HDFS NFS Gateway
NFS网关支持NFSv3,并允许将HDFS作为客户端本地文件系统进行挂载。目前,NFS Gateway支持并启用以下使用模式:
- 用户可以通过NFSv3客户端兼容操作系统上的本地文件系统浏览HDFS文件系统。
- 用户可以将文件从HDFS文件系统下载到其本地文件系统。
- 用户可以将文件从本地文件系统直接上传到HDFS文件系统。
- 用户可以通过挂载点将数据直接传输到HDFS。支持文件追加,但不支持随机写入。
CDH部署NFS Gateway
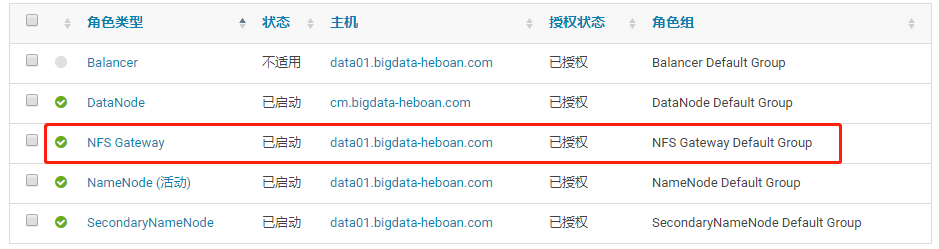
可以在data01.bigdata-heboan.com(192.168.48.129)上验证服务是否启动
rpcinfo -p $nfs_server_ip
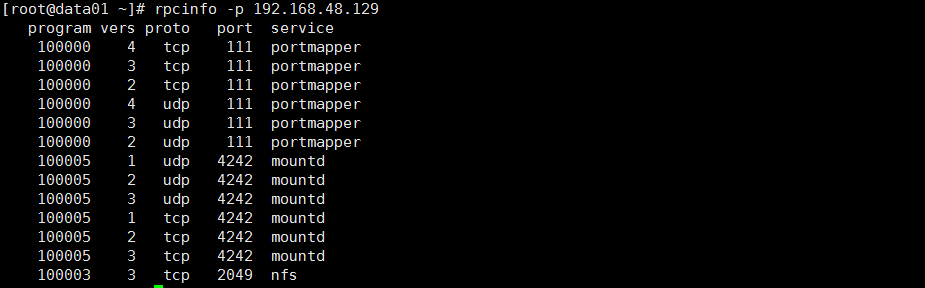
现在找一台客户端机器(192.168.48.130)
安装nfs
yum install rpcbind nfs-utils -y
验证 HDFS命名空间是否已导入并可以挂载
showmount -e $ nfs_server_ip

挂载导出"/"
目前NFS v3仅使用TCP作为传输协议。不支持NLM,因此需要mount选项“nolock”。强烈建议使用挂载选项“sync”,因为它可以最小化或避免重新排序的写入,从而产生更可预测的吞吐量。
上载大文件时,不指定sync选项可能会导致不可靠的行为。建议使用硬装。这是因为,即使在客户端将所有数据发送到NFS网关之后,当NFS客户端内核重新排序写入时,可能需要额外的时间将NFS网关传输到HDFS。
如果必须使用软安装,用户应该给它一个相对较长的超时(至少不低于主机上的默认超时)。
用户可以挂载HDFS命名空间,如下所示
mount -t nfs -o vers=,proto=tcp,nolock,noacl,sync $server:/ $mount_point
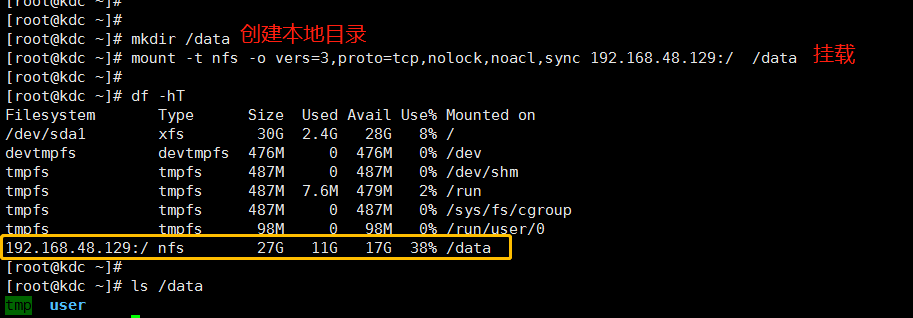
经过测试使用, 挂载到本地读写不受kerberos认证影响, 但是需注意用户权限。
比如使用heboan用户对挂载的目录进行上传文件, 操作步骤如下:
- 在hdfs 集群主机,ndfs客户端创建用户heboan(最好使用ldap,如 freeipa管理,这样可以确保uid一致,否则手动创建可能uid不一样,这个要注意)
- 然后使用hdfs 创建/user/heboan (hdfs dfs -mkdir /user/heboan hdfs dfs -chown heboan:heboan /user/heboan)
- 最后使用用户heboan登录nfs客户端,就可以对/data/user/heboan目录进行读写了
HDFS NFS Gateway的更多相关文章
- Hadoop HDFS NFS GateWay部署深入具体解释
目的:通过挂载的方式,能够相似訪问本地磁盘的方式一样的訪问Hadoop文件.简单.方便.快捷. 0.系统版本号&hadoop版本号 1)系统版本号 [root@WEB-W031 sbin]# ...
- [测试] 试用Hadoop 2.2中的HDFS NFS
Hadoop 2.2中正式启用了hdfs nfs功能,使得hdfs的通用性迈进了一大步.在公司让小朋友搭建了一下,然后我自己进行了一点简单的试验,有一点收获,记录在此. 理论 使用hdfs nfs功能 ...
- hadoop最新稳定版本使用建议
Apache Hadoop Apache版本衍化比较快,我给大家介绍一下过程 ApacheHadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- 【转载】Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- 使用nfs3将hdfs挂载到本地或远程目录(非kerberos适用)
最基本的配置方法,aix.kerberos等的操作详见http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Hdf ...
- windows本地挂载HDFS
1.修改配置文件 进入配置文件目录: cd ${HADOOP_HOME}/etc/hadoop 修改core-site.xml: vim core-site.xml 在文件中增加以下内容: <p ...
- 离线安装 Cloudera ( CDH 5.x )
要配置生产环境前,最好严格按照官方文档/说明配置环境.比如,官方说这个安装包用于RETHAT6, CENTOS6,那就要装到6的版本下,不然很容易出现各种各样的错. 配置这个CDH5我入了很多坑,最重 ...
随机推荐
- 转:VMware 15 安装 MAC OS 10.13 原版(详细图文教程)
-----------------转载------------------------ 原文:https://blog.csdn.net/qq_40147863/article/details/847 ...
- GitHub 访问慢
绕过 DNS 解析,配置 hosts 文件直连. 速度取决与服务器和你所在的网络环境,不一定换了就速度快. DNS 查询网址 https://www.ipaddress.com/ https://to ...
- 代码实现:当我们下载一个试用版软件,没有购买正版的时候,每执行一次就会提醒我们还有多少次使用机会用学过的IO流知识,模拟试用版软件,试用10次机会,执行一次就提示一次您还有几次机会,如果次数到了提示请购买正版
package com.loaderman.test; import java.io.BufferedReader; import java.io.FileReader; import java.io ...
- [Err] ORA-00942: table or view does not exist
[Err] ORA-00942: table or view does not exist 当前用户加表明 例如:SCOTT."replyInfo"
- nodejs 中间件理解
中间件概念 在NodeJS中,中间件主要是指封装所有Http请求细节处理的方法.一次Http请求通常包含很多工作,如记录日志.ip过滤.查询字符串.请求体解析.Cookie处理.权限验证.参数验证.异 ...
- 联想 ThinkPad 笔记本 Fn 键 关闭与启用方法
联想 ThinkPad 笔记本 Fn 键 关闭与启用方法 [最快捷的方式] 按 Fn + Esc 键,进行切换启用或者关闭 Fn 功能键 So easy!!! ^_^
- gcc posix sjij for MSYS 9.2.1+
mingw gcc 32位 版本 9.2.1 以上的 以后都在 github 上发布 https://github.com/qq2225936589/gcc-i686-posix-sjlj-for-M ...
- 让mysql返回的结果按照传入的id的顺序排序
比如id为 1,3,5,44,66,32,21,6 那么返回的结果顺序也是这个顺序 $sql = "select * from ".$this->tableName(). ...
- [转] An In-Depth Look at the HBase Architecture - HBase架构深度剖析
[From] https://mapr.com/blog/in-depth-look-hbase-architecture/ In this blog post, I’ll give you an i ...
- DES加密解密工具
using System; using System.Text; using System.Security.Cryptography; using System.IO; namespace DESP ...