安装Hadoop系列 — 新建MapReduce项目
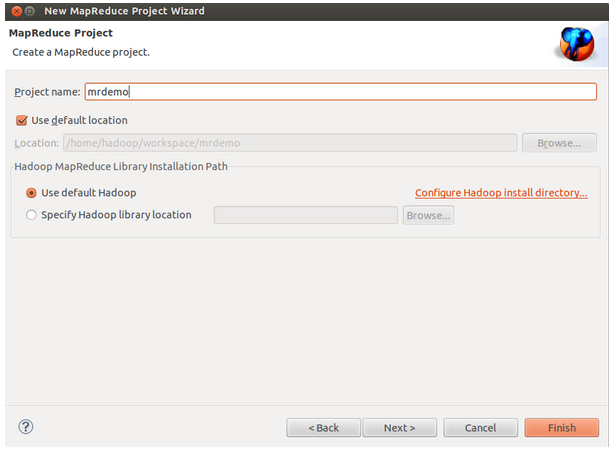
1、新建MR工程

依次点击 File → New → Ohter… 选择Mapper,自动继承Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>



package com.mrdemo; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000");
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hello hadoop
jobtracker
maptracker
reducetracker
task
namenode
datanode
block
beautiful world
hadoop:
HDFS
MapReduce
hdfs://localhost:9000/user/yyq/output01
Run As → Run Configurations… ,在Arguments中配置运行参数,例如程序的输入参数:

Run As -> Run on Hadoop ,执行完成后可以看到如下信息:
安装Hadoop系列 — 新建MapReduce项目的更多相关文章
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 安装Hadoop系列 — 导入Hadoop源码项目
将Hadoop源码导入Eclipse有个最大好处就是通过 "ctrl + shift + r" 可以快速打开Hadoop源码文件. 第一步:在Eclipse新建一个Java项目,h ...
- 安装Hadoop系列 — 安装Hadoop
安装步骤如下: 1)下载hadoop:hadoop-1.0.3 http://archive.apache.org/dist/hadoop/core/hadoop-1.0.3/ 2)解压文 ...
- 安装Hadoop系列 — 安装JDK-8u5
安装步骤如下: 1)下载 JDK 8 从http://www.oracle.com/technetwork/java/javasebusiness/downloads/ 选择下载JDK的最新版本 JD ...
- 安装Hadoop系列 — eclipse plugin插件编译安装配置
[一].环境参数 eclipse-java-kepler-SR2-linux-gtk-x86_64.tar.gz //现在改为eclipse-jee-kepler-SR2-linux-gtk-x86_ ...
- 新建MapReduce项目
添加各种jar包 /usr/local/hadoop/share/hadoop/.. 这几个文件夹下的jar包以及它们子目录lib下的所有jar包 将/usr/local/hadoop/etc/had ...
- 安装Hadoop系列 — 安装Eclipse
1.下载 Eclipse从 http://www.eclipse.org/downloads/index-developer.php下载合适版本,如:Eclipse IDE for C/C++ Dev ...
- 安装Hadoop系列 — 安装SSH免密码登录
配置ssh免密码登录 1) 验证是否安装ssh:ssh -version显示如下的话则成功安装了OpenSSH_6.2p2 Ubuntu-6ubuntu0.1, OpenSSL 1.0.1e 11 ...
随机推荐
- Shell 循环读取文件
使用Shell将Windows环境下的文件拷贝到Linux下面的用法. 在linux下,将dos文件格式转换成linux文件格式的用法,vi打开,然后转到命令格式,执行,然后保存,就可以转换成linu ...
- Ng机器学习笔记-1-一元线性回归
一:回归模型介绍 从理论上讲,回归模型即用已知的数据变量来预测另外一个数据变量,已知的数据属性称为输入或者已有特征,想要预测的数据称为输出或者目标变量. 下图是一个例子: 图中是某地区的面积大小与房价 ...
- echarts.js(图表插件)2.0版会导致 ZeroClipboard.js(复制插件)失效,3.0版未知。
解决方法:ZeroClipboard.js先于echarts.js加载.
- asp.net get server control id from javascript
var WhateverValue = document.getElementById('<%= saveValue.ClientID %>').value
- 使用FileResult导出txtl数据文件
public FileResult ExportMobileNoTxt(SearchClientModel model){ var sbTxt = new StringBuilder(); ; i & ...
- GHOST中DISK TO DISK 和DISK FROM to image的区别
Ghost的Disk菜单下的子菜单项可以实现硬盘到硬盘的直接对拷(Disk-To Disk)、硬盘到镜像文件(Disk-To Image)、从镜像文件还原硬盘内容(Disk-From Image)。 ...
- 关于分区技术的索引 index
关于分区技术---索引 Index 一. 分区索引分类: 本地前缀分区索引(local prefixedpartitioned index) 全局分区索引(global partitionedin ...
- 编译andriod源码出错:java.lang.UnsupportedClassVersionError: com/google/doclava/Doclava : Unsupported
问题:java.lang.UnsupportedClassVersionError: com/google/doclava/Doclava : Unsupported update-java-alte ...
- Nhibernate 一对一关系映射(主键映射)
参考:点击这里 妈的,搞了一天了,终于可以了,现在总结下,以防下次再出现这样痛苦的问题了,有两个表:user(用户)和Blog(设置表),它们之间的关系正如我所说的是一对一的关系.现在我们来映射这两个 ...
- java当中的定时器的4种使用方式
import java.util.Calendar;import java.util.Date;import java.util.Timer;import java.util.TimerTask; p ...