python爬虫(1)——urllib包
人生苦短,我用python!
一、关于爬虫
鉴于我的windos环境使用命令行感觉非常不便,也懒得折腾虚拟机,于是我选择了一个折中的办法——Cmder。它的下载地址是:cmder.net
Cmder是一个增强型命令行工具,不仅可以使用windows下的所有命令,更爽的是可以使用linux的命令,shell命令。下载下来后,解压即可使用。稍加设置(具体的设置可以百度),你就会发现它比windos的cmd要好用的多。
爬虫分为通用爬虫和聚焦爬虫,我们所研究的就是聚焦爬虫——抓取网页时筛选,尽量只抓与需求相关的网页信息。而网络爬虫的抓取过程我们可以理解为模拟浏览器操作的过程,这个过程基于Http(超文本传输协议)和Https(安全版的Http)的。当我们向浏览器中输入https://www.baidu.com/时,它就会根据这个地址来获取网页信息。我们所输入的网址就是URL——统一资源定位符,它是用于完整地描述Internet上网页和其它资源的地址的一种标识方式。
二、Python的urllib包
在Python3中,我们可以使用urlib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一些处理URL的模块。我们可以使用help命令查看一下。
import urllib help(urllib)
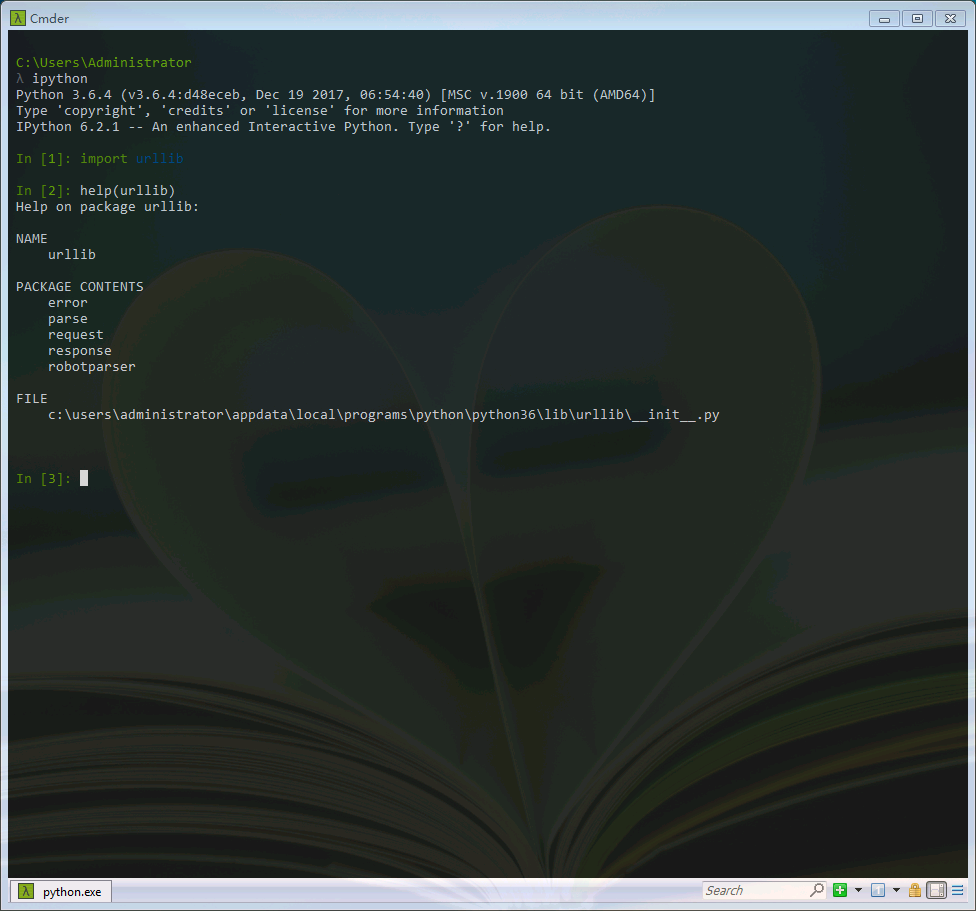
其中:
1.urllib.request模块是用来打开和读取URLs的;
2.urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理(可以学习一下python的异常处理机制);
3.urllib.parse模块包含了一些解析URLs的方法;
4.urllib.robotparser模块用来解析robots.txt(爬虫协议)文本文件,它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面。
三、下载一个页面
了解了以上这些,我们可以用request来尝试下载一个页面。在ipython中测试一下:
from urllib import request
response=request.urlopen('http://www.17jita.com/')
html=response.read()
print(html)
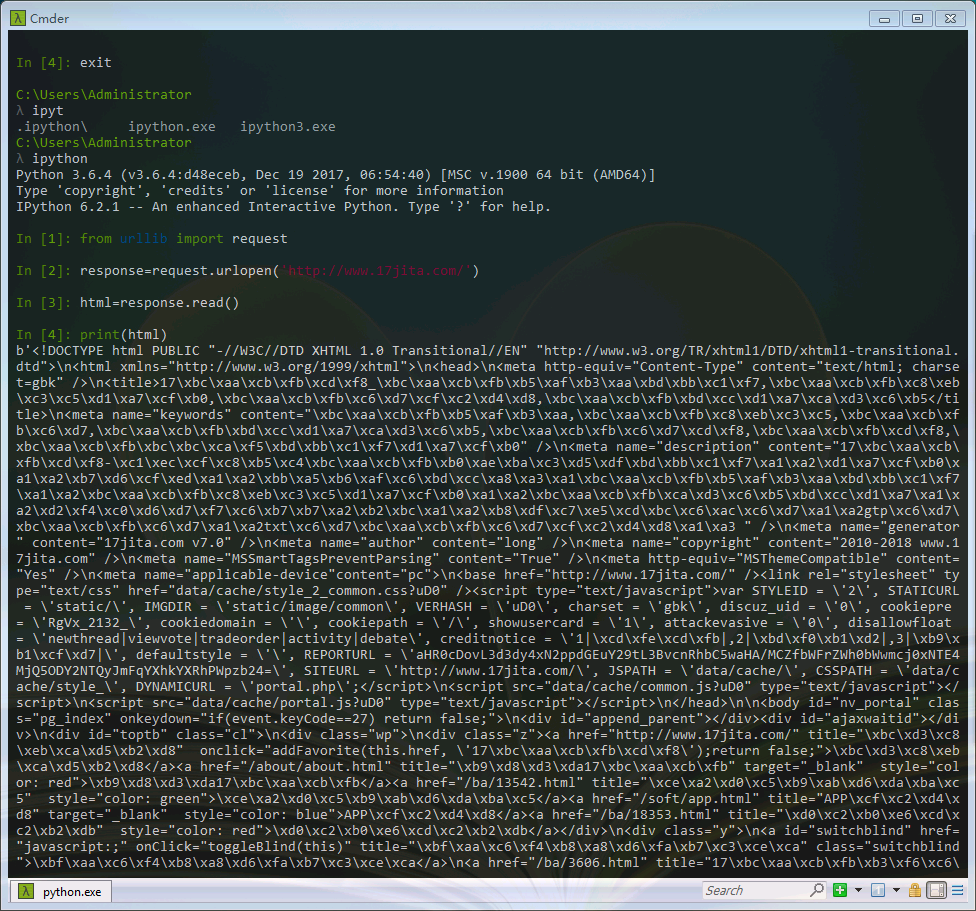
看起来有些乱码,别着急,我们可以通过简单的decode()命令将网页的信息进行解码,并显示出来.
from urllib import request
response=request.urlopen('http://www.17jita.com/')
html=response.read().decode('gbk')
print(html)

这样我们就可以利用python看到网页的源码了,这与在浏览器右键查看网页源代码所看到的是一致的。
值得注意的是,在使用decode解码时,我们要了解到一些一些常用的编码方式,如:gbk,gb2312,utf-8,Unicode等等。python2的编码就常常为人所诟病,但是在在python3中,这个问题得到了解决。具体资料可以自行百度。
python爬虫(1)——urllib包的更多相关文章
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- 爬虫之urllib包
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 爬虫之urllib包以及request模块和parse模块
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- Python爬虫之Urllib库的基本使用
# get请求 import urllib.request response = urllib.request.urlopen("http://www.baidu.com") pr ...
随机推荐
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- 解决不同操作系统下git换行符一致性问题
一.不同操系统下的换行符CR回车 LF换行Windows/Dos CRLF \r\nLinux/Unix LF \nMacOS CR \r二.解决方法 打卡git bash,设置core.autocr ...
- iis配置完成,出现HTTP 错误 403.14 - Forbidden
版权声明:本文为博主原创文章,未经博主允许不得转载.转载请标明文章出处和原文链接. 403.14 禁止访问:在 Web 服务器上已拒绝目录列表 解决方案一:一般情况站点都是不会允许直接读取目录内容的, ...
- Git学习记录--git仓库
Git是一款强大的版本控制工具,与svn相比git的分布式提交,本地仓库等在使用时确实比较方便.当然两者之间各有优劣,我在这里不多做比较.由于之前少有接触git,只是零星大致地了解一点,所以找时间系统 ...
- 【开发技术】storyboard和nib的差别
在使用Storyboard管理的iOS应用中,它的组成部分为AppDelegate和ViewController这两个类以及MainStoryboard.storyboard文件组成.Storyboa ...
- 【开发技术】 B/S、C/S的区别
c/s 客户端----服务器端 可以用譬如vb或vc等语言开发,比如最常用的oicq就是. 需要在客户端安装软件. b/s 浏览器端----服务器端 ...
- 解决myeclipse10.1导出War包出错:Security Alert:Integrity check error
解决myeclipse10.1导出War包出错:Security Alert:Integrity check error 解决myeclipse10.1不能导出war包报 ============== ...
- 智能家居esp8266对接机智云
依然存在稳定性问题 机智云官网--机智云 一个比较详细的教程--esp8266 一开始采用的是esp12f 可是他太不稳定,总是掉线,机智云的固件我也是刷了无数遍,哎太难了. 我比较懒,走过了太多 ...
- Java常用类--处理日期
Date Date类在java.util包中.使用Date类的无参数构造方法创建的对象可以获取本地当前时间.一般来说,也只使用这个.因为date的很多方法都已经不推荐使用了,所以Date的功能大大的消 ...
- JavaScript基础:BOM的常见内置方法和内置对象
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 以下是正文. BOM的介绍 JavaScript的组成 JavaScript基础分为三 ...