python爬虫之企某科技JS逆向
python爬虫简单js逆向案例
在学习时需要用到数据,学习了python爬虫知识,但是在用爬虫程序的时候就遇到了问题。具体如下,在查看请求数据时发现返回的数据是加密的信息,现将处理过程记录如下,以便大家学习交流。
内容简介
需求:爬取某企科技网站投资事件栏目https://qimingpian.cn/finosda/project/einvestment的数据。
出现问题:获取数据首先需要发送请求,得到响应数据 。通过网页分析可知,需要获取的数据来自ajax发送POST请求动态获取,所以我选择通过向ajax的url发送请求得到响应数据。得到的返回数据是加密的,如下图所示。
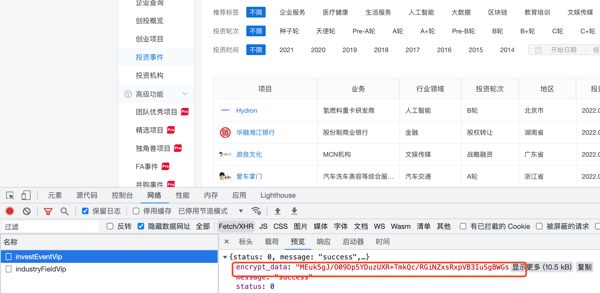
解决办法:通过分析浏览器请求到的相关js文件,找到解码部分代码,通过调用python中的js库execjs执行js代码
1.根据其关键字 encrypt_data进行全局搜索,寻找js的解密代码

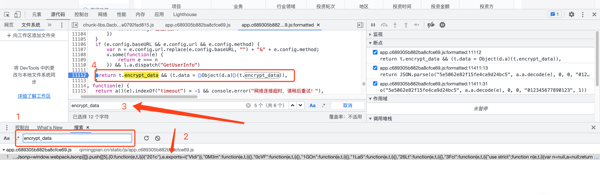
2.找到 return t.encrypt_data && (t.data = Object(d.a)(t.encrypt_data))
此处得到的代码就是解密encrypt_data。在引处打断点,然后点击跳入。
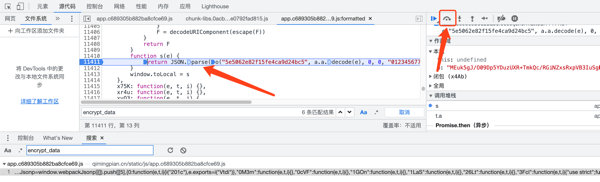
3.找到解析方法:
function s(e) {
return JSON.parse(o("5e5062e82f15fe4ca9d24bc5", a.a.decode(e), 0, 0, "012345677890123", 1))
}
4.调试到这里的时候参数e已经是之前接口中获取到的加密数据,通过JSON.parse转为json对象返回。
接下来重点分析这个区域的代码,可以看到,只有a.a.decode(e)调用了e,所以这个地方需要生成两个函数,一个是o(六个参数),另一个是其包含的这个函数decode(一个参数,也就是前面接口中获取到的encrypt_data),其他都是固定的字符串,将此方法o的js定义直接复制过来就行了
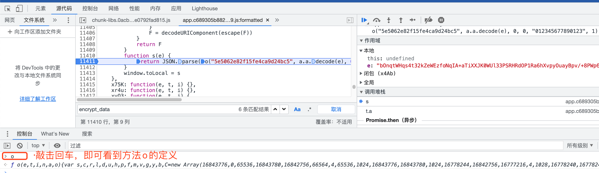
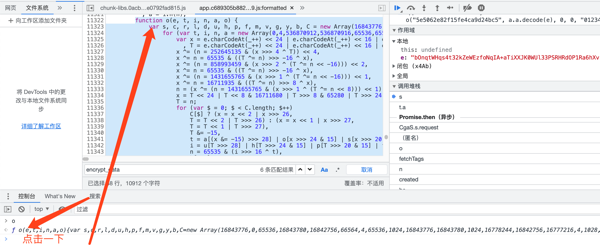
上面就是方法o的具体定义了,然后我们再找找decode方法。
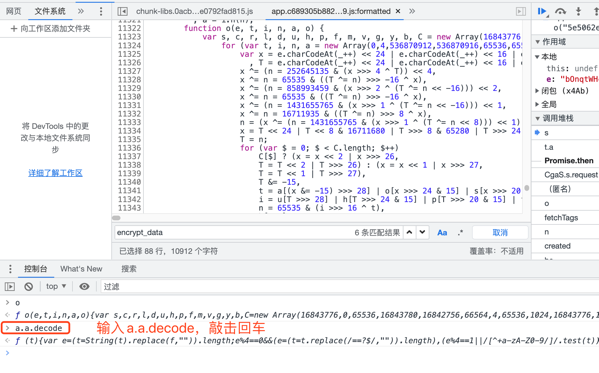
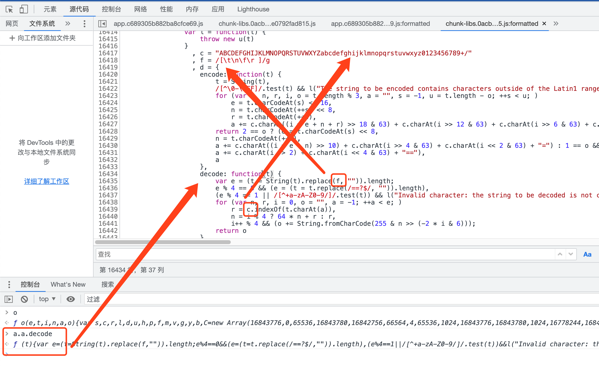
5.按照上面的方法找到decode方法,查看decode方法定义,其中用到两个变量f,c,其初始值在上方,替换即可。到此我们就把这两个方法定义全部搞定了。
接下来再根据网站中的逻辑将加密数据解密,我们自己写一个返回的方法。
function decrypt(t){
return JSON.parse(o("5e5062e82f15fe4ca9d24bc5", decode(t), 0, 0, "012345677890123", 1))
}
6.将上面的方法o和decode,以及decrypt方法写入qiming.js
然后在Python代码中使用execjs调用js中的方法就可以了。
with open("qiming.js", encoding='utf-8') as f:
js_code = f.read()
ctx = execjs.compile(js_code)
decrapy_data = ctx.call("decrypt", encrypt_data)
至此,数据已解密出来,接下来请继续做其它的处理操作。
python爬虫之企某科技JS逆向的更多相关文章
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- 网络爬虫之记一次js逆向解密经历
1 引言 数月前写过某网站(请原谅我的掩耳盗铃)的爬虫,这两天需要重新采集一次,用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时 ...
- 爬虫必看,每日JS逆向之爱奇艺密码加密,今天你练了吗?
友情提示:优先在公众号更新,在博客园更新较慢,有兴趣的关注一下知识图谱与大数据公众号,本次目标是抠出爱奇艺passwd加密JS代码,如果你看到了这一篇,说明你对JS逆向感兴趣,如果是初学者,那不妨再看 ...
- Python之手把手教你用JS逆向爬取网易云40万+评论并用stylecloud炫酷词云进行情感分析
本文借鉴了@平胸小仙女的知乎回复 https://www.zhihu.com/question/36081767 写在前面: 文章有点长,操作有点复杂,需要代码的直接去文末即可.想要学习的需要有点耐心 ...
- Python爬虫爬企查查数据
因为制作B2b网站需要,需要入库企业信息数据.所以目光锁定企查查数据,废话不多说,开干! #-*- coding-8 -*- import requests import lxml import sy ...
- python爬虫之JS逆向
Python爬虫之JS逆向案例 由于在爬取数据时,遇到请求头限制属性为动态生成,现将解决方式整理如下: JS逆向有两种思路: 一种是整理出js文件在Python中直接使用execjs调用js文件(可见 ...
- python爬虫之JS逆向某易云音乐
Python爬虫之JS逆向采集某易云音乐网站 在获取音乐的详情信息时,遇到请求参数全为加密的情况,现解解决方案整理如下: JS逆向有两种思路: 一种是整理出js文件在Python中直接使用execjs ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
随机推荐
- MySQL---什么是事务
什么是事务 一个数据库事务通常包含对数据库进行读或写的一个操作序列.它的存在包含有以下两个目的: 为数据库操作提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方 ...
- PostgreSQL安装 报there has been an error.Error running
直接用postgresql-11.2-1:https://get.enterprisedb.com/postgresql/postgresql-11.2-1-windows-x64.exe这个版本的安 ...
- JavaScript学习基础2
##JavaScript基本对象 1 .function:函数(方法)对象 * 创建: 1.var fun =new Function(形式参数,方法体): 2.function 方法名(参数){ 方 ...
- windows 安装 kalfka 并快速启动
1.安装Java 环境 https://www.java.com/zh_CN/ 直接下载安装即可 (如果之前有配置过java环境 可以先跳过此步骤,但是如果运行的时候报错就需要把之前的jdk环境变量删 ...
- jstl操作session
1.jstl操作session(添加.删除session中的值)
- 4.27-Postman和JMeter总结及实战描述
一.数据格式 常用的请求方法有8种,但是最常用的有4-5种 1.GET 获取资源 2.POST 添加资源(对服务端已存在的资源也可以做修改和删除操作) 3.PUT 修改资源 4 .DELETE删除资源 ...
- GitStats - 统计Git所有提交记录工具
如果你是研发效能组的一员或者在从事 CI/CD 或 DevOps,除了提供基础设施,指标和数据是也是一个很重要的一环,比如需要分析下某个 Git 仓库代码提交情况: 该仓库的代码谁提交的代码最多 该仓 ...
- go-micro集成链路跟踪的方法和中间件原理
前几天有个同学想了解下如何在go-micro中做链路跟踪,这几天正好看到wrapper这块,wrapper这个东西在某些框架中也称为中间件,里边有个opentracing的插件,正好用来做链路追踪.o ...
- Blazor和Vue对比学习(基础1.3):属性和父子传值
组件除了要解决视图层展示.视图层与逻辑层的数据绑定,还需要解决一个重大问题,就是在组件树中实现数据传递,包括了父到子.子到父.祖到孙,以及任意组织之间.而我们上一章讲到的实现双向绑定的两个指令,Vue ...
- [java并发编程]基于信号量semaphore实现限流器
目录 一.什么是信号量 二.信号量类Semaphore 三.实现限流器 欢迎关注我的博客,更多精品知识合集 一.什么是信号量 "信号量"在编程术语中使用单词semaphore,那什 ...