Mysql的热备份[转载]
学一点 mysql 双机异地热备份----快速理解mysql主从,主主备份原理及实践
双机热备的概念简单说一下,就是要保持两个数据库的状态自动同步。对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致。 这样做的好处多。 1. 可以做灾备,其中一个坏了可以切换到另一个。 2. 可以做负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。 对于异地热备,尤其适合灾备。废话不多说了。我们直接进入主题。 我们会主要介绍两部分内容:
一, mysql 备份工作原理
二, 备份实战
我们开始。
我使用的是mysql 5.5.34,
一, mysql 备份工作原理
简单的说就是把 一个服务器上执行过的sql语句在别的服务器上也重复执行一遍, 这样只要两个数据库的初态是一样的,那么它们就能一直同步。
当然这种复制和重复都是mysql自动实现的,我们只需要配置即可。
我们进一步详细介绍原理的细节, 这有一张图:
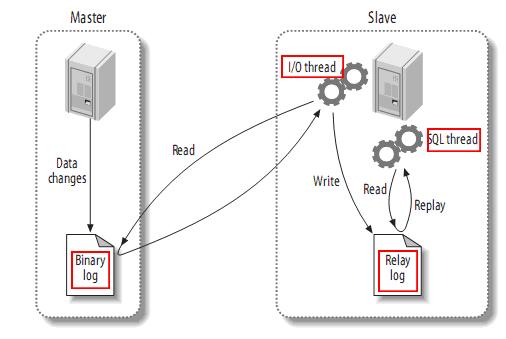
上图中有两个服务器, 演示了从一个主服务器(master) 把数据同步到从服务器(slave)的过程。
这是一个主-从复制的例子。 主-主互相复制只是把上面的例子反过来再做一遍。 所以我们以这个例子介绍原理。
对于一个mysql服务器, 一般有两个线程来负责复制和被复制。当开启复制之后。
1. 作为主服务器Master, 会把自己的每一次改动都记录到 二进制日志 Binarylog 中。 (从服务器会负责来读取这个log, 然后在自己那里再执行一遍。)
2. 作为从服务器Slave, 会用master上的账号登陆到 master上, 读取master的Binarylog, 写入到自己的中继日志 Relaylog, 然后自己的sql线程会负责读取这个中继日志,并执行一遍。 到这里主服务器上的更改就同步到从服务器上了。
在mysql上可以查看当前服务器的主,从状态。 其实就是当前服务器的 Binary(作为主服务器角色)状态和位置。 以及其RelayLog(作为从服务器)的复制进度。
例如我们在主服务器上查看主状态:
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000014
Position: 107
Binlog_Do_DB:
Binlog_Ignore_DB: mysql,information_schema,performance_schema,amh
1 row in set (0.00 sec)
稍微解释一下这几行的意思:
1. 第一行表明 当前正在记录的 binarylog文件名是: mysql-bin.000014.
我们可以在mysql数据目录下,找到这个文件:
2. 第二行, 107. 表示当前的文件偏移量, 就是写入在mysql-bin.000014 文件的记录位置。
这两点就构成了 主服务器的状态。 配置从服务器的时候,需要用到这两个值。 告诉从服务器从哪读取主服务器的数据。 (从服务器会登录之后,找到这个日志文件,并从这个偏移量之后开始复制。)
3. 第三行,和第四行,表示需要记录的数据库和需要忽略的数据库。 只有需要记录的数据库,其变化才会被写入到mysql-bin.000014日志文件中。 后面会再次介绍这两个参数。
我们还可以在从服务器上,查看从服务器的复制状态。
1: mysql> show slave status\G
2: *************************** 1. row ***************************
3: Slave_IO_State: Waiting for master to send event
4: Master_Host: 198.**.***.***
5: Master_User: r*******
6: Master_Port: 3306
7: Connect_Retry: 60
8: Master_Log_File: mysql-bin.000014
9: Read_Master_Log_Pos: 107
10: Relay_Log_File: mysqld-relay-bin.000013
11: Relay_Log_Pos: 253
12: Relay_Master_Log_File: mysql-bin.000014
13: Slave_IO_Running: Yes
14: Slave_SQL_Running: Yes
15: Replicate_Do_DB:
16: Replicate_Ignore_DB: mysql,information_schema,amh,performance_schema
17: Replicate_Do_Table:
18: Replicate_Ignore_Table:
19: Replicate_Wild_Do_Table:
20: Replicate_Wild_Ignore_Table:
21: Last_Errno: 0
22: Last_Error:
23: Skip_Counter: 0
24: Exec_Master_Log_Pos: 107
25: Relay_Log_Space: 556
26: Until_Condition: None
27: Until_Log_File:
28: Until_Log_Pos: 0
29: Master_SSL_Allowed: No
我们还是来重点解释途中的红圈的部分:
1. Master_host 指的是 主服务器的地址。
2. Master_user 指的是主服务器上用来复制的用户。 从服务器会用此账号来登录主服务。进行复制。
3. Master_log_file 就是前面提到的, 主服务器上的日志文件名.
4. Read_Master_log_pos 就是前面提到的主服务器的日志记录位置, 从服务器根据这两个条件来选择复制的文件和位置。
5. Slave_IO_Running: 指的就是从服务器上负责读取主服务器的线程工作状态。 从服务器用这个专门的线程链接到主服务器上,并把日志拷贝回来。
6. Slave_SQL_Running: 指的就是专门执行sql的线程。 它负责把复制回来的Relaylog执行到自己的数据库中。 这两个参数必须都为Yes 才表明复制在正常工作。
其他的参数之后再介绍。
二, mysql 双机热备实战
了解了上面的原理之后, 我们来实战。 这里有两个重点, 要想同步数据库状态, 需要相同的初态,然后配置同步才有意义。 当然你可以不要初态,这是你的自由。 我们这里从头开始配置一遍。
我们先以A服务器为起点, 配置它的数据库同步到B。 这就是主-从复制了。 之后再反过来做一次,就可以互相备份了。
1, 第一步,
在A上面创建专门用于备份的 用户:
grant replication slave on *.* to 'repl_user'@'192.***.***.***' identified by 'hj34$%&mnkb';
上面把ip地址换成B机器的ip地址。 只允许B登录。安全。
用户名为: repl_user
密码为: hj34$********nkb
这个等会在B上面要用。
2. 开启主服务器的 binarylog。
很多服务器是默认开启的,我们这里检查一下:
打开 /etc/my.cnf
我来解释一下红框中的配置:
前面三行, 你可能已经有了。
binlog-do-db 用来表示,只把哪些数据库的改动记录到binary日志中。 可以写上关注hello数据库。 但是我把它注释掉了。 只是展示一下。 可以写多行,表示关注多个数据库。
binlog-ignore-db 表示,需要忽略哪些数据库。我这里忽略了其他的4个数据库。
后面两个用于在 双主(多主循环)互相备份。 因为每台数据库服务器都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突。 解决这个问题的办法就是让每个数据库的自增主键不连续。 上图说是, 我假设需要将来可能需要10台服务器做备份, 所以auto-increment-increment 设为10. 而 auto-increment-offset=1 表示这台服务器的序号。 从1开始, 不超过auto-increment-increment。
这样做之后, 我在这台服务器上插入的第一个id就是 1, 第二行的id就是 11了, 而不是2.
(同理,在第二台服务器上插入的第一个id就是2, 第二行就是12, 这个后面再介绍) 这样就不会出现主键冲突了。 后面我们会演示这个id的效果。
3. 获取主服务器状态, 和同步初态。
假设我现在有这些数据库在A上面。
如果你是全新安装的, 那么不需要同步初态,直接跳过这一步,到后面直接查看主服务器状态。
这里我们假设有一个 hello 数据库作为初态。
先锁定 hello数据库:
FLUSH TABLES WITH READ LOCK;
然后导出数据:
我这里只需要导出hello数据库, 如果你有多个数据库作为初态的话, 需要导出所有这些数据库:
然后查看A服务器的binary日志位置:
记住这个文件名和 位置, 等会在从服务器上会用到。
主服务器已经做完了, 可以解除锁定了:
4. 设置从服务器 B 需要复制的数据库
打开从服务器 B 的 /etc/my.cnf 文件:
解释一下上面的内容。
server-id 必须保证每个服务器不一样。 这可能和循环同步有关。 防止进入死循环。
replicate-do-db 可以指定需要复制的数据库, 我这里注掉了。 演示一下。
replicate-ignore-db 复制时需要排除的数据库, 我使用了,这个。 除开系统的几个数据库之外,所有的数据库都复制。
relay_log 中继日志的名字。 前面说到了, 复制线程需要先把远程的变化拷贝到这个中继日志中, 在执行。
log-slave-updates 意思是,中继日志执行之后,这些变化是否需要计入自己的binarylog。 当你的B服务器需要作为另外一个服务器的主服务器的时候需要打开。 就是双主互相备份,或者多主循环备份。 我们这里需要, 所以打开。
保存, 重启mysql。
5. 导入初态, 开始同步。
把刚才从A服务器上导出的 hello.sql 导入到 B的hello数据库中, 如果B现在没有hello数据库,请先创建一个, 然后再导入:
创建数据库:
mysql> create database hello default charset utf8;
把hello.sql 上传到B上, 然后导入:
如果你刚才导出了多个数据库, 需要把他们都一一上传导入。
开启同步, 在B服务器上执行:
CHANGE MASTER TO
MASTER_HOST='192.***.***.***',
MASTER_USER='repl_user',
MASTER_PASSWORD='hj3****',
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=7145;
上面几个参数我就不解释了。 前面说过了。
重启mysql, 然后查看slave线程开启了没:
注意图中的红框, 两个都是Yes, 说明开启成功。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
如果其中一个是No, 那就说明不成功。需要查看mysql的错误日志。 我在第一次做的时候就遇到这个问题。有时候密码填错了, 有时候防火墙的3306没有打开。ip地址不对,等等。 都会导致失败。
我们看错误日志: mysql的错误日志一般在:
文件名应该是你的机器名, 我这里叫做host1.err 你换成你自己的。
到这里主-从复制已经打开了。 我们先来实验一下。
我们在A的数据库里面去 添加数据:
我在A的 hello数据库的test表中 连续插入了3条数据, 注意看他们的自增长id, 分别是1,11,21. 知道这是为什么吗。 前面已经说过了,不懂再回去看。
我们去看一下B数据库有没有这三条数据:
打开B的数据库:
发现已经在这了。 这里效果不直观。
此时不要在B中修改数据。 我们接着配置从B到A的复制。 如果你只需要主从复制的话, 到这里就结束了。后面可以不看了。 所有A中的修改都能自动同步到B, 但是对B的修改却不能同步到A。 因为是单向的。 如果需要双向同步的话,需要再做一次从B到A的复制。
基本跟上面一样:我们简单一点介绍:
1. 在B中创建用户;
2. 打开 /etc/my.cnf , 开启B的binarylog:
注意红框中所新添加的部分。
3. 我们不需要导出B的初态了,因为它刚刚才从A导过来。 直接记住它的master日志状态:
记住这两个数值,等会在A上面要用。
B服务器就设置完了。
4. 登录到A 服务器。 开启中继:
注意框中心添加的部分, 不解释了。
5. 启动同步:
上面的ip地址是B的ip地址, 因为A把B当做master了。 不解释了。
然后重启mysql服务。
然后查看,slave状态是否正常:
图中出现了两个No。
Slave_IO_Running: No
Slave_SQL_Running: No
说明slave没有成功, 即,从B到A的同步没有成功。 我们去查看mysql错误日志,前面说过位置:
找到 机器名.err 文件,打开看看:
看图中的error信息。 说找不到中继日志文件。
这是因为我们在配置A的中继文件时改了中继文件名,但是mysql没有同步。解决办法很简单。
先停掉mysql服务。 找到这三个文件,把他们删掉。 一定要先停掉mysql服务。不然还是不成功。你需要重启一下机器了。 或者手动kill mysqld。
好了, 启动mysql之后。 我们在来检查一下slave状态:
注意图中两个大大的Yes。 哈哈。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
证明从B到A的复制也成功了。
此时我们去B服务器中插入几条数据试试:
我在B中插入了两条数据。 注意看他们的id。 不解释。
然后我们,登录去A中看看,A数据库变了没。
可以看到已经自动同步到A了。
至此, AB双主互相热备就介绍完了。
原理其实很简单,是不是。
理解了这个原理, 多机循环互备就简单了。这里就不再展开了。
花了一天时间写这个博客,大家要顶啊。
欢迎大家访问我的独立博客:http://blog.byneil.com 多多交流。
参考:
1. mysql-keepalived-实现双主热备读写分离
2. MySQL数据同步【双主热备】http://www.cnblogs.com/zhongweiv/archive/2013/02/01/mysql_replication_circular.html
3. Mysql双机热备实现
http://yunnick.iteye.com/blog/1845301
4. 高性能Mysql主从架构的复制原理及配置详解http://blog.csdn.net/hguisu/article/details/7325124
Mysql的热备份[转载]的更多相关文章
- Java基础 之软引用、弱引用、虚引用 ·[转载]
Java基础 之软引用.弱引用.虚引用 ·[转载] 2011-11-24 14:43:41 Java基础 之软引用.弱引用.虚引用 浏览(509)|评论(1) 交流分类:Java|笔记分类: Ja ...
- [转载]iOS9 使用CoreLocation
在iOS8之前,只要 #import <CoreLocation/CoreLocation.h>引入CoreLocation.framework. @property (nonatomic ...
- [转载]—— Android JNI知识点
Java Native Interface (JNI)标准是java平台的一部分,它允许Java代码和其他语言写的代码进行交互.JNI 是本地编程接口,它使得在 Java 虚拟机 (VM) 内部运行的 ...
- GJM :用JIRA管理你的项目(二)JIRA语言包支持及插件支持 [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- [转载]强烈推荐学习的blog
膜拜大牛 原文出处:http://hedengcheng.com/?p=676 ACM Queue (Architecting Tomorrow’s Computing) 网址:http://queu ...
- Ubuntu14.04安装中文输入法以及解决Gedit中文乱码问题[转载]
转载自:http://www.cnblogs.com/zhcncn/p/4032321.html 写在前面:解决gedit 在txt文件格式出现乱码的问题,在我自己的操作中是需要把系统设置成中文显示环 ...
- [转载]深入理解Batch Normalization批标准化
文章转载自:http://www.cnblogs.com/guoyaohua/p/8724433.html Batch Normalization作为最近一年来DL的重要成果,已经广泛被证明其有效性和 ...
- Mac上的抓包工具Charles[转载]
今天就来看一下Mac上如何进行抓包,之前有一篇文章介绍了使用Fidder进行抓包 http://blog.csdn.net/jiangwei0910410003/article/details/198 ...
- [转载]kd tree
[本文转自]http://www.cnblogs.com/eyeszjwang/articles/2429382.html k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据 ...
随机推荐
- TOGAF架构内容框架之构建块(Building Blocks)
TOGAF架构内容框架之构建块(Building Blocks) 之前忙于搬家移居,无暇顾及博客,今天终于得闲继续我的“政治课”了,希望之后至少能够补完TOGAF方面的内容.从前面文章可以看出,笔者并 ...
- 该死的类型转换For input string: "[Ljava.lang.String;@1352dda"
今天又遇见了这个该死的问题,还是记下来备忘. 从map里取值的时候,将OBJECT对象 先转换成String 然后转换成integer报错 java.lang.NumberFormatExceptio ...
- 在WebStorm中集成Karma+jasmine进行前端单元测试
在WebStorm中集成Karma+jasmine进行前端单元测试 前言 好久没有写博了,主要还是太懒=.=,有点时间都去带娃.看书了,今天给大家分享一个原创的小东西,如果大家对TDD或者BDD有兴趣 ...
- Guacamole 介绍
Guacamole 介绍以及架构 目前在从事一些虚拟化解决方案方面的工作,最近项目有需求,希望能在浏览器上远程操作虚拟机. 此时发现了Guacamole,一个提供远程桌面的解决方案的开源项目,通过 ...
- ThinkPHP中连接mysql数据库的四种实用和通用的连接方法
ThinkPHP内置了抽象数据库访问层,把不同的数据库操作封装起来,我们只需要使用公共的Db类进行操作,而无需针对不同的数据库写不同的代码和底层实现,Db类会自动调用相应的数据库适配器来处理.目前的数 ...
- 在gem5的full system下运行 x86编译的测试程序 running gem5 on ubuntu in full system mode in x86
背景 上篇博客写了如何在gem5的full system模式运行alpha的指令编译的程序,这篇博客讲述如何在gem5的full system模式运行x86指令集编译的程序,这两种方式非常类似. 首先 ...
- hadoop部署错误
hadoop的单机部署很简单也不容易出错,但是对生产环境的价值和意义不大,但是可以快速用于开发. 部署hadoop的错误原因不少,并且很奇怪. 比如,用户名不同,造成客户端和服务器通讯产生认证失败的错 ...
- Windows 8.1 Preview的新功能和新API
http://msdn.microsoft.com/en-us/library/windows/apps/bg182410 App打包 新的App程序包将使App的提交更简单.资源包可以让你提供附加的 ...
- python基础语言以及if/while语句结构
接下来学会了变量:用简单的变量来代替复杂的字符串 变量首字母不能是数字或者特殊符号~!@#¥等. 字符集的发展: ASCII 255个 1个占1bytes------>1980年 GB2312 ...
- asp.net mvc ActionResult
定义在Controller中的Action方法大都返回一个ActionResult对象.ActionResult是对Action执行结果的封装,用于最终对请求进行响应.ASP.NET MVC提供了一系 ...