如何优雅的升级 Flink Job?
Flink 作为有状态计算的流批一体分布式计算引擎,会在运行过程中保存很多的「状态」数据,并依赖这些数据完成任务的 Failover 以及任务的重启恢复。
那么,请思考一个问题:如果程序升级迭代调整了这些「状态」的数据结构以及类型,Flink 能不能从旧的「状态」文件(一般就是 Savepoint 文件)中恢复?
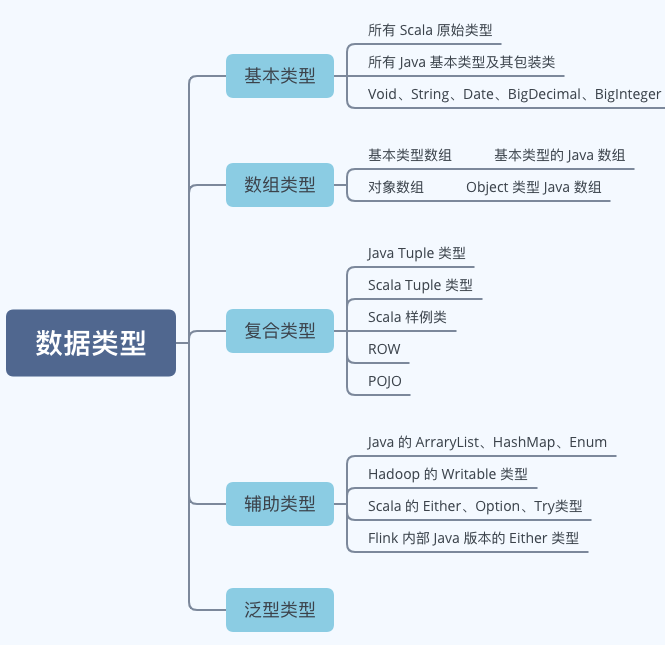
数据类型
上一篇我们介绍过 Flink 内置的一些用于状态存储的集合工具,如 ValueState、ListState、MapState 等。这些只是装数据的容器,具体能存储哪些类型的数据或许你还不清楚。
实际上,Flink 支持以下一些数据类型:
內建类型状态数据结构更新
Flink 中默认提供对一些特定条件下的状态数据结构升级的自动兼容,无需用户介入。
POJO 类型
Flink 基于下面的规则来支持 POJO 类型结构的升级:
可以删除字段。一旦删除,被删除字段的前值将会在将来的 checkpoints 以及 savepoints 中删除。 可以添加字段。新字段会使用类型对应的默认值进行初始化,比如 Java 类型。 不可以修改字段的声明类型。 不可以改变 POJO 类型的类名,包括类的命名空间。
其中,比较重要的是,对于一个 POJO 对象的某些字段的类型修改是不被支持的,因为 Savepoint 文件是按照二进制位紧凑存储的,不同类型占用的 bit 位长度是不一样的。
按照目前的 Flink 内置支持能力,最多对于 POJO 类型增加或者删除字段等基本操作。

Avro 类型
Avro 的 Schema 用 JSON 表示。Schema 定义了简单数据类型和复杂数据类型。Flink 完全支持 Avro 的 Schema 升级。
因为 Avro 本身就是一个高性能的数据序列化框架,它使用JSON 来定义数据类型和通讯协议,使用压缩二进制格式来序列化数据。
Flink 中相当于借助它完成数据的序列化和反序列化,那么理论上只要用户的 Schema 升级是 Avro 支持的,那么 Flink 也是完全支持的。
非內建类型状态数据结构更新
除了上述两种 Flink 内置支持的两种类型外,其余所有类型均不支持 Schema 升级。那么我们就只有通过自定义状态序列化器来完成对状态 Schema 升级的兼容。
序列化反序列化的流程
HashMapStateBackend 这种基于内存的状态后端和 EmbeddedRocksDBStateBackend 这种基于 RocksDb 的状态后端的序列化与反序列化流程稍有不同。
基于内存状态后端的序列化反序列化流程:
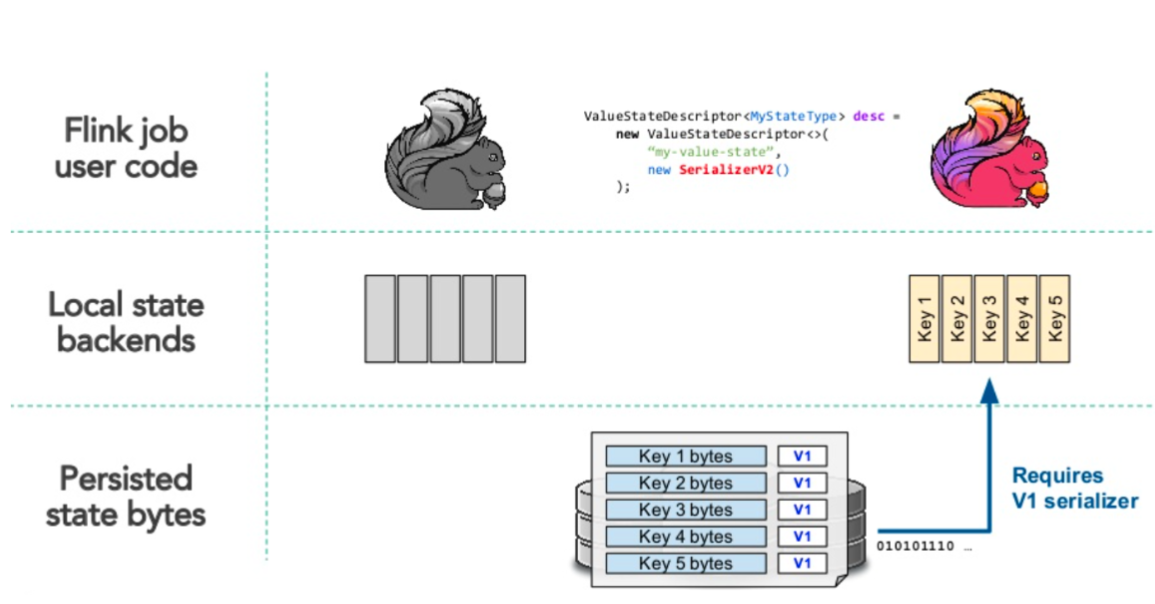
Job的相关状态的数据是以Object的形式存储在JVM内存堆中 通过Checkpoint/Savepoint机制将内存中的状态数据序列化到外部存储介质 新序列化器反序列化的时候会通过旧的序列化器反序列化数据到内存 基于内存中状态更新后再通过新序列化器序列化数据到外部存储介质
基于RocksDb状态后端的序列化反序列化流程:

Job的相关状态数据直接经过序列化器序列化好存储在JVM堆外内存中 通过Checkpoint/Savepoint机制将内存中序列化好的数据原样传输到外部存储介质 新序列化器反序列化的时候会从外部介质直接读取状态数据到内存(不做反序列化操作) 对于使用到的状态数据会使用旧序列化器先反序列化,再修改,再使用新序列化器序列化
其中,对于后面两个步骤与内存状态后端是有区别的,相当于是一种 lazy 的模式,只有用到才会去反序列化。
举个例子:状态中有个 KeyedState(我们知道每个Key会对应一个状态),那么如果某些 Key 的状态数据恢复到内存后没有被程序使用或者更新,那么下一次序列化的时候就不会使用新序列化器操作。
那么,结果就是:对于一个 Job 的 Checkpoint/Savepoint 文件里是存在多个版本的。这也是待会儿要提到的,对于每一次序列化都会把序列化器的相关配置以快照的形式和数据一起存储,这样才保证了多个版本状态数据存在的可能。
演示一个 Schema 升级状态恢复失败的 Demo
模拟一个订单系统上报数据的场景,计算每十秒系统的订单量以及下单数最多的用户
1、自定义一个 SourceFunction 模拟上游源源不断产生数据:
public class MakeDataSource extends RichSourceFunction<OrderModel> {
private boolean flag = true;
@Override
public void run(SourceContext<OrderModel> sourceContext) throws Exception {
List<String> userIdSet = Arrays.asList("joha", "nina", "gru", "andi");
Random random = new Random();
while(flag){
OrderModel order = new OrderModel();
order.setCreateTs(System.currentTimeMillis());
order.setOrderId(UUID.randomUUID().toString());
order.setUserId(userIdSet.get(random.nextInt(4)));
sourceContext.collect(order);
}
}
@Override
public void cancel() {
flag = false;
}
}
2、写一个 job 每十秒聚合一次窗口,输出用户产生的订单数量:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000 * 60);
env.getCheckpointConfig().setCheckpointStorage("file:///data/");
env.addSource(new MakeDataSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<OrderModel>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((SerializableTimestampAssigner<OrderModel>) (orderModel, l) -> orderModel.getCreateTs())
)
.keyBy((KeySelector<OrderModel, String>) orderModel -> orderModel.getUserId())
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<OrderModel, Tuple2<Long,String>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<OrderModel> elements, Collector<Tuple2<Long, String>> out) throws Exception {
Iterator<OrderModel> iterator = elements.iterator();
int count = 0;
while (iterator.hasNext()){
iterator.next();
count++;
}
logger.info("userid:{},count:{}",key,count);
}
});
env.execute("test_job");
}
WebUi 上看大概就是这个样子,由于我是本地 docker 起的集群,所以资源不是特别充足,并行度都是 1。
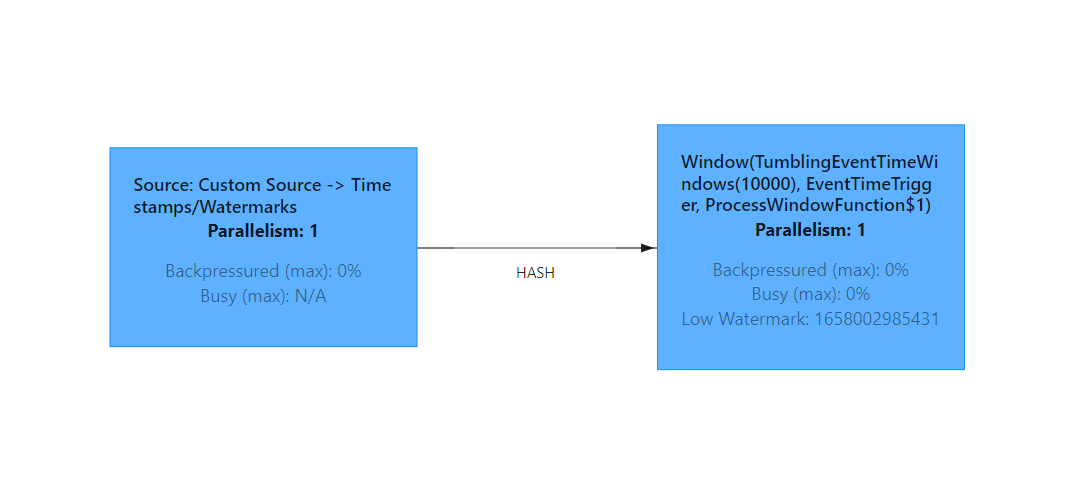
我们执行以下命令停止任务并生成 Savepoint:
root@ae894850e6ae:/opt/flink# flink stop 613c3662a4a4f5affa8eb8fb04bf4592
Suspending job "613c3662a4a4f5affa8eb8fb04bf4592" with a savepoint.
Savepoint completed. Path: file:/data/flink-savepoints/savepoint-613c36-3f0f01590c70
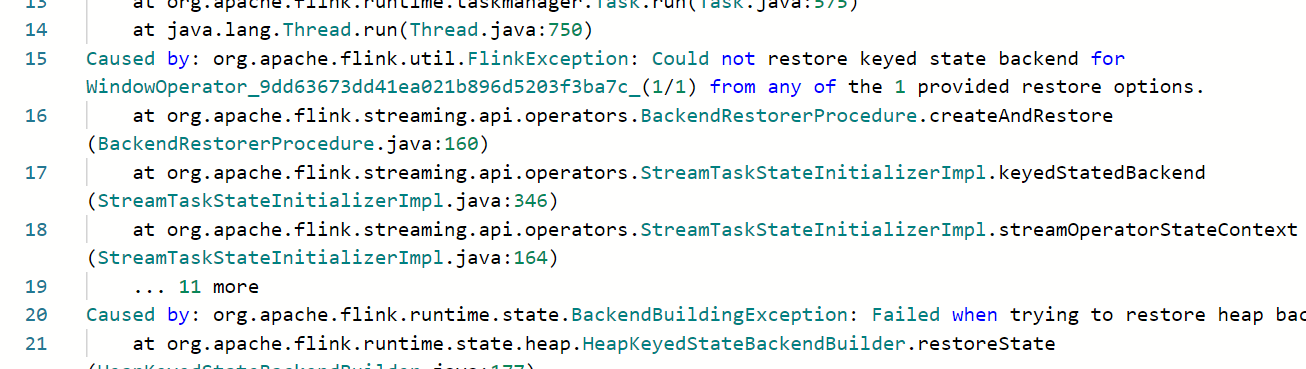
然后我们给我们的状态对象 OrderModel 的 orderId 字段类型从 String 给他改成 Integer。
再指定 Savepoint 重启 Job,不出意外的话,你应该也会得到这么个错误:
自定义状态序列化器
1、需要继承 TypeSerializer 并实现其中相关方法,其中比较重要的有这么几个:
//创建一个待序列化的数据类型实例
public abstract T createInstance();
//序列化操作
public abstract void serialize(T record, DataOutputView target) throws IOException;
//反序列化操作
public abstract T deserialize(DataInputView source) throws IOException;
//这个比较重要,用于对序列化器进行快照存储
public abstract TypeSerializerSnapshot<T> snapshotConfiguration();
2、对于 TypeSerializerSnapshot 来说它实际上就是提供了对序列化器的快照存储以及版本兼容处理,核心方法有这么几个:
//把当前序列化器以二进制格式和数据写到一起
void writeSnapshot(DataOutputView out) throws IOException;
//从当前输入流中,读出序列化器,一般会有一个类私有变量来存储
void readSnapshot(int readVersion, DataInputView in, ClassLoader userCodeClassLoader)throws IOException;
//检验当前序列化器是否能兼容之前版本
TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(TypeSerializer<T> newSerializer);
//重置当前序列化器为之前的一个序列化器
TypeSerializer<T> restoreSerializer();
这里面有两个比较核心,resolveSchemaCompatibility 传入一个新的序列化器,然后判断这个序列化器是否能够兼容反序列化之前版本序列化器序列化的数据,TypeSerializerSchemaCompatibility.type 枚举定义了可返回的类型:
enum Type {
//兼容,并且今后使用用户新定义的 Serializer
COMPATIBLE_AS_IS
//不兼容,需要重置之前序列化器反序列化后再使用新序列化器序列化
COMPATIBLE_AFTER_MIGRATION
//兼容,需要返回一个reconfiguredNewSerializer,替换传入的序列化器
COMPATIBLE_WITH_RECONFIGURED_SERIALIZER
//不兼容,作业抛异常退出
INCOMPATIBLE
}
那么对于我们上面的案例,把 POJO 中字段类型从 String 改成 Integer 的情况,其实只要重写 TypeSerializerSnapshot.resolveSchemaCompatibility 方法,返回 COMPATIBLE_AFTER_MIGRATION 类型,然后再 resolveSchemaCompatibility 中返回上一个版本的序列化器(可以反序列化String)即可。
限于篇幅就不再演示了,欢迎交流!
本文所有测试来自本地 docker 起的 Flink session 集群,如有需要 docker-compose.yml 文件的可以公众号回复「flink-docker」领取

如何优雅的升级 Flink Job?的更多相关文章
- 如何简单而优雅地升级Visual NMP中的PHP版本
需求:自己想测试下不同版本的PHP性能,就想升级下 Visual 这个集成环境中PHP的版本 网上: 升级PHP到5.6.11 1.下载新的nts版的PHP并解压缩到bin\PHP下,保留原文件夹的名 ...
- k8s实践 - 如何优雅地给kong网关配置证书和插件。
前言 从去年上半年微服务项目上线以来,一直使用kong作为微服务API网关,整个项目完全部署于k8s,一路走来,对于k8s,对于kong,经历了一个从无到有,从0到1的过程,也遇到过了一些坎坷,今天准 ...
- Flink实战(八) - Streaming Connectors 编程
1 概览 1.1 预定义的源和接收器 Flink内置了一些基本数据源和接收器,并且始终可用.该预定义的数据源包括文件,目录和插socket,并从集合和迭代器摄取数据.该预定义的数据接收器支持写入文件和 ...
- Apache Flink 1.9重磅发布!首次合并阿里内部版本Blink重要功能
8月22日,Apache Flink 1.9.0 版本正式发布,这也是阿里内部版本 Blink 合并入 Flink 后的首次版本发布.此次版本更新带来的重大功能包括批处理作业的批式恢复,以及 Tabl ...
- Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场 在各种环境中部署和操作Apache Flink的方法有很多.无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用. 在这个操场上,你将学习如何管理和运行Fl ...
- MySQL5.6 GTID新特性实践
MySQL5.6 GTID新特性实践 GTID简介 搭建 实验一:如果slave所需要事务对应的GTID在master上已经被purge了 实验二:忽略purged的部分,强行同步 本文将简单介绍基于 ...
- Flink1.9整合Kafka
本文基于Flink1.9版本简述如何连接Kafka. 流式连接器 我们知道可以自己来开发Source 和 Sink ,但是一些比较基本的 Source 和 Sink 已经内置在 Flink 里. 预定 ...
- 不吹不黑,今天我们来聊一聊 Kubernetes 落地的三种方式
作者 | 王国梁 Kubernetes 社区成员与项目维护者原文标题<Kubernetes 应用之道:让 Kubernetes落地的"三板斧">,首发于知乎专栏:进击 ...
- Kubernetes应用管理器OpenKruise之CloneSet
OpenKruise OpenKruise 是 Kubernetes 的一个标准扩展,它可以配合原生 Kubernetes 使用,并为管理应用容器.sidecar.镜像分发等方面提供更加强大和高效的能 ...
随机推荐
- Nacos在企业生产中如何使用集群环境?
点赞再看,养成习惯,微信搜索[牧小农]关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友. 项目源码地址:公众号回复 nacos,即可免费获取源码 前言 由于在公司,注册中心和配置中心都是 ...
- 【笔记】PyTorch快速入门:基础部分合集
PyTorch快速入门 Tensors Tensors贯穿PyTorch始终 和多维数组很相似,一个特点是可以硬件加速 Tensors的初始化 有很多方式 直接给值 data = [[1,2],[3, ...
- 论文解读《Measuring and Relieving the Over-smoothing Problem for Graph NeuralNetworks from the Topological View》
论文信息 论文标题:Measuring and Relieving the Over-smoothing Problem for Graph NeuralNetworks from the Topol ...
- 实战 | Linux根分区扩容
一个执着于技术的公众号 一个执着于技术的公众号 前言 Linux系统作为服务器操作系统,经常遇到一个问题就是服务器分区磁盘空间不足需要扩容的情况.本文以linux系统最常见的发行版centos7系统为 ...
- Web安全学习笔记 SQL注入中
Web安全学习笔记 SQL注入中 繁枝插云欣 --ICML8 权限提升 数据库检测 绕过技巧 一.权限提升 1. UDF提权 UDF User Defined Function,用户自定义函数 是My ...
- linux篇-linux下ffmpeg安装
1最近自己搭建的公司服务端转化视频不可以,我想应该是ffmpeg的问题,头痛 准备这两个源码包 2安装,先解压 ffmpeg-4.1.4.tar.bz2 yasm-1.3.0.tar.gz 3先安装y ...
- Android.mk编译App源码
在Andriod源码环境编译APP主要考虑如何引入第三方jar包和arr包的问题,初次尝试,步步是坑,这里给出一个模板: LOCAL_PATH := $(call my-dir) include $( ...
- GO的日志库log竟然这么简单!
前言 最近在尝试阅读字节开源RPC框架Kitex的源码,看到日志库klog部分,果不其然在Go原生的log库的基础上增加了自己的设计,大体包括增加了一些格式化的输出.增加一些常用的日志级别等. 一番了 ...
- Spring Cloud入门看这一篇就够了
目录 SpringCloud微服务 架构演进 服务调用方式: Euraka服务注册中心 注册中心 服务提供者(服务注册) 服务消费者(服务发现) 服务续约 失效剔除和自我保护 Consul 特性 Co ...
- Git出现“filename too long”错误处理
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月8日. 怎么肥事? Windows系统下,在Git使用过程中,出现"filename too long"错误提 ...