Batch Norm 与 Layer Norm 比较
一.结论
- Batch Norm一般用于CV领域,而Layer Norm一般用于NLP领域
- Batch Norm需要计算全局平均,而Layer Norm不需要计算全局平均
二.Batch Norm
Batch Norm原理:
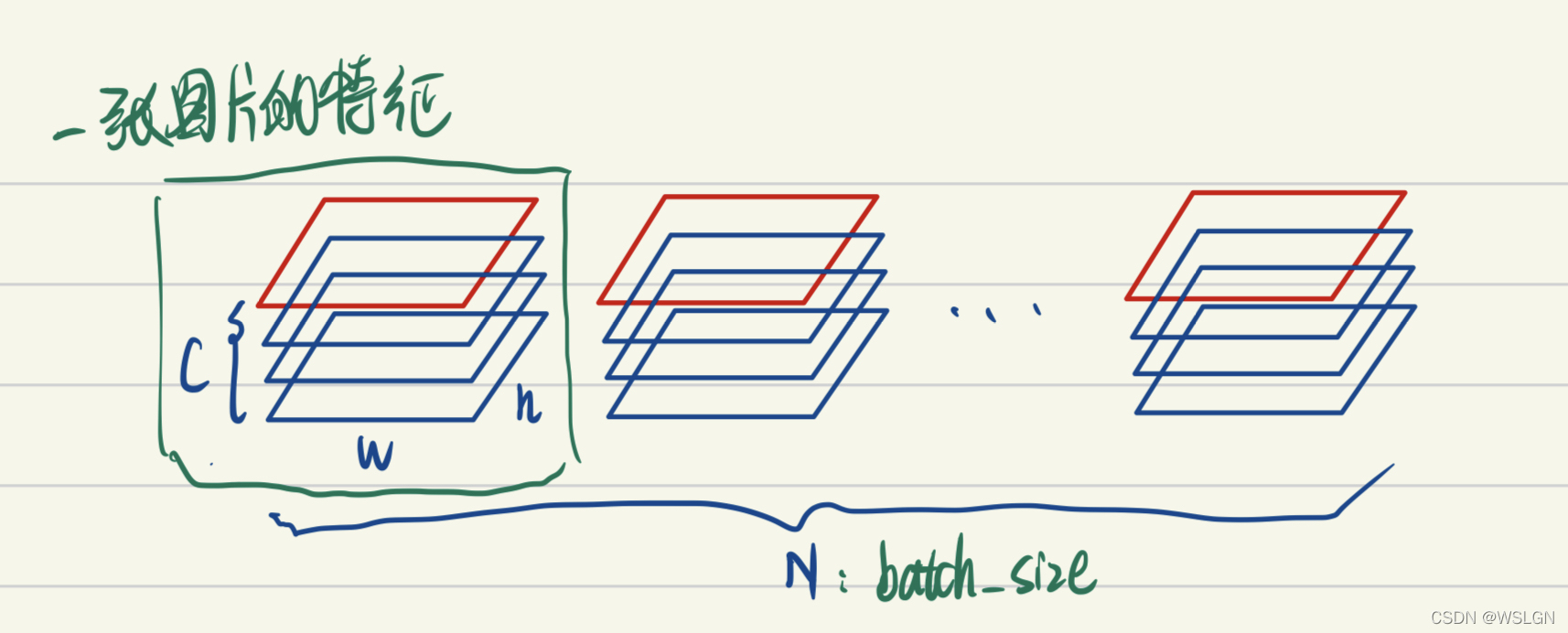
- BatchNorm把一个batch中同一通道的所有特征(如上图红色区域)视为一个分布(有几个通道就有几个分布),并将其标准化。这意味着:
- 不同图片的的同一通道的相对关系是保留的,即不同图片的同一通达的特征是可以比较的
- 同一图片的不同通道的特征则是失去了可比性
用于CV领域的解释:
有一些可解释性方面的观点认为,feature的每个通道都对应一种特征(如低维特征的颜色,纹理,亮度等,高维特征的人眼,鸟嘴特征等)。BatchNorm后不同图片的同一通道的特征是可比较的,或者说A图片的纹理特征和B图片的纹理特征是可比较的;而同一图片的不同特征则是失去了可比性,或者说A图片的纹理特征和亮度特征不可比较。这其实是很好理解的,视觉的特征是比较客观的,一张图片是否有人跟一张图片是否有狗这两种特征是独立,即同一图片的不同特征是不需要可比性;而人这种特征模式的定义其实是网络通过比较很多有人的图片,没人的图片得出的,因此不同图片的同一特征需要具有可比性。
三.Layer Norm
- Layer Norm原理:
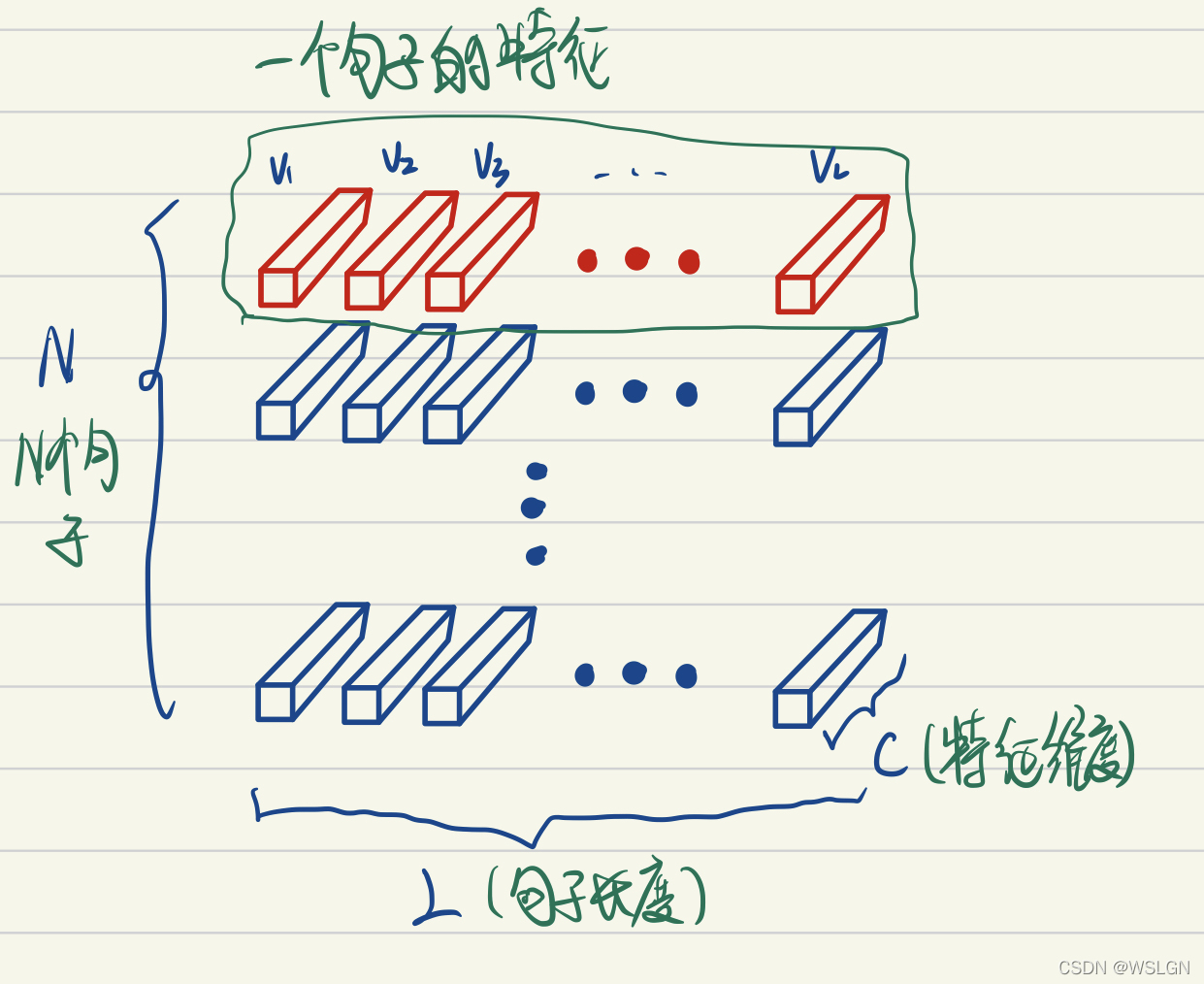
如上图LayerNorm把一个样本的所有词义向量(如上图红色部分)视为一个分布(有几个句子就有几个分布),并将其标准化。这意味着:- 同一句子中词义向量(上图中的V1, V2, …, VL)的相对大小是保留的,或者也可以说LayerNorm不改变词义向量的方向,只改变它的模。
- 不同句子的词义向量则是失去了可比性。
- 用于NLP领域解释:
考虑两个句子,“教练,我想打篮球!” 和 “老板,我要一打包子。”。通过比较两个句子中 “打” 的词义我们可以发现,词义并非客观存在的,而是由上下文的语义决定的。因此进行标准化时不应该破坏同一句子中不同词义向量的可比性,而LayerNorm是满足这一点的,BatchNorm则是不满足这一点的。且不同句子的词义特征也不应具有可比性,LayerNorm也是能够把不同句子间的可比性消除。 - 使用方法:
四.关于计算全局平均的区别
- batch norm在测试的阶段,有可能一个一个样本进行预测,此时没有batch的概念,所以需要用训练的时候的全局平均
- layer norm在训练和测试都不需要计算全局平均
Batch Norm 与 Layer Norm 比较的更多相关文章
- Batch Norm、Layer Norm、Weight Norm与SELU
加速网络收敛——BN.LN.WN与selu 自Batch Norm出现之后,Layer Norm和Weight Norm作为Batch Norm的变体相继出现.最近又出来一个很”简单”的激活函数Sel ...
- bn两个参数的计算以及layer norm、instance norm、group norm
bn一般就在conv之后并且后面再接relu 1.如果输入feature map channel是6,bn的gamma beta个数是多少个? 6个. 2.bn的缺点: BN会受到batchsize大 ...
- Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization、Switchable Normalization比较
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更 ...
- Batch Normalization和Layer Normalization
Batch Normalization:对一个mini batch的样本,经过一个nueron(或filter)后生成的feature map中的所有point进行归一化.(纵向归一化) Layer ...
- NLP学习(5)----attention/ self-attention/ seq2seq/ transformer
目录: 1. 前提 2. attention (1)为什么使用attention (2)attention的定义以及四种相似度计算方式 (3)attention类型(scaled dot-produc ...
- 部分NLP工程师面试题总结
面试题 https://www.cnblogs.com/CheeseZH/p/11927577.html 其他 大数据相关面试题 https://www.cnblogs.com/CheeseZH/p/ ...
- Self-Attention 和 Transformer
1.Self-Attention 之前的RNN输入是难以并行化的,我们下一个输入可能依赖前一个输出,只有知道了前面的输出才能计算后面的输出. 于是提出了 self-attention ,但是这时候 $ ...
- Norm比较
目录 Introduction BN LN IN GN SN Conclusion Introduction 输入图像shape记为[N, C, H, W] Batch Norm是在batch上,对N ...
- norm函数的作用,matlab
格式:n=norm(A,p)功能:norm函数可计算几种不同类型的返回A中最大一列和,即max(sum(abs(A))) 2 返回A的最大奇异值,和n=norm(A)用法一样 inf 返回A中最大一行 ...
随机推荐
- Linux命令格式、终端类型和获取帮助的方法
Linux用户类型 Root用户:超级管理员,权限很大 普通用户:权限有限 终端 terminal 终端类型 物理终端:鼠标.键盘.显示器 虚拟终端:软件模拟出来的终端 控制台终端: /dev/con ...
- HTML\Flex tips
相关文档 HTML:https://www.w3school.com.cn/html/index.asp bootstrap-css: https://v3.bootcss.com/css/#form ...
- NC50965 Largest Rectangle in a Histogram
NC50965 Largest Rectangle in a Histogram 题目 题目描述 A histogram is a polygon composed of a sequence of ...
- 抓到 Netty 一个 Bug,顺带来透彻地聊一下 Netty 是如何高效接收网络连接的
本系列Netty源码解析文章基于 4.1.56.Final版本 对于一个高性能网络通讯框架来说,最最重要也是最核心的工作就是如何高效的接收客户端连接,这就好比我们开了一个饭店,那么迎接客人就是饭店最重 ...
- java--方法/debug
一.方法的定义 1.什么是方法 方法是将具体独立功能的代码块组织称为一个整体,使其具有特殊功能的代码集 注意: 方法必须先创建后使用,该过程为方法定义: 方法创建后并不是直接运行的,需要手动十一后执行 ...
- springmvc源码笔记-HandlerMethodReturnValueHandler
返回值解析器 用于对controller的返回值进行二次处理 结构 // 返回值解析器 public interface HandlerMethodReturnValueHandler { // 判断 ...
- gitlab+jenkins自动构建jar包并发布
一.背景介绍: 公司软件都是java开发的,一般都会将java代码打包成jar包发布:为了减轻运维部署的工作量,合理偷懒,就需要自动化流程一条龙服务:开发将代码提交到gitlab--->jenk ...
- 第一天python3 封装和解构
封装 将多个值使用逗号分割,组合在一起:本质上,返回一个元组,只是省略了小括号:python特有语法,被很多语言学习和借鉴;比如javascript:t1=(1,2) 定义为元组:t2=1,2 将1和 ...
- 在less里面使用js函数
.colorPaletteMixin() { @functions: ~`(function() { this.colorPalette = function() { return '123px'; ...
- Nginx 浏览器缓存配置指令
# 浏览器缓存 # 当浏览器第一次访问服务器资源的时候,服务器返回到浏览器后,浏览器进行缓存 # 缓存的大概内容有: # 1.缓存过期的日期和时间 # 2.设置和缓存相关的配置信息 # 3.请求资源最 ...