python爬虫(1)——urllib包
人生苦短,我用python!
一、关于爬虫
鉴于我的windos环境使用命令行感觉非常不便,也懒得折腾虚拟机,于是我选择了一个折中的办法——Cmder。它的下载地址是:cmder.net
Cmder是一个增强型命令行工具,不仅可以使用windows下的所有命令,更爽的是可以使用linux的命令,shell命令。下载下来后,解压即可使用。稍加设置(具体的设置可以百度),你就会发现它比windos的cmd要好用的多。
爬虫分为通用爬虫和聚焦爬虫,我们所研究的就是聚焦爬虫——抓取网页时筛选,尽量只抓与需求相关的网页信息。而网络爬虫的抓取过程我们可以理解为模拟浏览器操作的过程,这个过程基于Http(超文本传输协议)和Https(安全版的Http)的。当我们向浏览器中输入https://www.baidu.com/时,它就会根据这个地址来获取网页信息。我们所输入的网址就是URL——统一资源定位符,它是用于完整地描述Internet上网页和其它资源的地址的一种标识方式。
二、Python的urllib包
在Python3中,我们可以使用urlib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一些处理URL的模块。我们可以使用help命令查看一下。
import urllib help(urllib)
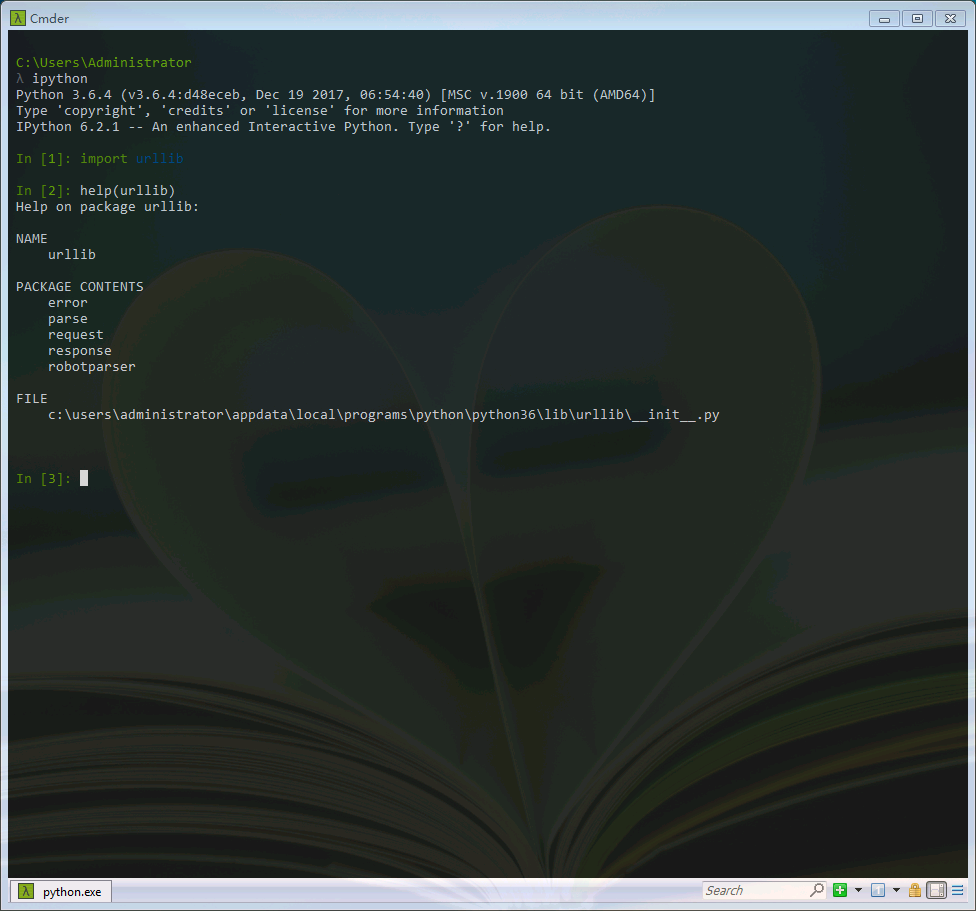
其中:
1.urllib.request模块是用来打开和读取URLs的;
2.urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理(可以学习一下python的异常处理机制);
3.urllib.parse模块包含了一些解析URLs的方法;
4.urllib.robotparser模块用来解析robots.txt(爬虫协议)文本文件,它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面。
三、下载一个页面
了解了以上这些,我们可以用request来尝试下载一个页面。在ipython中测试一下:
from urllib import request
response=request.urlopen('http://www.17jita.com/')
html=response.read()
print(html)
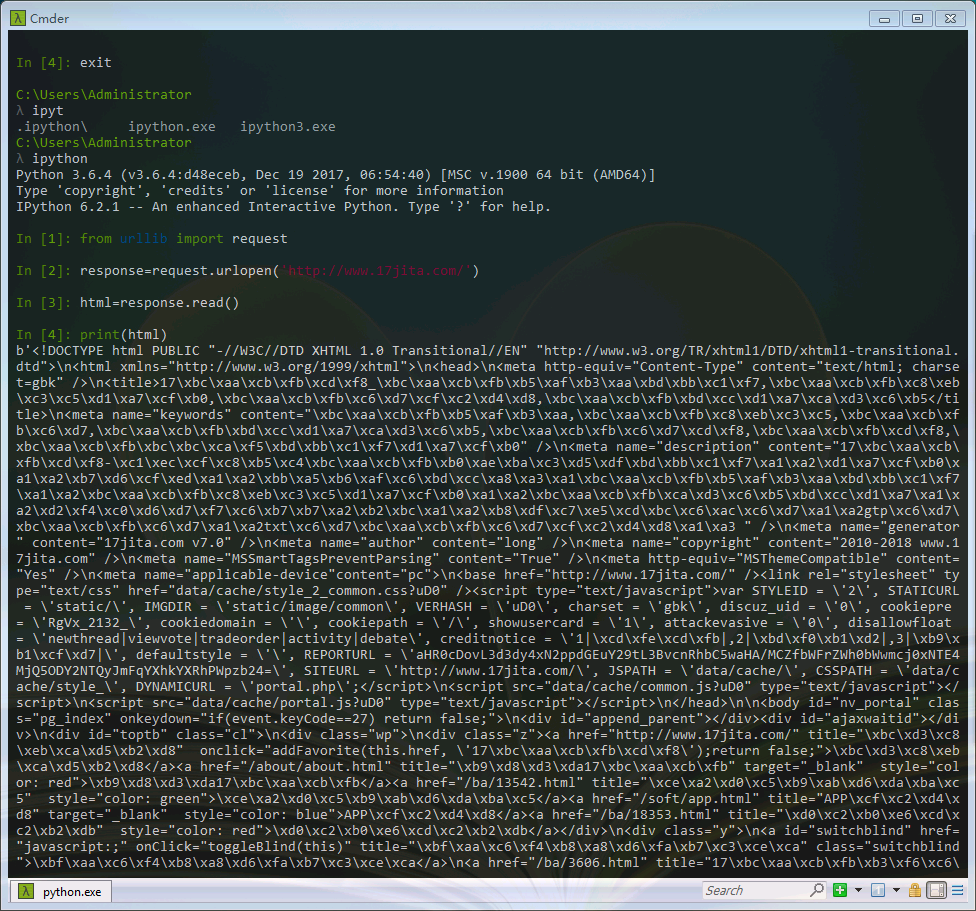
看起来有些乱码,别着急,我们可以通过简单的decode()命令将网页的信息进行解码,并显示出来.
from urllib import request
response=request.urlopen('http://www.17jita.com/')
html=response.read().decode('gbk')
print(html)

这样我们就可以利用python看到网页的源码了,这与在浏览器右键查看网页源代码所看到的是一致的。
值得注意的是,在使用decode解码时,我们要了解到一些一些常用的编码方式,如:gbk,gb2312,utf-8,Unicode等等。python2的编码就常常为人所诟病,但是在在python3中,这个问题得到了解决。具体资料可以自行百度。
python爬虫(1)——urllib包的更多相关文章
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- 爬虫之urllib包
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 爬虫之urllib包以及request模块和parse模块
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- Python爬虫之Urllib库的基本使用
# get请求 import urllib.request response = urllib.request.urlopen("http://www.baidu.com") pr ...
随机推荐
- ASP.NET CORE MVC 2.0 项目中引用第三方DLL报错的解决办法 - InvalidOperationException: Cannot find compilation library location for package
目前在学习ASP.NET CORE MVC中,今天看到微软在ASP.NET CORE MVC 2.0中又恢复了允许开发人员引用第三方DLL程序集的功能,感到甚是高兴!于是我急忙写了个Demo想试试,我 ...
- 【自制工具类】Java删除字符串中的元素
这几天做项目需要把多个item的id存储到一个字符串中,保存进数据库.保存倒是简单,只需要判断之前是否为空,如果空就直接添加,非空则拼接个"," 所以这个字符串的数据结构是这样的 ...
- 怎么使用linux命令重启服务器
一下的命令都可以重启Linux服务器: 1.shutdown -r now 2.reboot 3.startx
- RGB颜色设置错误
[UIColor colorWithRed:<#(CGFloat)#> green:<#(CGFloat)#> blue:<#(CGFloat)#> alpha:& ...
- mybatis一级缓存二级缓存
一级缓存 Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言.所以在参数和SQL完全一样的情况下,我们使用同一个SqlSess ...
- iterator_category
/* * 迭代器类型 * 1. input ierator * 2. write iterator * 3. forward iterator 在迭代器所形成的区间上进行读写操作 * 4. bidir ...
- 更改Patrol Agent的密码
大家可以使用P3console去做,具体方法请见:http://wenku.baidu.com/link?url=HbSzxNV2SPrlpk_Bfmcg0CNZuAlyX4jgdp4vbrxmynv ...
- junit参数化测试
在前面的junit4初体验中我就说过,junit参数化测试是一只小怪兽,只逼编码痛点,现在我们这里来整理一下. 看过我前面的那篇初体验的就会发现一个问题,我们的测试代码大量的重复了.在这里先贴出原来的 ...
- 根据URL下载图片至客户端、服务器实例
1.保存至服务器 根据路径保存至项目所在服务器上. String imgUrl="";//图片地址 try { // 构造URL URL url = new URL(imgUrl) ...
- shell参数传递
应用实例: #!/bin/bash #运行:bash para_tran.bash text1.txt text2.txt #"set $1"设置存储传入的第一参数 #" ...