【实时数仓】Day02-DWD、DIM层数据准备:各层职能、行为日志DWD层、业务日志DWD层及分流(Phoenix和HBASE)
一、需求分析及实现思路
1、分层需求
建立数仓目的:增加数据计算的复用性
可以从半成品继续加工而成
从kafka的ODS层(数据一开始就读到了kafka)读用户行为数据和业务数据,并写回到kafka的DWD层
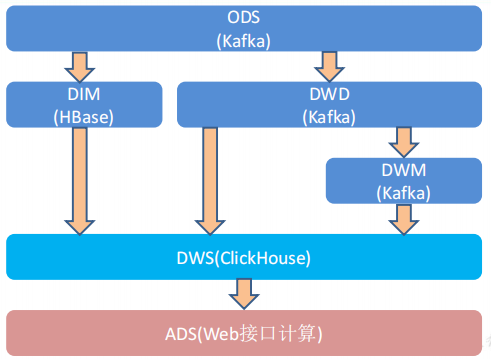
2、各层的职能
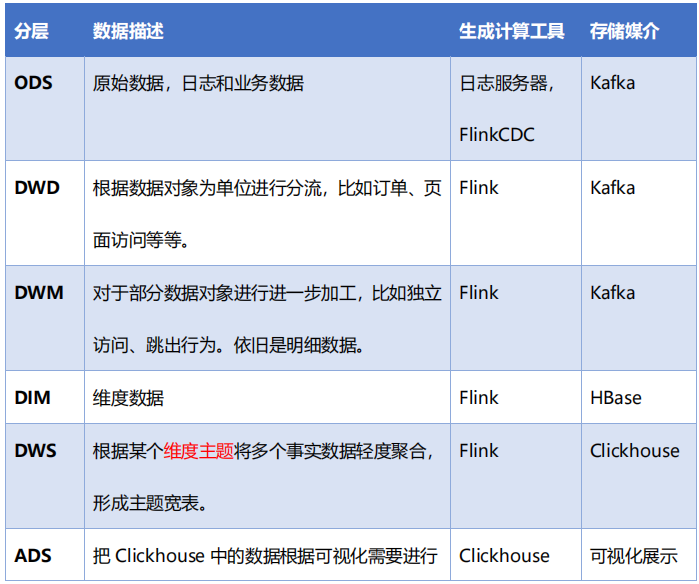
3、DWD层数据准备
环境搭建、计算用户行为日志DWD层、计算业务数据DWD层
二、环境搭建
1、在工程中新建模块gmall2021-realtime
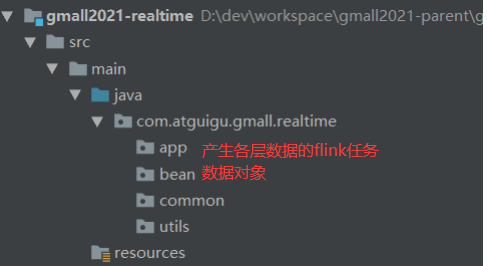
common:公共常量
2、引入依赖、log4j配置文件记录日志
三、准备用户行为日志DWD层
日志数据作为ODS层,已经导入到kafka,并分为三类:页面日志、启动日志和曝光日志
将不同日志写入到不同主题中,作为日志的DWD层
其中,页面日志输出到主流、启动日志输出到启动侧输出流、曝光日志输出到曝光侧输出流
1、主要任务
(1)识别新老用户-状态确认
(2)利用侧输出流实现数据拆分
(3)不同流推送到kafka中不同的topic中
2、代码实现
(1)接收kafka数据并进行转换
获取FlinkDataSourceConsumer,并将获取到的topic数据存入json的object
(2)识别新老访客
记录每个 mid 的首次访问日期,每条进入该算子的访问记录
jsonObjDS.keyBy(data -> data.getJSONObject("common").getString("mid"));
首次访问时间不为空,则为老用户,否则为新用户
同时,无首次访问时间,也会将当前访问时间写入首次访问时间
(3)利用侧输出流实现数据拆分
日志数据分为三类:页面日志、启动日志和曝光日志
提取json中的start字段,看是否为空
提取display字段,看是否为空,判断是否是曝光数据
(4)不同流的数据推送到不同topic(分流)
使用工具类获取sink,就可以将ds中的数据传到指定的topic
pageDS.addSink(MyKafkaUtil.getKafkaSink("dwd_page_log"));
运行jar包查看输出效果
四、准备业务数据DWD层
可以使用FlinkCDC采集业务数据的变化(MySQL),将全部数据保存到ODS层的一个topic中
但上述数据既包括事实表,也包括维度表
该功能是从ODS层读取数据,将维度数据保存到HBase,将事实数据写到DWD层
1、主要任务
接收kafka数据,过滤空值
实现动态分流(维度表写入数据库,事实表写入流中,处理后形成宽表),并通过动态配置方案实时感知(MySQL库存储并进行周期性的同步)
对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接
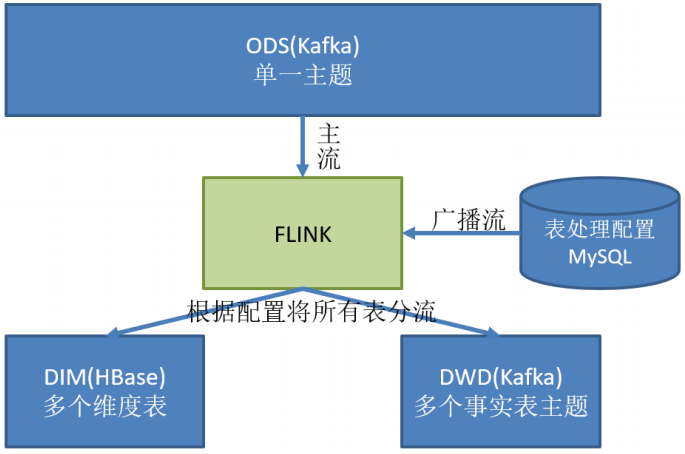
分好的流保存到对应的表和topic中
2、代码实现
(1)接收数据,过滤空值
获取json中的data字段,接口为空则返回true被过滤掉
(2)根据配置,动态分流【Phoenix中建表】
建立MySQL表table_process和对应的java Bean
来源表、输出类型、输出表/topic、主键字段、输出字段
读取配置表形成广播流
tableProcessDS.broadcast(mapStateDescriptor);
主流和广播流拼接
filterDS.connect(broadcastStream);
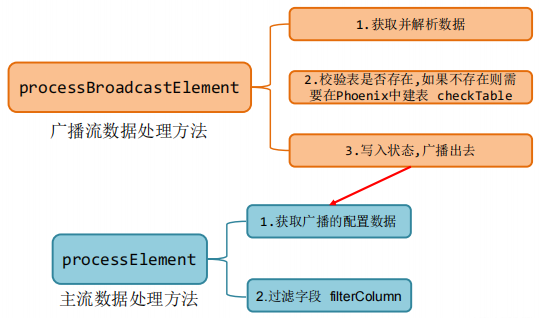
自定义TableProcessFunction-判断建表、发送到哪里(tableProcess.getSinkType()))
过滤多余字段,主程序调用上述函数进行分流
(3)分流sink并将维度表保存到HBase(Phoenix)
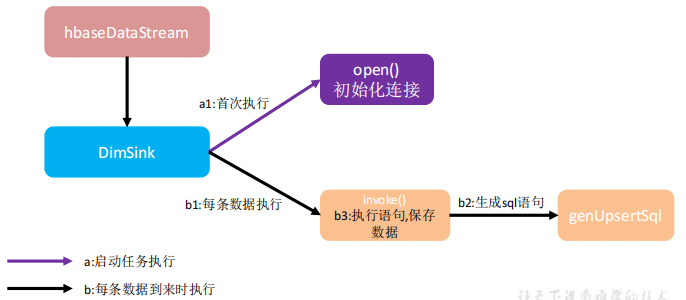
用单独的 schema,定义HBASE的配置文件
开启 hbase 的 namespace 和 phoenix 的 schema 的映射
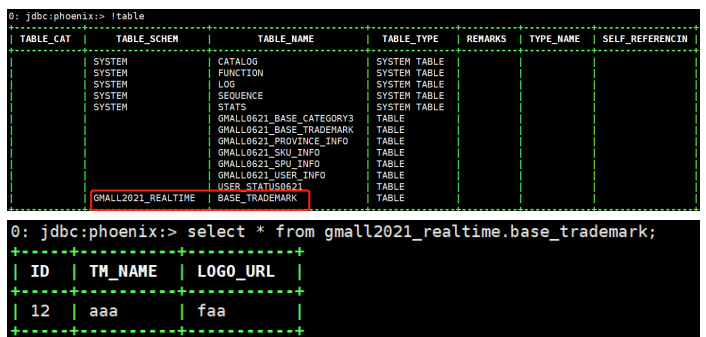
phoenix中建表,获取sink并使用Phoenix的方法插入到表中
插入数据并进行测试
(4)分流sink之保存业务数据到kafka topic
获取kafka的topic数据
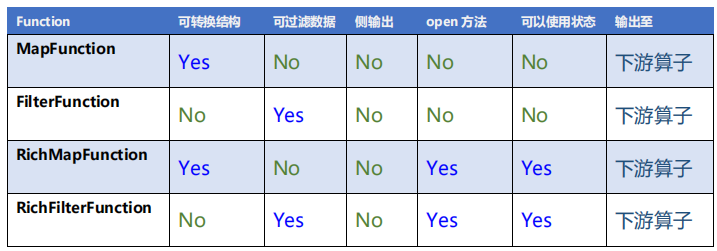
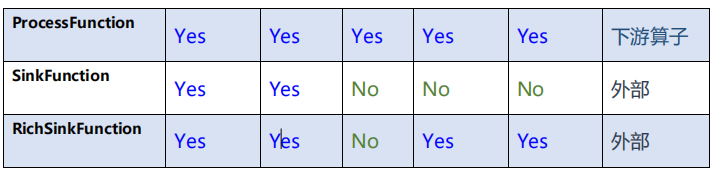
五、总结
数据分流和状态识别的算子比较
【实时数仓】Day02-DWD、DIM层数据准备:各层职能、行为日志DWD层、业务日志DWD层及分流(Phoenix和HBASE)的更多相关文章
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
- 【实时数仓】Day00:数据流程、课程内容、框架结构、知识点总结
一.数据流程 1.离线数仓 2.实时数仓 二.课程内容 1.数据采集层(ODS) 2.DWD层与DIM层数据准备 3.DWM层业务实现 4.DWS层业务实现 5.ClickHouse 6.数据可视化接 ...
- 【实时数仓】Day01-数据采集层:数仓分层、实时需求、架构分析、日志数据采集(采集到指定topic和落盘)、业务数据采集(MySQL-kafka)、Nginx反向代理、Maxwell、Canel
一.数仓分层介绍 1.实时计算与实时数仓 实时计算实时性高,但无中间结果,导致复用性差 实时数仓基于数据仓库,对数据处理规划.分层,目的是提高数据的复用性 2.电商数仓的分层 ODS:原始日志数据和业 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
随机推荐
- CVE-2022-39197(CobaltStrike XSS <=4.7)漏洞复现
最新文章更新见个人博客 漏洞说明 根据9.20日CobaltStrike官方发布的最新4.7.1版本的更新日志中介绍,<=4.7的teamserver版本存在XSS漏洞,从而可以造成RCE远程代 ...
- 关于MongoDB副本集和分片集群有关用户和权限的说明分析
1.MongoDB副本集 可以先创建超管用户,然后再关闭服务,创建密钥文件,修改配置文件,启动服务,使用超管用户登录验证,然后创建普通用户 2.MongoDB分片集群 先关闭服务,创建密钥文件,修改配 ...
- 复现禅道V16.5的SQL注入(CNVD-2022-42853)
漏洞详情 禅道V16.5未对输入的account参数内容作过滤校验,导致攻击者拼接恶意SQL语句执行. 环境搭建 环境下载:禅道V16.5 下载后双击运行,进入目录运行start.exe 直接访问即可 ...
- 内网横向渗透 之 ATT&CK系列一 之 横向渗透域主机
前言 上一篇文章中已获取了关于域的一些基本信息,在这里再整理一下,不知道信息收集的小伙伴可以看回上一篇文章哦 域:god.org 域控 windows server 2008:OWA,192.168. ...
- echarts BAR堆叠图显示百分比
在使用echarts的堆叠图时,我们鼠标悬停的浮窗里的信息可能并不是我们想要的信息,这个时候需要我们配置一下,因为堆叠图的trigger的类型是坐标轴触发的,数据是多组数据,所以我们需要遍历一下数据, ...
- 学习ASP.NET Core Blazor编程系列五——列表页面
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- 洛谷P2517 HAOI2010 订货 (费用流)
标准的费用流问题,关键在于巧妙地建模 一共有n个月份,源点设为0,汇点设为n+1 1.源点向所有月份连边,容量为正无穷,费用为该月进货的费用 2.每个月向下一个月连边,容量为仓库容量,费用为存货费用 ...
- 汇编指令:lea
lea指令变种(按大小分类): leaw #2个字节 leal #4个字节 leaq #8个字节 lea的用法: leaq a(b, c, d), %rax 首先lea指令是mov指令的变种,据说,l ...
- CQOI2015任务查询系统
题目链接 主席树. 把区间的影响挂在左端点与右端点,建树时顺便对应的插入与删除. 维护一段值域区间的和与数字个数,查询时要注意与第k大的数相同的数可能有很多. 复杂度O(nlogn) #include ...
- 第三方库openPyxl读取excel文件
import openpyxl from openpyxl.worksheet.worksheet import Worksheet def openpyxl_read(): #1.打开文件 work ...