B+树叶子节点数据如何存储,以及如何查找某一条数据
MySQL索引背后的数据结构及算法原理
https://www.kancloud.cn/kancloud/theory-of-mysql-index 非常好
根据一条sql 如何查看索引结构等信息?
聚簇索引
数据库表中的数据都是存储在页里的,那么这一个页可以存放多少条记录呢?
这取决于一行记录的大小是多少,假如一行数据大小是1k,那么理论上一页就可以放16条数据。
当然,查询数据的时候,MySQL也不能把所有的页都遍历一遍,所以就有了索引,InnoDB存储引擎用B+树的方式来构建索引。
聚簇索引就是按照每张表的主键构造一颗B+树,叶子节点存放的是整行记录数据,在非叶子节点上存放的是键值以及指向数据页的指针,同时每个数据页之间都通过一个双向链表来进行链接。
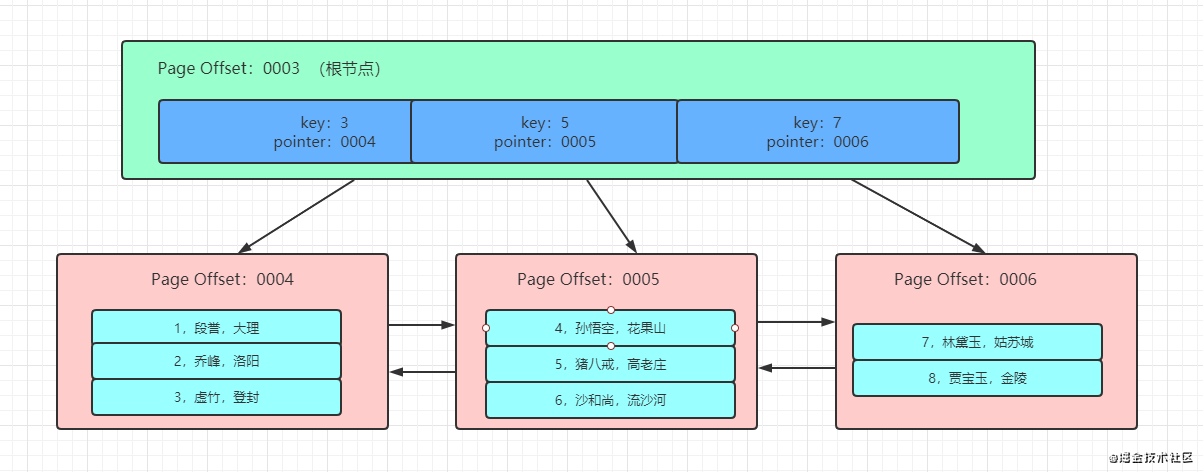
如上图所示,就是一颗聚簇索引树的大致结构。它先将数据记录按照主键排序,放在不同的页中,下面一行是数据页。上面的非叶子节点,存放主键值和一个指向页的指针。
当我们通过主键来查询的时候,比如id=6的条件,就是通过这颗B+树来查找数据的过程。它先找到根页面(page offset=3),然后通过二分查找,定位到id=6的数据在指针为5的页上。然后进一步的去page offset=5的页面上加载数据。
在这里,我们需要理解两件事:
上图中B+树的根节点(page offset=3),是固定不会变化的。只要表创建了聚簇索引,它的根节点页号就被记录到某个地方了。还有一点,B+树索引本身并不能直接找到具体的一条记录,只能知道该记录在哪个页上,数据库会把页载入到内存,再通过二分查找定位到具体的记录。
现在我们知道了InnoDB存储引擎最小存储单元是页,在B+树索引结构里,页可以放一行一行的数据(叶子节点),也可以放主键+指针(非叶子节点)。
上面已经说过,假如一行数据大小是1k,那么理论上一页就可以放16条数据。那一页可以放多少主键+指针呢?
假如我们的主键id为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节。这样算下来就是 16384 / 14 = 1170,就是说一个页上可以存放1170个指针。
一个指针指向一个存放记录的页,一个页里可以放16条数据,那么一颗高度为2的B+树就可以存放 1170 * 16=18720 条数据。同理,高度为3的B+树,就可以存放 1170 * 1170 * 16 = 21902400 条记录。
理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
那么,实际上到底是不是这样呢?我们接着往下看。
————————————————
版权声明:本文为CSDN博主「Java大杨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_49723683/article/details/110958312
B+树叶子节点数据如何存储,以及如何查找某一条数据的更多相关文章
- 获取所有树叶子节点 注册添加事件 if ($(node).tree('isLeaf', node.target)) 是否叶子节点
//获取所有树叶子节点 注册添加事件 if ($(node).tree('isLeaf', node.target)) 是否叶子节点 $(function () { $('.easyui-tree') ...
- ztree树 叶子节点路径的集合
1.Question Description: ztree树各个节点都带有路径,如“/根节点”,"/根节点/一级节点",“根节点/一级节点/二级节点‘; 现在想获取所选的最末级节点 ...
- B树叶子节点split
一.B-Tree索引的分裂 1. 创建测试表 SQL> create table split_tab (id number, name varchar2(100)); 表已创建. SQL> ...
- linux 查找最后几条数据
tail(选项)(参数) -n<N>或——line=<N>:输出文件的尾部N(N位数字)行内容. 例如:grep 查询 2018-02-*/*.log |tail -n 5查询 ...
- SQL SERVER 算法面试题,自己再插入数据时,本想一次性复制10条数据,结果变成了1024条。产生一个算法bug,最后记录一下
- MySql的InnoDB的三层B+树可以存储两千万左右条数据的计算逻辑
总结/朱季谦 B+树是一种在非叶子节点存放排序好的索引而在叶子节点存放数据的数据结构,值得注意的是,在叶子节点中,存储的并非只是一行表数据,而是以页为单位存储,一个页可以包含多行表记录.非叶子节点存放 ...
- Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框
Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框 Jquery EasyUI Combotree单选框,Jquery EasyUI Combotree只能选择叶子节点 ...
- GEF中TreeViewer的叶子节点展开
/** * GEF树叶子节点的展开 * @param items */ private void expand(TreeItem[] items) { for (int i = 0; i < i ...
- python操作MONGODB数据库,提取部分数据再存储
目标:从一个数据库中提取几个集合中的部分数据,组合起来一共一万条.几个集合,不足一千条数据的集合就全部提取,够一千条的就用一万减去不足一千的,再除以大于一千的集合个数,得到的值即为所需提取文档的个数. ...
随机推荐
- SpringBoot 自定义参数类型转换convert
创建一个配置类.使用 @bean注入到容器中 @Bean public WebMvcConfigurer webMvcConfigurer(){ /** * 实现自定义的addConverter */ ...
- ASP.NET Core 6框架揭秘实例演示[08]:配置的基本编程模式
.NET的配置支持多样化的数据源,我们可以采用内存的变量.环境变量.命令行参数.以及各种格式的配置文件作为配置的数据来源.在对配置系统进行系统介绍之前,我们通过几个简单的实例演示一下如何将具有不同来源 ...
- libc++abi.dylib: terminating with uncaught exception of type NSException
这是微信sdk注册时候报的错误 解决方法 选择Build Setting,在"Other Linker Flags"中加入"-Objc -all_load"
- tomcat 配置https证书 ssl
修改tomcat-conf-server.xml,原配置文件是 <Connector connectionTimeout="20000" port="8080&qu ...
- jmeter参数化文件路径问题
问题 win下做好的带参数化文件的脚本,放到linux下运行,由于参数化文件路径不正确,导致脚本运行失败,如果解决这个问题呢? 方案一:参数化路径 比如,参数化文件我放到jmeter的bin目录下,参 ...
- 国内主流大数据厂商太多不知道怎么选?Smartbi满足你的需求
目前的BI市场上有很多大数据的厂商,这也让许多客户眼花缭乱,不知如何下手.比如国内的亿信华辰跟国外的Tableau,QLK, PowerBI 都有非常多便于分析的可视化工具,但是在数据处理分析的功能 ...
- 这款智能又高效的自助式BI工具,你应该了解一下
如今,企业的经营面临越来越激烈的竞争,如何将数据的价值发挥到最大化,成为众多企业急需解决的问题.如果部署数据分析平台还像以前那样要经历漫长实施过程的话,那么数据化运营将成为空谈.在市场需求的催化下,& ...
- pycharm创建模板
用pycharm构造作者模板 模板,就是创建一个文件时自动生成模板内容. 这里用pycharm创建作者模板,步骤如下: File-->Settings Editor-->File and ...
- Linux 网络时间同步
Linux的时间分为System Clock(系统时间)和Real Time Clock (硬件时间,简称RTC). 系统时间:指当前Linux Kernel中的时间. 硬件时间:主板上有电池供电的时 ...
- C# 逆变(Contravariance)/协变(Covariance) - 个人的理解
逆变(Contravariance)/协变(Covariance) 1. 基本概念 官方: 协变和逆变都是术语,前者指能够使用比原始指定的派生类型的派生程度更大(更具体的)的类型,后者指能够使用比原始 ...