Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题。Tapdata 在解决 PostgreSQL 增量复制问题过程中,获得了一些不错的经验和思考,本文将分享 Tapdata 自研的 TAP-CDC-CACHE,和其他几种市面常见的解决方案的优势和特性。
前言
对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂 等等问题, 在解决这些问题的过程中, 我们逐渐对增量事件应该具备一个缓存中间件有了清晰的认识, 并在之后的时间里做了相应的实现PG 增量数据捕获的几种常见方案
基于复制槽的解码与查询
decoderbufs, wal2json, pgoutput 等等, TAPDATA 支持的插件, 其对应的数据库版本与特点如下: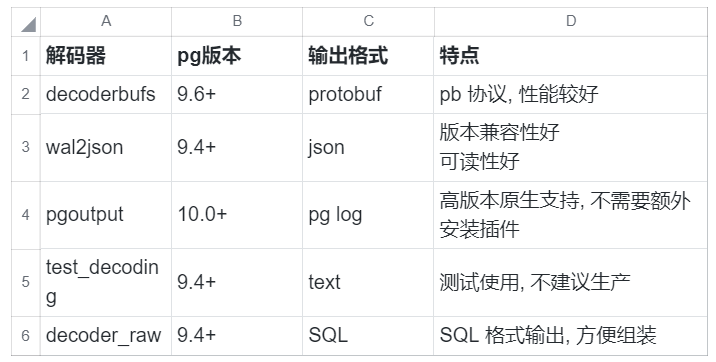
wal2json 为例, 具体的使用命令如下:## 创建一个 slot, 命名为 tapdata, 用来接收 CDC 事件, 并使用 wal2json 解析
select * from pg_create_logical_replication_slot('tapdata', 'wal2json'); ## 查看 slot 基本信息
select * from pg_replication_slots where slot_name='tapdata'; ## 从 slot 读取数据, 并清理读过的数据
## 方法支持的参数的为:
## 1. slot 名字, 必选
## 2. 一个 lsn 位置, 必选, 读取到这个位置为止, 剩下的此次查询不返回
## 3. 一个 limit 数字 n, 必选, 最多读取 n 条为止, 剩下的此次查询不返回, 与 lsn 满足任意一条即停止读取
## 4. options, 可选, 控制一些输出的数据内容, 具体可以查看: https://pgpedia.info/p/pg_logical_slot_get_changes.html
select * from pg_logical_slot_get_changes('tapdata', NULL, NULL) ## 从 slot 读取数据, 保留读过的数据, 参数与 pg_logical_slot_get_changes 完全一致
select * from pg_logical_slot_peek_changes('tapdata', NULL, NULL) ## select 支持使用 xid, lsn 等条件进行过滤, 比如限制返回的条目数为 10, 并且 lsn > '1/47CB8450', 可如下写
select * from pg_logical_slot_peek_changes('tapdata', NULL, NULL) where lsn > '1/47CB8450' limit 10 ## 由于 pg_logical_slot_peek_changes 不清理数据, 在需要清理 lsn 时, 可以使用 pg_replication_slot_advance
## 将 lsn 推进到指定位置, 并清理之前的记录
select * from pg_replication_slot_advance('tapdata', '1/47CB8450')
- 虚拟 CDC 表不包含任何索引, 使用 where 条件查询性能很糟糕
- 使用 pg_logical_slot_get_changes 会清除已经读取的数据, 无法实现多任务的数据复用, 只能创建多个互不关联的 slot 支持下游使用
- slot 数量受数据库配置限制, 无法动态调整
- 遗忘的 slot 会持续膨胀, 占用数据库存储资源
- slot 不支持过滤, 繁忙的数据库上数据量巨大, 即使在下游进行逻辑过滤, 其占用的带宽也难以避免
- 只可以在 主节点 使用, 在发生主从切换时, 机制会失效
- 不支持 DDL(结构变更, 比如表字段增加) 事件捕获, 只支持 DML(数据增删改) 事件捕获
- 不支持无唯一标记的 DML 事件捕获, 唯一标记可以是主键, 也可以是唯一索引
- 需要源库日志开启到 logic 级别, 增大了存储占用
- 不支持回溯获取历史数据变更, 只能获取到开启 slot 之后的变更
手动管理日志解析
## 列出 WAL 文件
select walminer_wal_list() ## 添加 WAL 文件或者 WAL 文件目录到待解析
select walminer_wal_add('/opt/test/wal') ## 解析日志
select walminer_all() ## 解析指定时间的 WAL 日志
select walminer_by_time(starttime, endtime) ## 解析指定 lsn 范围的 WAL 日志
select walminer_by_lsn(startlsn, endlsn) ## 查看解析结果
select * from walminer_contents ## 销毁解析任务
select walminer_stop()
- 可以解析任意时间段的日志, 不需要提前开启任务
- 不需要将日志级别设置为 logic, 节省空间
- 支持 DML/DDL 事件解析
- 可以对结果表创建索引, 进行基于时间和断点的范围查询
- 结果表占用了数据库存储资源
- 日志解析占用了数据库计算资源
- 事件查询占用了数据库计算与带宽资源
- 不支持并发解析, 用户需要自己进行细粒度数据管理
原生裸日志解析
WAL 日志方案的反思
- 故障恢复
- 主从同步
TAP-CDC-CACHE
- 分布式高可用: 基于 RAFT 的多副本同步机制, 可防止单点故障
- 无外部服务依赖: 部署便捷, 管理方便
- 丰富的存储端数据过滤: 支持多字段, 多级字段, 字段等于, 字段范围, IN Array, 多条件逻辑运算等过滤条件, 运行在服务端, 极大节省带宽和消费端算力
- 支持多生产者/消费者, 支持自动推进, ACK 推进等消费方式
- 高性能: 极致数据吞吐能力, 单节点可满足每秒数百万的事件读写能力
- 大容量: 基于普通磁盘读写能力进行设计, 支持数据压缩, 满足常见业务场景极长时间的历史增量事件存储需求
- 严格顺序保证: 针对同一个数据源的数据, 不使用分区存储, 保证数据的严格有序性, 虽然降低了部分处理性能, 但是对流计算场景来讲, 数据的准确性比性能更为重要
- 增量事件自动解析: 支持常见数据库事务日志格式, 原生写入, 自动解析并规整输出
- 事件补全: 基于全量数据 1:1 拷贝, 支持将部分不完整的增量事件, 比如没有开启 Full 的 Oracle Redo Log, MongoDB Oplog 缺少前值与完整后值的情况, 对数据进行自动补全, 方便下游进行各种计算处理
- 事件共享: 对一个确定的数据源实例, 只需要对源库进行一份增量事件读取, 下游所有消费者从缓存层获取数据, 避免对源库造成较大压力
- 支持时间和断点位置的双向转换: 通过大范围二级索引查找与精确查找遍历相结合的方式, 转换速度快, 资源消耗少
- 统一数据标准检测: 对 DML/DDL 描述抽象出一套异构数据库通用的描述, 包括统一可扩展的数据类型, 事件标准描述等规则, 并支持在缓存层进行检测, 保证进入下游的数据符合质量要求
- 支持指定范围的 全量+增量 自动合并结果返回, 在批流一体的精确一次数据输出场景, 可以做到对源库的无锁并发数据读取, 并极大简化了连接器的开发过程
典型工作模式

非标准日志补齐

全量增量数据合并

后言
- 对不完整事件进行补全
- 合并增量全量数据
- 时间/断点相互转换等问题
- 过滤器是非常消耗带宽的操作, 而常见的流存储产品不支持在 broker 进行计算
- 针对场景需求, 我们需要开发较多的 Stream 中间件
关于 Tapdata:
Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性的更多相关文章
- Tapdata 肖贝贝:实时数据引擎系列(四)-关于 Oracle 与 Oracle CDC
摘要:想实现 Oracle 的 CDC,排除掉一些通用的比如全量比对, 标记字段获取之外, 真正的增量形式获取变更, 有三种办法: Logminer .XStream .裸日志解析,但不管哪种方法 ...
- Tapdata肖贝贝:实时数据引擎系列(三) - 流处理引擎对比
摘要:本文将选取市面上一些流计算框架包括 Flink .Spark .Hazelcast,从场景需求出发,在核心功能.资源与性能.用户体验.框架完整性.维护性等方面展开分析和测评,剖析实时数据框架 ...
- 实时数据引擎系列(五): 关于 SQL Server 与 SQL Server CDC
摘要:在企业客户里, SQL Server 在传统的制造业依然散发着持久的生命力,SQL Server 的 CDC 复杂度相比 Oracle 较低, 因此标准的官方派做法就是直接使用这个 CDC ...
- Volley(六 )—— 从源码带看Volley的缓存机制
磁盘缓存DiskBasedCache 如果你还不知道volley有磁盘缓存的话,请看一下我的另一篇博客请注意,Volley已默认使用磁盘缓存 DiskBasedCache内部结构 它由两部分组成,一部 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- 【BW系列】SAP BW实时抽取ECC数据的实现
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[BW系列]SAP BW实时抽取ECC数据的实现 ...
- Tapdata Real Time DaaS 技术详解 PART I :实时数据同步
摘要:企业信息化过程形成了大量的数据孤岛,这些并不连通的数据孤岛是企业数字化转型的巨大挑战.Tapdata Real Time DaaS 采用的CDC模式,具有巨大的优势,同时是一个有技术壁垒的活 ...
随机推荐
- element.insertAdjacentHTML
一.概念 insertAdjacentHTML() 方法将指定的文本解析为 Element 元素,并将结果节点插入到DOM树中的指定位置.它不会重新解析它正在使用的元素,因此它不会破坏元素内的现有元素 ...
- java序列回显学习
java反序列化回显 在很多不出网的情况下,一种是写webshell(内存嘛),另一种就是回显,本文先学习回显,回显的主要方式有一下几种. defineClass RMI绑定实例 URLClassLo ...
- Java多线程—线程同步(单信号量互斥)
JDK中Thread.State类的几种状态 线程的生命周期 线程的安全问题(同步与互斥) 方法一:同步代码块 多个线程的同步监视器(锁)必须的是同一把,任何一个类的对象都可以 syn ...
- 为什么Redis要比Memcached更火?
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 前言 我们都知道,Redis和Memcached都是内存数据库,它们的访问速度非常之快.但我们 ...
- WinUI迁移到即将"过时"的.NET MAUI个人体验
迁移的初衷 本人平时是做.net相关的工作,对于.net技术栈也有一些了解,自从新的.net能够跨平台之后,之前也有跨平台的ui框架Xamarin,现在微软推出了.NET MAUI这个说是 统一了开发 ...
- 796. Rotate String - LeetCode
Question 796. Rotate String Solution 题目大意:两个字符串匹配 思路:Brute Force Java实现: public boolean rotateString ...
- [C++STL] 迭代器 iterator 的使用
定义 迭代器是一种检查容器内元素并遍历元素的数据类型,表现的像指针. 基本声明方式 容器::iterator it = v.begin();//例:vector<int>::iterato ...
- 安装Nmap到CentOS(YUM)
Nmap是Linux下的网络扫描工具,我们可以扫描远端主机上那些端口在开放状态. 运行环境 系统版本:CentOS Linux release 7.3.1611 (Core) 软件版本:无 硬件要求: ...
- Vulhub靶场搭建教程
Vulhub靶机环境搭建 Vulhub地址: Vulhub下载地址 一.所需环境 1.Ubuntu16.04 2.最新版本Docker 二.安装之路 1.下载Ubuntu16.04下载地址(迅雷下载6 ...
- NB-IoT无线通信模块与Lora无线通信协议技术分析与前景展望
物联网的快速发展对无线通信技术提出了更高的要求,专为低带宽.低功耗.远距离.大量连接的物联网应用而设计的LPWAN(low-power Wide-Area Network,低功耗广域网)也快速兴起.物 ...