B+树叶子节点数据如何存储,以及如何查找某一条数据
MySQL索引背后的数据结构及算法原理
https://www.kancloud.cn/kancloud/theory-of-mysql-index 非常好
根据一条sql 如何查看索引结构等信息?
聚簇索引
数据库表中的数据都是存储在页里的,那么这一个页可以存放多少条记录呢?
这取决于一行记录的大小是多少,假如一行数据大小是1k,那么理论上一页就可以放16条数据。
当然,查询数据的时候,MySQL也不能把所有的页都遍历一遍,所以就有了索引,InnoDB存储引擎用B+树的方式来构建索引。
聚簇索引就是按照每张表的主键构造一颗B+树,叶子节点存放的是整行记录数据,在非叶子节点上存放的是键值以及指向数据页的指针,同时每个数据页之间都通过一个双向链表来进行链接。
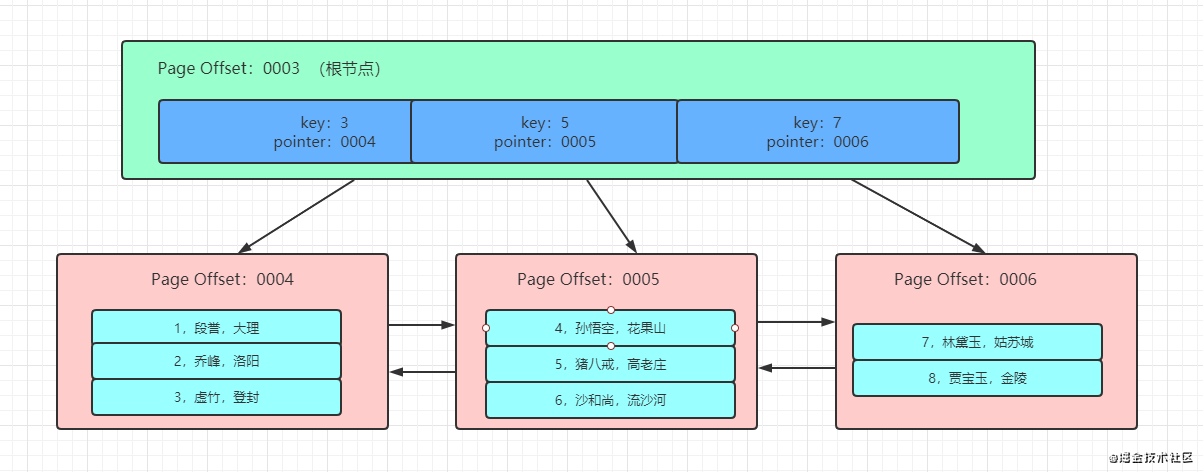
如上图所示,就是一颗聚簇索引树的大致结构。它先将数据记录按照主键排序,放在不同的页中,下面一行是数据页。上面的非叶子节点,存放主键值和一个指向页的指针。
当我们通过主键来查询的时候,比如id=6的条件,就是通过这颗B+树来查找数据的过程。它先找到根页面(page offset=3),然后通过二分查找,定位到id=6的数据在指针为5的页上。然后进一步的去page offset=5的页面上加载数据。
在这里,我们需要理解两件事:
上图中B+树的根节点(page offset=3),是固定不会变化的。只要表创建了聚簇索引,它的根节点页号就被记录到某个地方了。还有一点,B+树索引本身并不能直接找到具体的一条记录,只能知道该记录在哪个页上,数据库会把页载入到内存,再通过二分查找定位到具体的记录。
现在我们知道了InnoDB存储引擎最小存储单元是页,在B+树索引结构里,页可以放一行一行的数据(叶子节点),也可以放主键+指针(非叶子节点)。
上面已经说过,假如一行数据大小是1k,那么理论上一页就可以放16条数据。那一页可以放多少主键+指针呢?
假如我们的主键id为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节。这样算下来就是 16384 / 14 = 1170,就是说一个页上可以存放1170个指针。
一个指针指向一个存放记录的页,一个页里可以放16条数据,那么一颗高度为2的B+树就可以存放 1170 * 16=18720 条数据。同理,高度为3的B+树,就可以存放 1170 * 1170 * 16 = 21902400 条记录。
理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
那么,实际上到底是不是这样呢?我们接着往下看。
————————————————
版权声明:本文为CSDN博主「Java大杨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_49723683/article/details/110958312
B+树叶子节点数据如何存储,以及如何查找某一条数据的更多相关文章
- 获取所有树叶子节点 注册添加事件 if ($(node).tree('isLeaf', node.target)) 是否叶子节点
//获取所有树叶子节点 注册添加事件 if ($(node).tree('isLeaf', node.target)) 是否叶子节点 $(function () { $('.easyui-tree') ...
- ztree树 叶子节点路径的集合
1.Question Description: ztree树各个节点都带有路径,如“/根节点”,"/根节点/一级节点",“根节点/一级节点/二级节点‘; 现在想获取所选的最末级节点 ...
- B树叶子节点split
一.B-Tree索引的分裂 1. 创建测试表 SQL> create table split_tab (id number, name varchar2(100)); 表已创建. SQL> ...
- linux 查找最后几条数据
tail(选项)(参数) -n<N>或——line=<N>:输出文件的尾部N(N位数字)行内容. 例如:grep 查询 2018-02-*/*.log |tail -n 5查询 ...
- SQL SERVER 算法面试题,自己再插入数据时,本想一次性复制10条数据,结果变成了1024条。产生一个算法bug,最后记录一下
- MySql的InnoDB的三层B+树可以存储两千万左右条数据的计算逻辑
总结/朱季谦 B+树是一种在非叶子节点存放排序好的索引而在叶子节点存放数据的数据结构,值得注意的是,在叶子节点中,存储的并非只是一行表数据,而是以页为单位存储,一个页可以包含多行表记录.非叶子节点存放 ...
- Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框
Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框 Jquery EasyUI Combotree单选框,Jquery EasyUI Combotree只能选择叶子节点 ...
- GEF中TreeViewer的叶子节点展开
/** * GEF树叶子节点的展开 * @param items */ private void expand(TreeItem[] items) { for (int i = 0; i < i ...
- python操作MONGODB数据库,提取部分数据再存储
目标:从一个数据库中提取几个集合中的部分数据,组合起来一共一万条.几个集合,不足一千条数据的集合就全部提取,够一千条的就用一万减去不足一千的,再除以大于一千的集合个数,得到的值即为所需提取文档的个数. ...
随机推荐
- Dubbo扩展点应用之四线程池
线程池也是Dubbo自动自适应扩展点之一,也可以自定义线程池.Dubbo中已实现的线程池扩展点有: 其中框架提供的线程池都是通过创建真实的业务线程池进行操作的,目前线程池模型中有两个和Java中线程池 ...
- Visual Studio 2017-2019版本创建C#项目时没有创建网站这一选项?
通过了解以后发现Visual Studio 2017之后的版本在新建选项中已经不再有这一选择项了. 解决办法: 1.在创建新项目的面板滑倒最下面,---> 安装多个人工具和功能 2.这时已经打开 ...
- MLD协议测试——网络测试仪实操
一.简介 1. MLD简介 MLD · Multicast Listener Discovery Protocol · 组播侦听者发现协议 功能 · 在终端主机和与其直接相邻的组播路由器之间建立/维护 ...
- C#早期绑定&后期绑定
早期绑定(early binding),又可以称为静态绑定(static binding).在使用某个程序集前,已知该程序集里封装的方法.属性等.则创建该类的实例后可以直接调用类中封装的方法. 后期绑 ...
- java 执行shell命令遇到的坑
正常来说java调用shell命令就是用 String[] cmdAry = new String[]{"/bin/bash","-c",cmd} Runtim ...
- Python:Scrap爬虫过程中遇到的各种错误
1.KeyError: 'Spider not found: BDS' 原因:settings.py中缺少了几项与spider名字配置相关的项: BOT_NAME = 'BDS' SPIDER_MOD ...
- 千万级 PV是什么意思?
首先介绍下pv的概念: PV(访问量):即Page View,页面刷新一次算一次. UV(独立访客):即Unique Visitor,00:00-24:00内相同的客户端只被计算一次. IP(独立IP ...
- 爬虫之标签查找补充及selenium模块的安装及使用与案例
今日内容概要 bs模块之标签查找 过滤器 selenium模块 今日内容详细 html_doc = """ <html> <head> <t ...
- CPU长指令(VLIW)失败的主要原因是什么,VLIW真的无药可救吗?
software和hardware之间总是存在tradeoff:要么是hardware结构复杂,software灵活.要么是hardware结构保持简洁清晰,software干一些脏活累活.VLIW就 ...
- 使用windows自带linux子系统开发esp32
步骤: 1.打开windows商店,搜索ubuntu,安装18.04版本. 2.控制面板 /程序和功能 /打开或关闭windows功能 3.关机重启 4.打开刚安装得ubuntu,设置用户名和密码. ...