者用的版本的是django==1.8.2,这个版本的学习资料最多,文档最完整.首先创建项目:django-admin startproject 项目名. guest/__init__.py 一个空的 ...
- 数据库Sequence创建与使用
最近几天使用Oracle的sequence序列号,发现对如何创建.修改.使用存在很多迷茫点,在上网寻找答案后,根据各路大神的总结,汇总下对自己的学习成果: 在Oracle中sequence就是序号,每 ...
- 移动端安卓和 IOS 开发框架 Framework7 布局
对应的各种效果,Framework7 里面实现的方式比较多,这里我就只写我用的一种,样式有的自己修改了的,想看官方详细的参见 http://framework7.cn 一.手风琴布局Accordion ...
- vue-cli的eslint不加空格报错问题
//方法一.直接不启用eslint(不推荐) //找到build/webpack.base.conf.js把以下代码取消注释 { test: /\.(js|vue)$/, loader: 'eslin ...
- Docs-.NET-C#-指南-语言参考-预处理器指令:C# 预处理器指令
ylbtech-Docs-.NET-C#-指南-语言参考-预处理器指令:C# 预处理器指令 1.返回顶部 1. C# 预处理器指令 2015/07/20 本节介绍了以下 C# 预处理器指令: #if ...
- int 和String之间的相互转换
int ---> String 1. 和 "" 进行拼接 2. 使用String类中的静态方法valueOf: public static String valueOf(in ...
- YApi内部部署文档
旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建.发布.维护 API 1.安装Node.js环境(7.6+) 1.官网下载适合的nodejs版本放置在/usr/package ...
- Expression: __acrt_first_block == header
File: minkernel\crts\ucrt\src\appcrt\heap\debug_heap.cpp Line: 996 Expression: __acrt_first_block == ...
- LVS搭建负载均衡集群(一)——NAT模式
(1).集群技术的分类 集群技术主要分为三大类:负载均衡(Load Balance)集群,简称LB集群:高可用(High Availability)集群,简称 HA 集群:高性能计算(High Per ...