SQLSERVER 临时表和表变量到底有什么区别?
一:背景
1. 讲故事
今天和大家聊一套面试中经常被问到的高频题,对,就是 临时表 和 表变量 这俩玩意,如果有朋友在面试中回答的不好,可以尝试看下这篇能不能帮你成功迈过。
二:到底有什么区别
1. 前置思考
不管是 临时表 还是 表变量 都带了 表 这个词,既然提到了 表 ,按推理自然会落到某一个 数据库 中,如果真在一个 数据库 中,那自然就有它的存储文件 .mdf 和 .ldf,那是不是如我推理的那样呢? 查阅 MSDN 的官方文档可以发现,临时表 和 表变量 确实都会使用 tempdb 这个临时存储数据库,而且 tempdb 也有自己的 mdf,ndf,ldf 文件,截图如下:
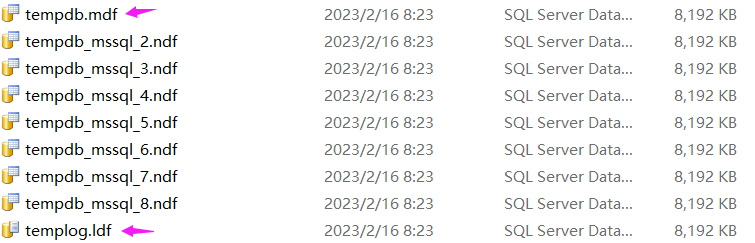
有了这个大思想之后,接下来就可以进行验证了。
2. 如何验证都存储在 tempdb 中 ?
要想验证其实很简单,sqlserver 提供了多种方式观察。
查询的过程中观察 tempdb 下是否存在
xxx表。使用动态管理视图
sys.dm_db_session_space_usage查询当前sql占用tempdb下的数据页个数。
为了让测试效果明显,我分别插入 10w 条记录观察 数据页 占用情况。
- 临时表插入 10w 条记录
CREATE TABLE #temp
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
GO
INSERT INTO #temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
GO
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;

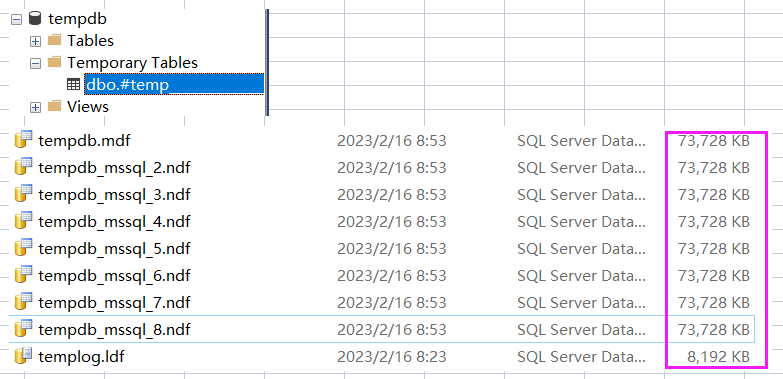
从图中的 user_objects_alloc_page_count=50456 看,当前的 insert 操作占用了 50456 个数据页。
接下来展开 tempdb 数据库以及观察到的 mdf 文件大小,都验证了存储到 tempdb 这个结论。
- 表变量插入 10w 条记录
因为表变量的特殊性,这里我故意暂停 1min 让查询迟迟得不到结束,在这期间方便展开 tempdb,重启 sqlserver 恢复初始状态后,执行如下 sql:
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;
WAITFOR DELAY '00:01:00'
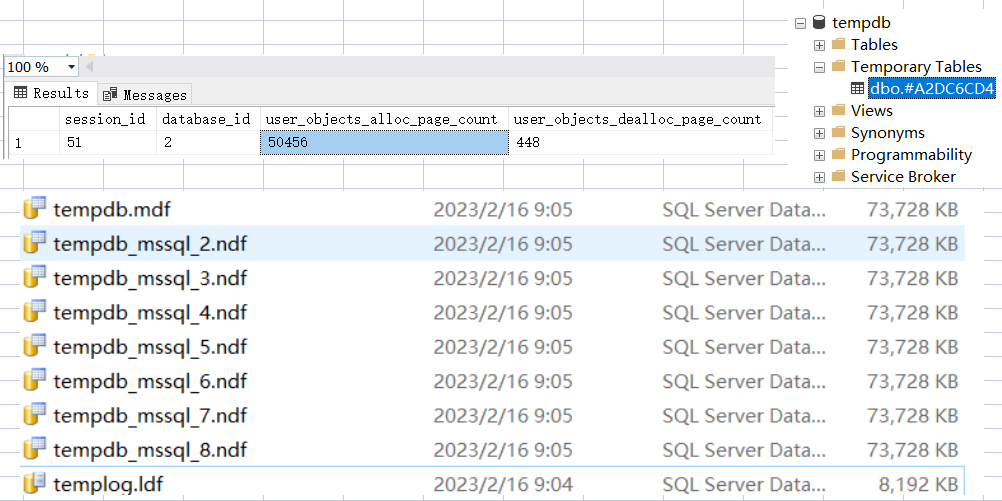
从图中可以看到 表变量 也会占用 5w+ 的数据页并且数据文件会膨胀。
3. 不同点在哪里
对底层存储有了了解之后,接下来按照重要度从高到低来了解一下区别吧。
- 临时表有统计信息,而表变量没有
所谓的 统计信息,就是对表数据绘制一个 直方图 来掌握数据的分布情况,sqlserver 在择取较优的执行计划时会严重依赖于这个 直方图,由于展开不了 Statistics 列,这里就从执行计划上观察,如下图所示:
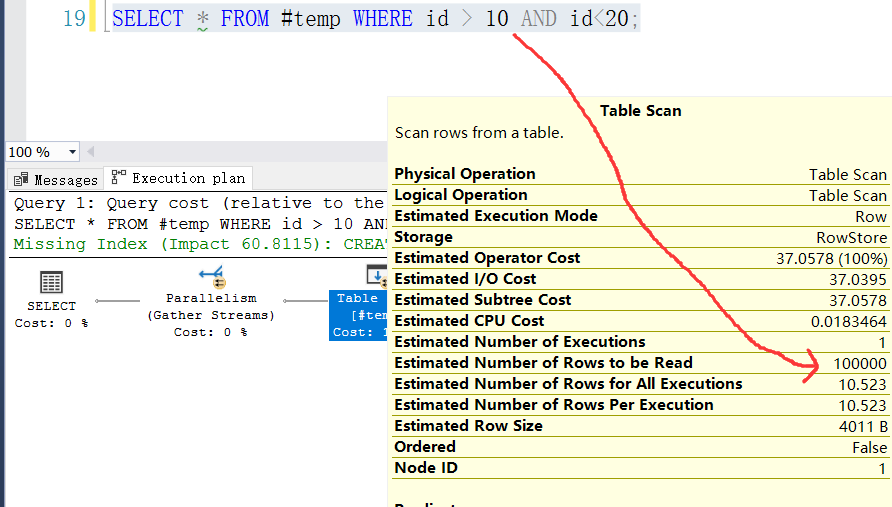
- 临时表下的执行计划
选中 SELECT * FROM #temp WHERE id > 10 AND id<20; 之后点击 SSMS 的评估执行计划按钮来观察下评估执行计划,可以清晰的看到 sqlserver 知道表中有多少条记录,截图如下:
- 表变量下的执行计划
由于表变量的批处理性,我们用 SET STATISTICS XML ON 把 xml 查询出来,然后点击观察可视化视图,参考sql 如下:
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SET STATISTICS XML ON
SELECT * FROM @temp WHERE id > 10 AND id<20;
SET STATISTICS XML OFF
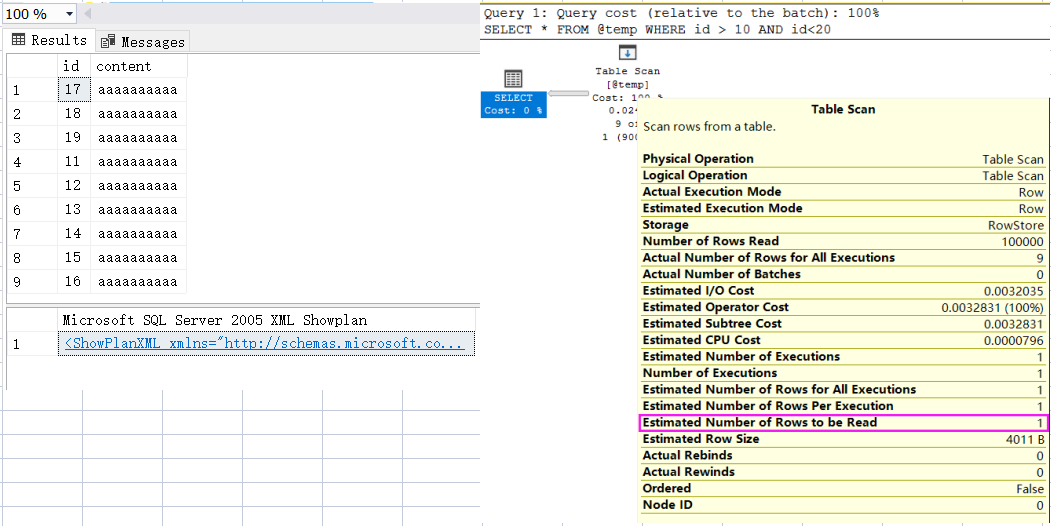
从图中可以清晰的看到,虽然表变量有 10w 条记录,但由于没有统计信息,sqlserver 也就无法知道这张表的数据分布,所以就按照默认值 1 条来计算。
从这里大家也能看得出来,如果 表记录 的真实条数 和 默认的 1 严重偏移的话,会给生成执行计划 造成重大失误,这个大家一定要当心了。
- 其它使用上的区别
除了上一个本质上的不同,接下来就是一些使用上的不同了,比如:
- 临时表是 session 级的,表变量是 批处理 级
所谓的批处理,就是以 go 为界定,两者就是作用域上的不同。
- 临时表可以后续修改,表变量不能后续修改。
这里的修改涉及到 字段,索引,整体上来说临时表在使用上和普通表趋同,表变量不能进行后续修改。
三:总结
总的来说,表变量 没有统计信息,也不可以后续做 DDL 操作,这种情况下 表变量 比 临时表 更轻量级,不会有如下副作用:
- DDL 修改导致执行计划过期重建
- sqlserver 对 统计信息 的维护压力
其实在这种作用域下高频的创建和删除表的操作中,表变量会让系统压力减轻很多。
但阳事总会有阴事来均衡它,一旦 表变量 的记录条数严重偏移默认的 1条,会污染sqlserver的执行计划择取,可能会让你的 sql 遭受灭顶之灾,所以一定要控制 表变量 的记录条数,最好在百条内 。
最后的建议是:如果你是个小白可以无脑使用 临时表 ,90%的情况下都可以做到通杀,如果你是个高手可以考虑一下 表变量。
SQLSERVER 临时表和表变量到底有什么区别?的更多相关文章
- sqlserver 临时表、表变量、CTE的比较
原文地址: sqlserver 临时表.表变量.CTE的比较 1.临时表 1.1 临时表包括:以#开头的局部临时表,以##开头的全局临时表. 1.2 存储 不管是局部临时表,还是全局临时表,都会放存 ...
- SqlServer 临时表 与 表变量(转)
1. 表变量 变量都以@或@@为前缀,表变量是变量的一种,另外一种变量被称为标量(可以理解为标准变量,就是标准数据类型的变量,例如整型int或者日期型DateTime).以@前缀的表变量是本地的,因此 ...
- sqlserver临时表或表变量代替游标
在很多场合,用临时表或表变量也可以替代游标 临时表用在表没有标识列(int)的情况下. 在表有标识列(int)的情况下可以用表变量,当然也可以用临时表. 利用临时表或表变量的原因时,生成一个连续的列 ...
- 转:sqlserver 临时表、表变量、CTE的比较
1.临时表 1.1 临时表包括:以#开头的局部临时表,以##开头的全局临时表. 1.2 存储 不管是局部临时表,还是全局临时表,都会放存在tempdb数据库中. 1.3 作用域 局部临时表:对当前连接 ...
- SqlServer 临时表、表变量、函数 替代游标
http://www.cnblogs.com/chongzi/archive/2011/01/19/1939106.html 临时表 存放在tempdb中 --存储过程中将多表连接结果写入到临时表中, ...
- 临时表VS表变量--因地制宜,合理使用
一直以来大家对临时表与表变量的孰优孰劣争论颇多,一些技术群里的朋友甚至认为表变量几乎一无是处,比如无统计信息,不支持事务等等.但事实并非如此.这里我就临时表与表变量做个对比,对于大多数人不理解或是有歧 ...
- SQLServer中临时表与表变量的区别分析(转)
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永 ...
- SQLServer中临时表与表变量的区别分析
临时表 临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在.临时表在创建的时候都会产生SQL Server的系统日志 ...
- SQLServer中临时表与表变量的区别分析【转】
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永 ...
- SQL Server进阶(十一)临时表、表变量
临时表 本地临时表 适合开销昂贵 结果集是个非常小的集合 -- Local Temporary Tables IF OBJECT_ID('tempdb.dbo.#MyOrderTotalsByYe ...
随机推荐
- mysql 在连接表中的要点
思路:分析需求,分析字段来自哪些表 (连接查询) 确定使用哪种连接查询? 确定交叉点(这两个表中哪些数据是相同的) 判断条件 such as 学生表中的 ...
- 第1章-Spring的模块与应用场景
目录 一.Spring模块 1. 核心模块 2. AOP模块 3. 消息模块 4. 数据访问模块 5. Web模块 6. 测试模块 二.集成功能 1. 目标原则 2. 支持组件 三.应用场景 1. 典 ...
- 【ASP.NET Core】MVC控制器的各种自定义:特性化的路由规则
MVC的路由规则配置方式比较多,咱们用得最多的是两种: A.全局规则.就是我们熟悉的"{controller}/{action}". app.MapControllerRoute( ...
- Zabbix与乐维监控对比分析(二)——Agent管理、自动发现、权限管理
上期我们详细介绍了Zabbix与乐维监控的架构与性能对比分析,透过架构与性能对比分析,用户可以对乐维监控之所以能成为"Zabbix企业版"有一个初步的认知.本篇是Zabbix对比乐 ...
- MAUI Blazor (Windows) App 动态设置窗口标题
接着上一篇"如何为面向 Windows 的 MAUI Blazor 应用程序设置窗口标题?" Tips: 总所周知,MAUI 除了 Windows App 其他平台窗口是没有 Ti ...
- 【每日一题】【map操作】【滑动窗口所需元素】2021年12月22日-76. 最小覆盖子串
给你一个字符串 s .一个字符串 t .返回 s 中涵盖 t 所有字符的最小子串.如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" . 注意: 对于 t 中重复字符 ...
- 使用mysqldump备份与还原的mysql数据库
使用mysqldump备份与还原的mysql数据库 一.mysqldump命令介绍 1.mysqldump -help 查看命令介绍: mysqldump --help 2.mysqldump登录选项 ...
- kali使用命令ifconfig查询ip地址一直为127.0.0.1的解决办法
解决方法: 执行命令:dhclient -v,即可解决
- JavaScript:控制跳转:break、continue与标签
在循环结构中,经常需要使用关键字break和continue来控制跳转: 遇到break,就会跳出循环结构,执行循环体后面的代码: 遇到continue,就会跳出本次循环,进入下一次循环: 那么,假如 ...
- 万字干货! 使用docker部署jenkins和gitlab
阅读本文, 需要有基础的Git, Linux, Docker, Java, Maven, shell知识, 并最少有一台内存16G以上并已经安装好了Docker的机器. 1. 概述 2. 容器互联 3 ...