基于keras的BiLstm与CRF实现命名实体标注
众所周知,通过Bilstm已经可以实现分词或命名实体标注了,同样地单独的CRF也可以很好的实现。既然LSTM都已经可以预测了,为啥要搞一个LSTM+CRF的hybrid model? 因为单独LSTM预测出来的标注可能会出现(I-Organization->I-Person,B-Organization ->I-Person)这样的问题序列。
但这种错误在CRF中是不存在的,因为CRF的特征函数的存在就是为了对输入序列观察、学习各种特征,这些特征就是在限定窗口size下的各种词之间的关系。
将CRF接在LSTM网络的输出结果后,让LSTM负责在CRF的特征限定下,依照新的loss function,学习出新的模型。
基于字的模型标注:
假定我们使用Bakeoff-3评测中所采用的的BIO标注集,即B-PER、I-PER代表人名首字、人名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分
- B-Person
- I- Person
- B-Organization
- I-Organization
- O
加入CRF layer对LSTM网络输出结果的影响
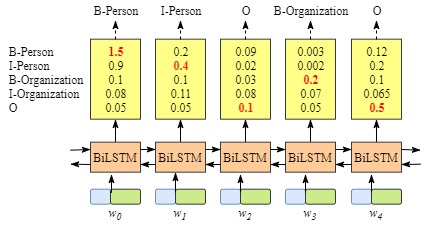
为直观的看到加入后的区别我们可以借用网络中的图来表示:其中\(x\)表示输入的句子,包含5个字分别用\(w_1\),\(w_2\),\(w_3\),\(w_4\),\(w_5\)表示
**没有CRF layer的网络示意图 **
含有CRF layer的网络输出示意图
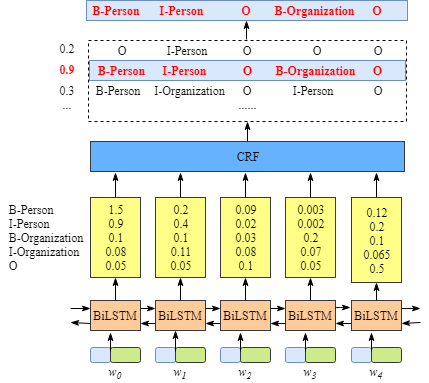
上图可以看到在没有CRF layer的情况下出现了 B-Person->I-Person 的序列,而在有CRF layer层的网络中,我们将 LSTM 的输出再次送入CRF layer中计算新的结果。而在CRF layer中会加入一些限制,以排除可能会出现上文所提及的不合法的情况
CRF loss function
CRF loss function 如下:
Loss Function = \(\frac{P_{RealPath}}{P_1 + P_2 + … + P_N}\)
主要包括两个部分Real path score 和 total path scroe
1、Real path score
\(P_{RealPath}\) =\(e^{S_i}\)
因此重点在于求出:
\(S_i\) = EmissionScore + TransitionScore
EmissionScore=\(x_{0,START}+x_{1,B-Person}+x_{2,I-Person}+x_{3,O}+x_{4,B-Organization}+x_{5,O}+x_{6,END}\)

因此根据转移概率和发射概率很容易求出\(P_{RealPath}\)
2、total score
total scroe的计算相对比较复杂,可参看https://createmomo.github.io/2017/11/11/CRF-Layer-on-the-Top-of-BiLSTM-5/
实现代码(keras版本)
1、搭建网络模型
使用2.1.4版本的keras,在keras版本里面已经包含bilstm模型,但crf的loss function还没有,不过可以从keras contribute中获得,具体可参看:https://github.com/keras-team/keras-contrib
构建网络模型代码如下:
model = Sequential()
model.add(Embedding(len(vocab), EMBED_DIM, mask_zero=True)) # Random embedding
model.add(Bidirectional(LSTM(BiRNN_UNITS // 2, return_sequences=True)))
crf = CRF(len(chunk_tags), sparse_target=True)
model.add(crf)
model.summary()
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
2、清洗数据
清晰数据是最麻烦的一步,首先我们采用网上开源的语料库作为训练和测试数据。语料库中已经做好了标记,其格式如下:
月 O
油 O
印 O
的 O
《 O
北 B-LOC
京 I-LOC
文 O
物 O
保 O
存 O
保 O
管 O
语料库中对每一个字分别进行标记,比较包括如下几种:
'O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"
分别表示,其他,人名第一个,人名非第一个,位置第一个,位置非第一个,组织第一个,非组织第一个
train = _parse_data(open('data/train_data.data', 'rb'))
test = _parse_data(open('data/test_data.data', 'rb'))
word_counts = Counter(row[0].lower() for sample in train for row in sample)
vocab = [w for w, f in iter(word_counts.items()) if f >= 2]
chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
# save initial config data
with open('model/config.pkl', 'wb') as outp:
pickle.dump((vocab, chunk_tags), outp)
train = _process_data(train, vocab, chunk_tags)
test = _process_data(test, vocab, chunk_tags)
return train, test, (vocab, chunk_tags)
3、训练数据
在处理好数据后可以训练数据,本文中将batch-size=16获得较为高的accuracy(99%左右),进行了10个epoch的训练。
import bilsm_crf_model
EPOCHS = 10
model, (train_x, train_y), (test_x, test_y) = bilsm_crf_model.create_model()
# train model
model.fit(train_x, train_y,batch_size=16,epochs=EPOCHS, validation_data=[test_x, test_y])
model.save('model/crf.h5')
4、验证数据
import bilsm_crf_model
import process_data
import numpy as np
model, (vocab, chunk_tags) = bilsm_crf_model.create_model(train=False)
predict_text = '中华人民共和国国务院总理周恩来在外交部长陈毅的陪同下,连续访问了埃塞俄比亚等非洲10国以及阿尔巴尼亚'
str, length = process_data.process_data(predict_text, vocab)
model.load_weights('model/crf.h5')
raw = model.predict(str)[0][-length:]
result = [np.argmax(row) for row in raw]
result_tags = [chunk_tags[i] for i in result]
per, loc, org = '', '', ''
for s, t in zip(predict_text, result_tags):
if t in ('B-PER', 'I-PER'):
per += ' ' + s if (t == 'B-PER') else s
if t in ('B-ORG', 'I-ORG'):
org += ' ' + s if (t == 'B-ORG') else s
if t in ('B-LOC', 'I-LOC'):
loc += ' ' + s if (t == 'B-LOC') else s
print(['person:' + per, 'location:' + loc, 'organzation:' + org])
输出结果如下:
['person: 周恩来 陈毅, 王东', 'location: 埃塞俄比亚 非洲 阿尔巴尼亚', 'organzation: 中华人民共和国国务院 外交部']
源码地址:https://github.com/stephen-v/zh-NER-keras
基于keras的BiLstm与CRF实现命名实体标注的更多相关文章
- BiLstm与CRF实现命名实体标注
众所周知,通过Bilstm已经可以实现分词或命名实体标注了,同样地单独的CRF也可以很好的实现.既然LSTM都已经可以预测了,为啥要搞一个LSTM+CRF的hybrid model? 因为单独LSTM ...
- bi-Lstm +CRF 实现命名实体标注
1. https://blog.csdn.net/buppt/article/details/82227030 (Bilstm+crf中的crf详解,包括是整体架构) 2. 邹博关于CRF的讲解视频 ...
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- 用CRF做命名实体识别(二)
用CRF做命名实体识别(一) 用CRF做命名实体识别(三) 一. 摘要 本文是对上文用CRF做命名实体识别(一)做一次升级.多添加了5个特征(分别是词性,词语边界,人名,地名,组织名指示词),另外还修 ...
- 使用CRF做命名实体识别(三)
摘要 本文主要是对近期做的命名实体识别做一个总结,会给出构造一个特征的大概思路,以及对比所有构造的特征对结构的影响.先给出我最近做出来的特征对比: 目录 整体操作流程 特征的构造思路 用CRF++训练 ...
- PyTorch 高级实战教程:基于 BI-LSTM CRF 实现命名实体识别和中文分词
前言:译者实测 PyTorch 代码非常简洁易懂,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中,相关的代码后续将会分享. 具体的数据格式,这种方式并不适合处理 ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
- Bi-LSTM+CRF在文本序列标注中的应用
传统 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息.有了词嵌入方法之后,词向量形式的词表征一般效果比 one-hot 表示的特征 ...
- 【NER】对命名实体识别(槽位填充)的一些认识
命名实体识别 1. 问题定义 广义的命名实体识别是指识别出待处理文本中三大类(实体类.时间类和数字类).七小类(人名.机构名.地名.日期.货币和百分比)命名实体.但实际应用中不只是识别上述所说的实体类 ...
随机推荐
- 第2章 PCI总线的桥与配置
在PCI体系结构中,含有两类桥片,一个是HOST主桥,另一个是PCI桥.在每一个PCI设备中(包括PCI桥)都含有一个配置空间.这个配置空间由HOST主桥管理,而PCI桥可以转发来自HOST主桥的配置 ...
- 笔记︱支持向量机SVM在金融风险欺诈中应用简述
本笔记源于CDA-DSC课程,由常国珍老师主讲.该训练营第一期为风控主题,培训内容十分紧凑,非常好,推荐:CDA数据科学家训练营 欺诈一般不用什么深入的模型进行拟合,比较看重分析员对业务的了解,从异常 ...
- Android开发中用到的第三方框架汇总
最近上网搜索了一些框架资料,整理了以下常用框架,希望在项目中有所帮助. 1.网络请求框架 android-async-http 该网络框架的介绍文章地址:http://www.cnblogs.com/ ...
- hi3531 SDK已编译文件系统制作jffs2文件系统镜像并解决问题 .
一, 安装SDK 1.Hi3531 SDK包位置 在"Hi3531_V100R001***/01.software/board"目录下,您可以看到一个 Hi3531_SDK_Vx. ...
- Linux查询一台机器的IP地址和其对应的域名
Linux查询一台机器的IP地址和其对应的域名 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ nslookup > 127.0.0.1 Server: ...
- Java中的List转换成JSON报错(四)
1.错误描述 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/colle ...
- struts2的配置文件
struts2的配置文件 1.配置Action的struts.xml 2.配置Struts2有关属性的struts.properties
- Django学习-2-初识settings文件
配置文件文档 https://docs.djangoproject.com/en/2.0/ref/ 1.添加APP的设置 INSTALLED_APPS = [ 'django.contrib.a ...
- Unity3D基本操作教程
物体操作图文教程 一些游戏资产文件 拖进游戏里 像这样,就可以上坡了 修改箱子的位置 完成 机械臂开始运作 游戏通关,教学结束
- Educational Codeforces Round 37
Educational Codeforces Round 37 这场有点炸,题目比较水,但只做了3题QAQ.还是实力不够啊! 写下题解算了--(写的比较粗糙,细节或者bug可以私聊2333) A. W ...