【深度学习篇】--神经网络中的池化层和CNN架构模型
一、前述
本文讲述池化层和经典神经网络中的架构模型。
二、池化Pooling
1、目标
降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)
减少输入图片大小(降低了图片的质量)也使得神经网络可以经受一点图片平移,不受位置的影响(池化后相当于把图片上的点平移了)
正如卷积神经网络一样,在池化层中的每个神经元被连接到上面一层输出的神经元,只对应一小块感受野的区域。我们必须定义大小,步长,padding类型
池化神经元没有权重值,它只是聚合输入根据取最大或者是求均值
2*2的池化核,步长为2,没有填充,只有最大值往下传递,其他输入被丢弃掉了
2、举例
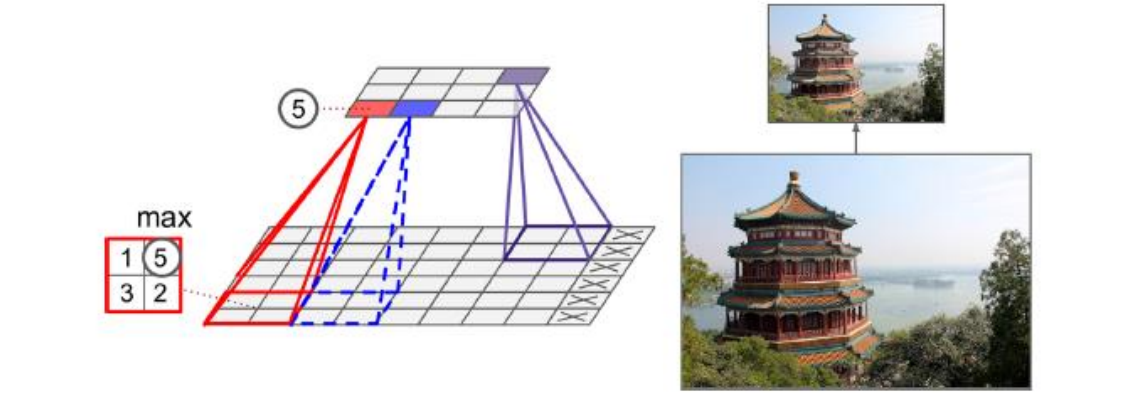
3、结论
长和宽两倍小,面积4倍小,丢掉75%的输入值
一般情况下,池化层工作于每一个独立的输入通道,所以输出的深度和输入的深度相同
4、代码
import numpy as np
from sklearn.datasets import load_sample_images
import tensorflow as tf
import matplotlib.pyplot as plt # 加载数据集
# 输入图片通常是3D,[height, width, channels]
# mini-batch通常是4D,[mini-batch size, height, width, channels]
dataset = np.array(load_sample_images().images, dtype=np.float32)
# 数据集里面两张图片,一个中国庙宇,一个花
batch_size, height, width, channels = dataset.shape
print(batch_size, height, width, channels)# channels是3个 # 创建输入和一个池化层
X = tf.placeholder(tf.float32, shape=(None, height, width, channels))
# TensorFlow不支持池化多个实例,所以ksize的第一个batch size是1
# TensorFlow不支持池化同时发生的长宽高,所以必须有一个是1,这里channels就是depth维度为1
max_pool = tf.nn.max_pool(X, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')#没有卷积直接做池化
# avg_pool() with tf.Session() as sess:
output = sess.run(max_pool, feed_dict={X: dataset}) plt.imshow(output[0].astype(np.uint8)) # 画输入的第一个图像
plt.show()
总结:在一个卷积层里面,不同的卷积核步长和维度都一样的,每个卷积核的channel是基于上一层的channel来的
三、CNN架构
原理:
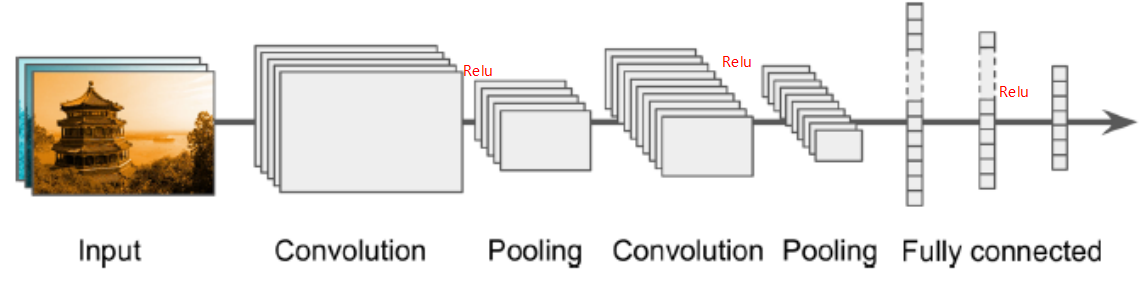
典型的CNN架构堆列一些卷积层
1、一般一个卷积层后跟ReLU层,然后是一个池化层,然后另一些个卷积层+ReLU层,然后另一个池化层,通过网络传递的图片越来越小,但是也越来越深,例如更多的特征图!(随着深度越深,宽度越宽,卷积核越多),这些层都是在提取特征。
2、最后常规的前向反馈神经网络被添加,由一些全连接的层+ReLU层组成,最后是输出层预测,例如一个softmax层输出预测的类概率(真正分类是最后全连接层)。
3、一个常见的误区是使用卷积核过大,你可以使用和9*9的核同样效果的两个3*3的核,好处是会有更少的参数需要被计算,还可以在中间多加一个非线性激活函数ReLU,来提供复杂程度(层次越多不是坏事)
图示:
【深度学习篇】--神经网络中的池化层和CNN架构模型的更多相关文章
- 神经网络中的池化层(pooling)
在卷积神经网络中,我们经常会碰到池化操作,而池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合).为什么可以通过降低维度呢? 因为图像具有一种“静态性”的属性,这 ...
- 深度学习面试题11:池化(same池化、valid池化、带深度的池化)
目录 Same最大值池化 多深度的same池化 Same平均值池化 Valid池化 参考资料 池化(Pooling)操作与卷积类似,取输入张量的每个位置的矩形领域内的最大值或平均值作为该位置的输出. ...
- 第十三节,使用带有全局平均池化层的CNN对CIFAR10数据集分类
这里使用的数据集仍然是CIFAR-10,由于之前写过一篇使用AlexNet对CIFAR数据集进行分类的文章,已经详细介绍了这个数据集,当时我们是直接把这些图片的数据文件下载下来,然后使用pickle进 ...
- CNN中的池化层的理解和实例
池化操作是利用一个矩阵窗口在输入张量上进行扫描,并且每个窗口中的值通过取最大.取平均或其它的一些操作来减少元素个数.池化窗口由ksize来指定,根据strides的长度来决定移动步长.如果stride ...
- [PyTorch 学习笔记] 3.3 池化层、线性层和激活函数层
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_others.py 这篇文章主要介绍 ...
- [DeeplearningAI笔记]卷积神经网络1.9-1.11池化层/卷积神经网络示例/优点
4.1卷积神经网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.9池化层 优点 池化层可以缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性. 池化层操作 池化操作与卷积操作类似 ...
- TensorFlow 池化层
在 TensorFlow 中使用池化层 在下面的练习中,你需要设定池化层的大小,strides,以及相应的 padding.你可以参考 tf.nn.max_pool().Padding 与卷积 pad ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- Keras深度神经网络算法模型构建【输入层、卷积层、池化层】
一.输入层 1.用途 构建深度神经网络输入层,确定输入数据的类型和样式. 2.应用代码 input_data = Input(name='the_input', shape=(1600, 200, 1 ...
随机推荐
- git回退到某个历史版本
1. 使用git log命令查看所有的历史版本,获取某个历史版本的id,假设查到历史版本的id是139dcfaa558e3276b30b6b2e5cbbb9c00bbdca96. 2. git res ...
- context.go
package nsqd type context struct { nsqd *NSQD }
- VUE+webpack+npm项目中的RSA加解密
一.安装jsencrypt npm i jsencrypt node_modules文件夹中出现jsencrypt 二.引入jsencrypt 在main.js中import: import JsEn ...
- JAVA中正则表达式总结
昨天,我的朋友请教我正则表达式.我也好久没有写过正则表达式了,昨天刚好看了下如鹏网创始人杨中科老师关于正则表达式的讲解.使我加深了正则表达式的印像.现我把他总结下: 许多语言,包括Perl.PHP.P ...
- 利用PowerUpSQL攻击SQL Server实例
这篇博客简述如何快速识别被第三方应用使用的SQL Server实例,该第三方软件用PowerUpSQL配置默认用户/密码配置.虽然我曾经多次提到过这一话题,但是我认为值得为这一主题写一篇简短的博客,帮 ...
- 再谈ERP选型
这几天收到老友的消息,谈及他们公司ERP选型的结果,基本上确定了使用Oracle EBS,因此闹了接近一年的选SAP还是选Oracle的纷争落下帷幕. 这家企业我去年曾去交流过,跟他们聊了一下ERP行 ...
- 浅谈URL跳转与Webview安全
学习信息安全技术的过程中,用开阔的眼光看待安全问题会得到不同的结论. 在一次测试中我用Burpsuite搜索了关键词url找到了某处url,测试一下发现waf拦截了指向外域的请求,于是开始尝试绕过.第 ...
- 浅析 .Net Core中Json配置的自动更新
Pre 很早在看 Jesse 的Asp.net Core快速入门的课程的时候就了解到了在Asp .net core中,如果添加的Json配置被更改了,是支持自动重载配置的,作为一名有着严重" ...
- 02 JVM 从入门到实战 | 什么样的对象需要被 GC
引言 上一篇文章 JVM 基本介绍 我们了解了一些基本的 JVM 知识,本篇开始逐步学习垃圾回收,我们都知道既然叫垃圾回收,那回收的就应该是垃圾,可是我们怎么知道哪些对象是垃圾呢? 哪些对象需要被回收 ...
- 彻底理解浏览器的缓存机制(http缓存机制)
一.概述 浏览器的缓存机制也就是我们说的HTTP缓存机制,其机制是根据HTTP报文的缓存标识进行的,所以在分析浏览器缓存机制之前,我们先使用图文简单介绍一下HTTP报文,HTTP报文分为两种: 同步s ...