1.3 Apache Hadoop的重要组成-hadoop-最全最完整的保姆级的java大数据学习资料
1.3 Apache Hadoop的重要组成
Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common模块
- Hadoop HDFS:(Hadoop Distribute File System )一个高可靠、高吞吐量的分布式文件系统
比如:100T数据存储, “分而治之” 。分:拆分-->数据切割,100T数据拆分为10G一个数据块由一个电脑节点存储这个数据块。
数据切割、制作副本、分散储存
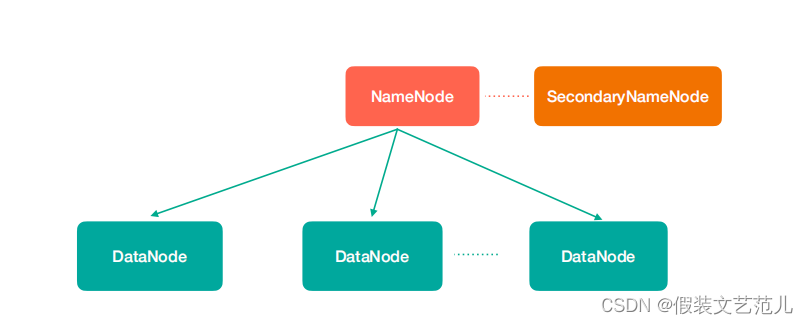
图中涉及到几个角色
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副 本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验
注意:NN,2NN,DN这些既是角色名称,进程名称,代指电脑节点名称!!
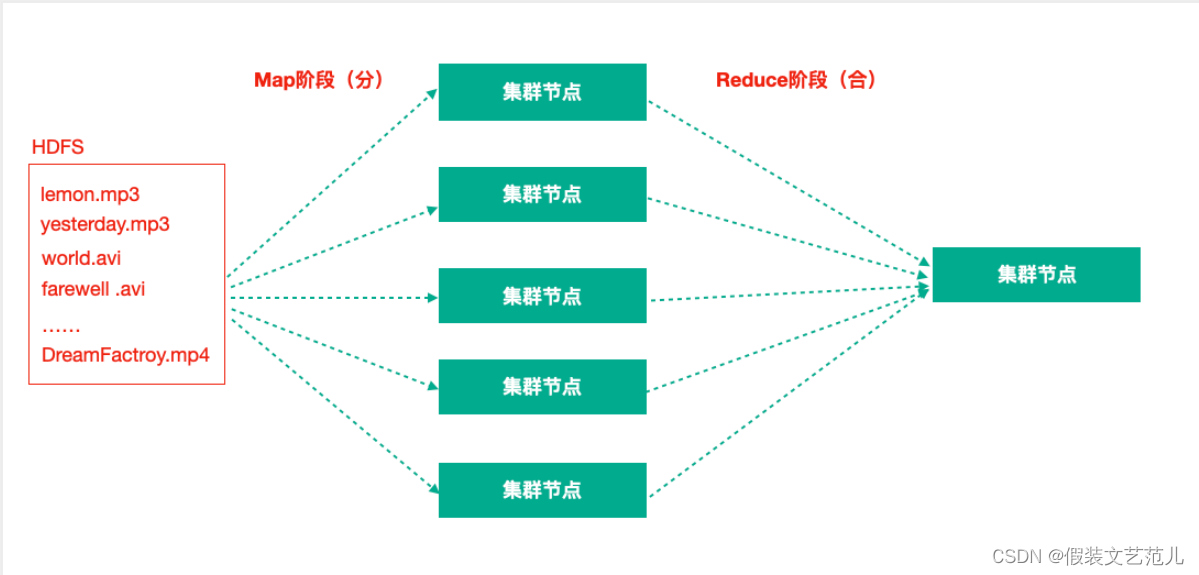
Hadoop MapReduce:一个分布式的离线并行计算框架
拆解任务、分散处理、汇整结果
MapReduce计算 = Map阶段 + Reduce阶段Map阶段就是“分”的阶段,并行处理输入数据
Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总
Hadoop YARN:作业调度与集群资源管理的框架
计算资源协调
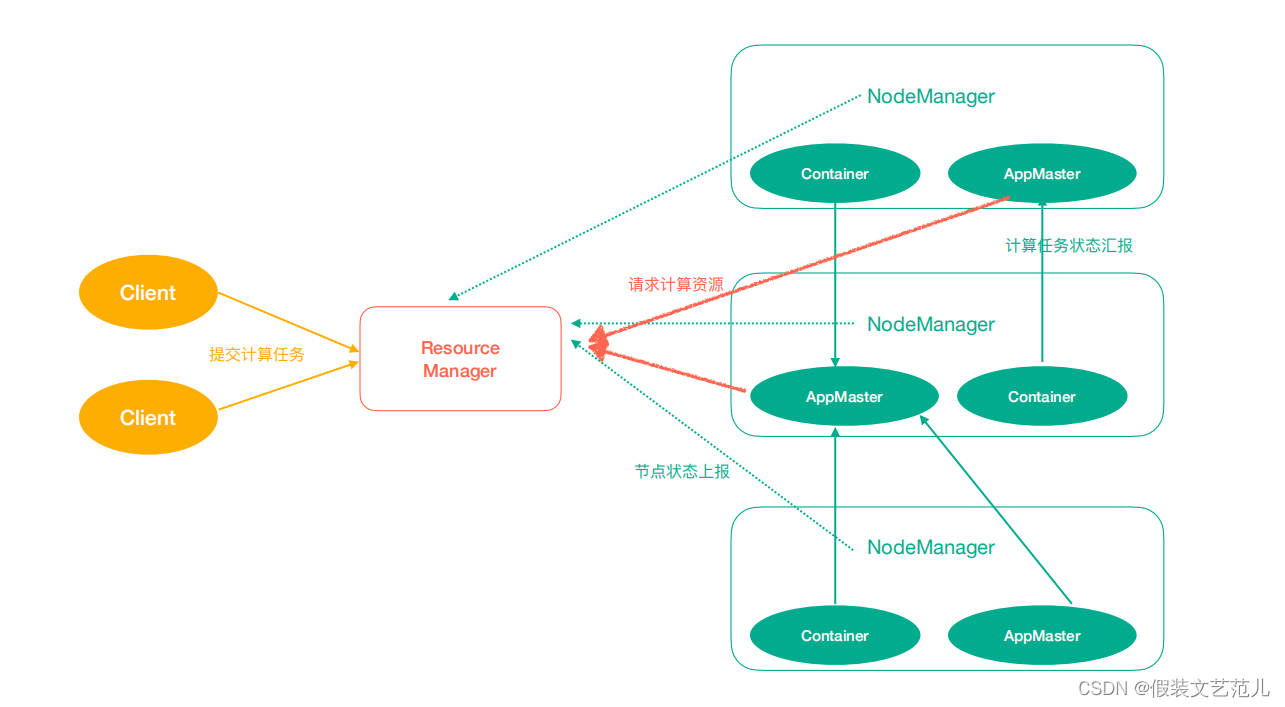
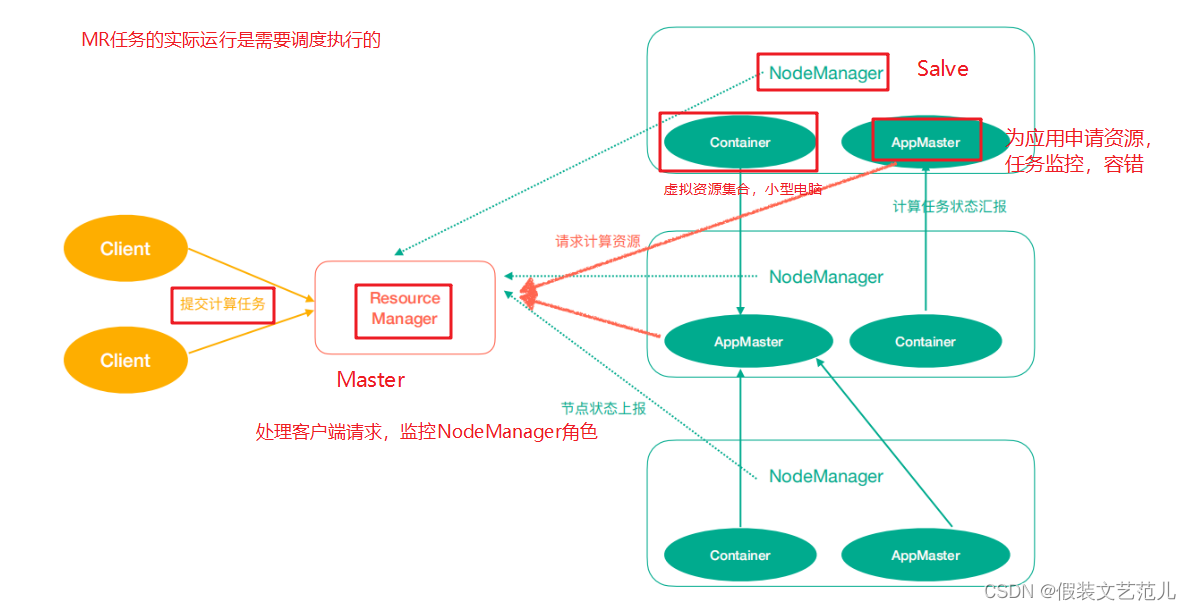
Yarn中有如下几个主要角色,同样,既是角色名、也是进程名,也指代所在计算机节点名称。
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
ResourceManager是老大,NodeManager是小弟,ApplicationMaster是计算任务专员。
- Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
1.3 Apache Hadoop的重要组成-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之一 ----- Hadoop环境搭建(单机)
一.环境选择 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内存:1G 硬盘:40G ip:39.108.77.250 2,配置选择 JD ...
- 大数据学习(1)Hadoop安装
集群架构 Hadoop的安装其实就是HDFS和YARN集群的配置,从下面的架构图可以看出,HDFS的每一个DataNode都需要配置NameNode的位置.同理YARN中的每一个NodeManager ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
随机推荐
- elementUI中page(分页)的使用方法
HTML部分 <!-- 快捷键 page-div --> <el-pagination background layout="sizes,prev, pager, next ...
- kali2020.1修改root密码,以最高权限登录系统
普通用户权限登录系统 sodu su切换为root权限 passwd root 按提示输入密码 再次输入密码 更新密码 右上角点切换用户 root/xxxx 更改成功,下面公布操图片
- 9. Ceph 基础篇 - Crush Maps
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485302&idx=1&sn=00a3a204 ...
- 查找Linux下的大目录或文件
目录 du -h --max-depth=1 du -h --max-depth=2 | sort -n du -hm --max-depth=2 | sort -n du -hm --max-dep ...
- Logstash: 如何创建可维护和可重用的Logstash管道
- shell下cat EOF中变量$处理
在使用cat EOF中出现$变量通常会直接被执行,显示执行的结果.若想保持$变量不变需要使用 \ 符进行注释 [root@localhost ~]# cat >> aa.txt <& ...
- Java调用C++动态链接库——Jni
最近项目需要,将C++的算法工程编译成动态链接库,交给 Java后台当作函数库调用.就去了解了下Jni.使用起来还是比较方便的. 1. 首先编写Java的调用类.例如: public clas ...
- 前端微信登录获取code,userInfo,openid
getUser(e) { wx.getUserProfile({ desc: '用户完善会员资料', success: res => { let userInfo = res.userInfo; ...
- jq判断页面滚动条进行样式修改
$(window).scroll(function(){//窗口的滚动条 if($(window).scrollTop()>100){ //垂直滚动条钓offset 大于90时. $(" ...
- C语言在Linux下创建一个僵尸进程
第三章编程题3.12 1.僵尸进程是什么 每一个进程都有一个PCB(进程控制块),其中包含进程执行的状态等一系列信息. 当父进程fork()出一个子进程,子进程执行结束后操作系统会回收子进程使用的内存 ...