Oracle用法、函数备忘记录
Listagg
select * from emp
select LISTAGG(ename,'-') within group (order by deptno desc) from emp;

可以看到功能类似wm_concat,可以自定义连接符,区别:
LISTAGG : 11g2才提供的函数,不支持distinct,拼接长度不能大于4000,函数返回为varchar2类型,最大长度为4000.
和wm_concat相比,listagg可以执行排序。例如
select deptno, listagg(ename,';')
within
group(order
by ename) enames from emp group
by deptno;
类似的语法还有:
--计算数值1000在记录集中的排序值。
select rank(1000) within group(order by sal),dense_rank(1000) within group(order by sal) from emp;
cume_dist()、PERCENT_RANK
cume_dist:计算结果为相对位置/总行数。返回值(0,1]。
percent_rank:计算方法为 (相对位置-1)/(总行数-1),
select cume_dist(20, 4000) within group(order by deptno, sal) cume_dist
from emp;
with table as
SQL Code
with temp as(
select
500 population,
'China' nation ,'Guangzhou' city from dual union
all
select
1500 population,
'China' nation ,'Shanghai' city from dual union
all
select
500 population,
'China' nation ,'Beijing' city from dual union
all
select
1000 population,
'USA' nation ,'New York' city from dual union
all
select
500 population,
'USA' nation ,'Bostom' city from dual union
all
select
500 population,
'Japan' nation ,'Tokyo' city from dual
)
select population,
nation,
city,
listagg(city,',')
within
GROUP
(order
by city)
over
(partition
by nation)
rank
from temp
With table as 类似创建一个临时表,只可以查询一次,之后就被销毁,同时可以创建多个临时table,比如:
with sql1 as
(select to_char(a) s_name from test_tempa),
sql2 as
(select to_char(b) s_name from test_tempb where
not
exists
(select s_name from sql1 where
rownum
=
1))
select
*
from sql1 union
all
select
*
from sql2
pivot unpivot
行列转换,见
Minus
SQL中有一个MINUS关键字,它运用在两个SQL语句上,它先找出第一条SQL语句所产生的结果,然后看这些结果有没有在第二个SQL语句的结果中。如果有的话,那这一笔记录就被去除,而不会在最后的结果中出现。如果第二个SQL语句所产生的结果并没有存在于第一个SQL语句所产生的结果内,那这笔资料就被抛弃,其语法如下:
[SQL Segment 1]
MINUS
[SQL Segment 2]
--------------------------------------------
--创建表1
create
table test1
(
name
varchar(10),
sex varchar(10),
);
insert
into test1 values('test','female');
insert
into test1 values('test1','female');
insert
into test1 values('test1','female');
insert
into test1 values('test11','female');
insert
into test1 values('test111','female');
--创建表2
create
table test2
(
name
varchar(10),
sex varchar(10),
);
insert
into test1 values('test','female');
insert
into test1 values('test2','female');
insert
into test1 values('test2','female');
insert
into test1 values('test22','female');
insert
into test1 values('test222','female');
-------------------------------------------
select
*
from test1 minus
select
*
from test2;
结果:
NAME SEX
---------- ----------
test1 female
test11 female
test111 female
-----------------------------------------------------------
select
*
from test2 minus
select
*
from test1;
结果:
NAME SEX
---------- ----------
test2 female
test22 female
test222 female
结论:Minus返回的总是左边表中的数据,它返回的是差集。注意:minus有剃重作用
万笔记录,charge_detail共17万笔记录
性能比较:
SELECT order_id FROM made_order
MINUS
SELECT order_id FROM charge_detail
1.14 sec
select a.order_id
from made_order a
where
not
exists
(select order_id from charge_detail where order_id = a.order_id)
18.19 sec
select order_id
from made_order
where order_id not
in
(select order_id from charge_detail)
20.05 sec
nullslast(first)
排序,遇空排在前(后)
select
*
from emp order
by comm desc
nulls
last

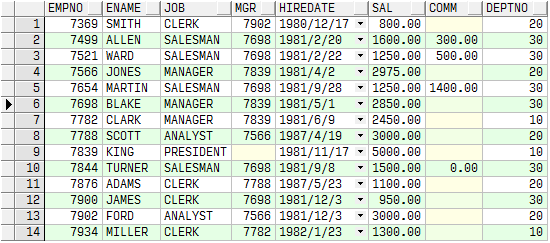
Over
select ename,max(sal)
over()
from emp;
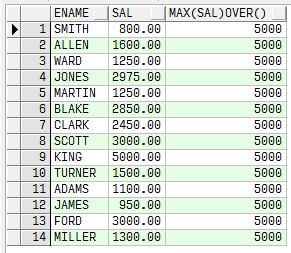
rownum和row_number()
row_number() over (partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。 与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣rownum然后再进行排序,而row_number()在包含排序从句后是先排序再计算行号码。
select row_number()
over
(order
by ename) rn,ename from emp ;

select
rownum,ename from emp order
by ename;
Partition by
select row_number()
over(partition
by job order
by sal) row_number,
rank()
over(partition
by job order
by sal)
rank,
dense_rank()
over(partition
by job order
by sal) dense_rank,
count(1)
over(partition
by job order
by sal)
count,
max(empno)
over(partition
by job order
by sal)
max,
sum(sal)
over(partition
by job order
by sal)
sum,
lag(ename)
over(partition
by job order
by sal)
lag,
lead(ename)
over(partition
by job order
by sal)
lead,
sum(sal)
over(order
by sal range
between
unbounded
preceding
and
current
row) range_unbound_sum,
sum(sal)
over(order
by sal rows
between
unbounded
preceding
and
current
row) rows_unbound_sum,
sum(sal)
over(order
by sal range
between
1
preceding
and
2
following) range_sum,
sum(sal)
over(order
by sal rows
between
1
preceding
and
2
following) rows_sum,
sal, mgr, job, empno, ename
from emp

注意: rank、dense_rank的区别,count的变化。
Dump
DUMP(expr[,return_fmt[,start_position][,length]])
基本参数时4个,最少可以填的参数是0个。当完全没有参数时,直接返回null。另外3个参数也都有各自的默认值:
expr:这个参数是要进行分析的表达式(数字或字符串等,可以是各个类型的值)
return_fmt:指返回参数的格式,有5种用法:
1)8:以8进制返回结果的值
2)10:以10进制返回结果的值(默认)
3)16:以16进制返回结果的值
4)17:以单字符的形式返回结果的值
5)1000:以上4种加上1000,表示在返回值中加上当前字符集
start_position:开始进行返回的字符位置
length:需要返回的字符长度
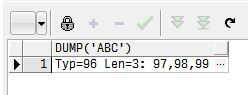
select
dump('abc')
from dual;
Type
typ表示当前的expr值的类型。如:2表示NUMBER,96表示CHAR。
CODE TYP
----- ------------------------------
1 VARCHAR2
2 NUMBER
8 LONG
12 DATE
23 RAW
24 LONG RAW
69 ROWID
96 CHAR
112 CLOB
113 BLOB
114 BFILE
180 TIMESTAMP
181 TIMESTAMP WITH TIMEZONE
182 INTERVAL YEAR TO MONTH
183 INTERVAL DAY TO SECOND
208 UROWID
231 TIMESTAMP WITH LOCAL TIMEZONE
len
len表示该值所占用的字节数。
对于汉字,ZHS16GBK编码一个汉字需要2个字节,UTF8需要3个字节。
SQL> select dump('多多',1010) from dual;
DUMP('多多',1010)
-------------------------------------------------------
Typ=96 Len=6 CharacterSet=UTF8: 229,164,154,229,164,154
SQL> select dump('多多',1010) from dual;
DUMP('多多',1010)
---------------------------------------------------
Typ=96 Len=4 CharacterSet=ZHS16GBK: 182,224,182,224
Value
具体的存储值。返回的数值就是Oracle在自己内部对前面的这个expr值得存储形式。对于非汉字的普通字符串,可以理解为就是它的ASCII码。
Reverse
oracle 提供一个reverse函数,可以实现将一个对象反向转换.
比如:
SQL> select reverse('123456') from dual;
REVERSE('123456')
-----------------
654321
由于这个函数,是针对数据库内部存储的对象编码进行反转的,
因此,在比如:数字,中文等.因为实现存储的并不是直接编码后的结果,而是经过某种内部转换后实现的,因此,在转换完成后,并不一定是自己想要的结果.示例:
SQL> select reverse(123456) ,reverse('中华人民共和国') from dual;
REVERSE(123456) REVERSE('中华人民共和国')
--------------- -------------------------
-668706000000 ?秃补衩巳?兄
在这个地方,一个整数,一个中文内容,就被转换为其它的内容了.
我们dump看看,就明白oracle是如何reverse了
SQL> select reverse(123456),dump(123456),dump(reverse(123456)) from dual;
REVERSE(123456) DUMP(123456) DUMP(REVERSE(123456))
--------------- ------------------------- -------------------------
-668706000000 Typ=2 Len=4: 195,13,35,57 Typ=2 Len=4: 57,35,13,195
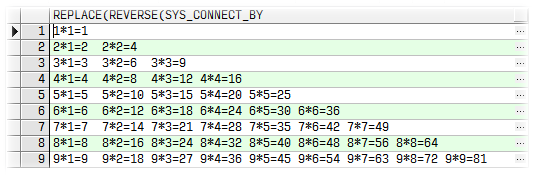
九九乘法表
Oracle相关函数总结:
select
replace(reverse(sys_connect_by_path(reverse(rownum
||
'*'
|| lv ||
'='
||
rpad(rownum
* lv,
2)),
'/ ')),
'/')
from
(select
level lv from dual connect
by
level
<
10)
where lv =
connect
by lv +
1
=
prior lv;
Group by
Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句。如果是ROLLUP(A, B, C)的话,首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。如果是GROUP BY CUBE(A, B, C),则首先会对(A、B、C)进行GROUP BY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行GROUP BY操作。 grouping_id()可以美化效果。
Grouping sets(A,B)表示先对A普通分组,再对B普通分组,然后合并在一起。
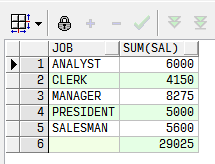
Rollup
汇总数据到行尾。
select job,sum(sal)
from emp group
by
rollup(job)
select deptno,job,sum(sal)
from emp group
by
rollup(deptno,job)

Grouping
select deptno,job,sum(sal),grouping(deptno),grouping(job)
from emp group
by
rollup(deptno,job)
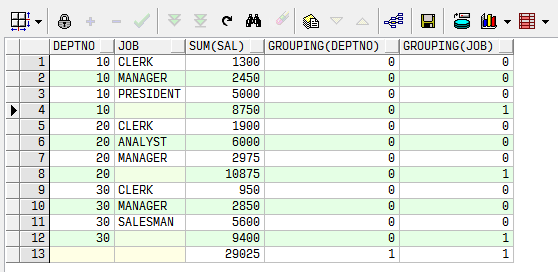
如果显示"1"表示GROUPING函数对应的列(例如JOB字段)是由于ROLLUP函数所产生的空值对应的信息,即对此列进行汇总计算后的结果。
如果显示"0"表示此行对应的这列参未与ROLLUP函数分组汇总活动。
CUBE
select deptno,job,grouping(job),sum(sal)
from emp group
by
cube(deptno,job);

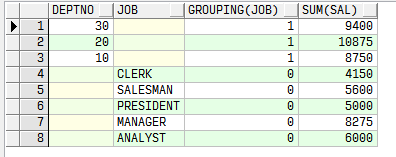
groupingsets
select deptno,job,grouping(job),sum(sal)
from emp group
by
grouping
sets(deptno,job);
select deptno,job,grouping(job),sum(sal)
from emp group
by
grouping
sets((deptno,job),deptno);

Model
select deptno, job,ename, sal
from emp model
return
updated
rows
partition
by(deptno)
dimension
by(job,ename)
measures(sal)
--rules(sal [ 'ANALYST','JAMES'] = 1)
rules(sal [ job in('ANALYST','CLERK'),length(ename)>1] =
1)

详细见:http://blog.csdn.net/huangyunzeng2008/article/details/5664172
Numtoyminterval和numtodsinterval
计算时间间隔的函数。
Numtoyminterval常用的单位有'year','month'
numtodsinterval常用的单位有 ('day','hour','minute','second')
select
sysdate,
sysdate
+
numtoyminterval(3,
'month'),
sysdate
+
numtodsinterval(3,
'second')
as res
from dual;

skip locked
在11gR1中,oracle增加了skip locked子句。此时,如果探测到了记录已经被锁,就不会进入等待队列或者抛出ORA-00054错误,而是跳过该条记录继续执行。
Select owner, table_name from t_test2 where owner='OUTLN'
for
update
skip
locked;
--first、last
select max(ename) keep(dense_rank first order by nvl(sal,0) nulls first) from emp a;
select max(ename) keep(dense_rank first order by nvl(sal,0) nulls first) over(partition by deptno),a.* from emp a;
--first_value、last_value
select first_value(ename) over(order by sal),a.* from emp a where deptno=10;
Oracle用法、函数备忘记录的更多相关文章
- Oracle存储过程学习备忘
之前的项目使用存储过程很少,但在实际的项目中,存储过程的使用是必不可少的. 存储过程是一组为了完成特定功能的SQL 语句 集,经编译后存储在数据库中:存储过程创建后,一次编译在程序中可以多次调用,对安 ...
- sql时间转换函数--备忘
总是忘记 一.语法: CAST (expression AS data_type) 参数说明: expression:任何有效的SQServer表达式. AS:用于分隔两个参数,在AS之前的是要处理的 ...
- Centos6.5安装MySQL5.6备忘记录
Centos6.5安装MySQL5.6 1. 查看系统状态 [root@itzhouq32 tools]# cat /etc/issue CentOS release 6.5 (Final) Kern ...
- linux 备忘记录
杂项记录 Ubuntu 通过/etc/network/interfaces修改IP,重启网络服务貌似也不会生效.可以重启电脑使其生效,或执行: ip addr flush dev ens33 & ...
- oracle下 启动subversion命令 及 oracle相关服务启动备忘
linux shell下 svnserve - d -r + 目录 例如:svnserve -d -r /svn 启动 svn服务. 访问svn://192.168.0.120/kjcg 测试. ...
- Centos6.5安装Redis3.0备忘记录
Centos6.5安装Redis3.0 1. 安装C编译环境 首先需要安装编译Redis的C环境,在命令行执行以下命令: [root@itzhouq32 tools] yum install gcc- ...
- opencv常用函数备忘
//显示图片 IplImage * src = cvLoadImage("xx.JPG"); cvNamedWindow(); cvShowImage("show_ima ...
- 项目中oracle存储过程记录——经常使用语法备忘
项目中oracle存储过程记录--经常使用语法备忘 项目中须要写一个oracle存储过程,需求是收集一个复杂查询的内容(涉及到多张表),然后把符合条件的记录插入到目标表中.当中原表之中的一个的日期字段 ...
- sqlserver -- 学习笔记(一)自定义函数(学习总结,备忘)
SQL Server自定义函数,以前只在书上看过,没有动手去敲一敲,今天刚好接触到,看了几篇博文学习了下.做好备忘很重要!! (@_@)Y Learn from:http://www.cnblogs. ...
随机推荐
- Sublime Text3使用总结
写在前面的话:平时做项目中在用eclipse和vs,但是对于一些小项目,感觉没有必要搞那么大的一个工具使用,比如写个小微商城,搞个小脚本了什么,所以就一直在用Sublime Text,界面清新简洁,没 ...
- 用java开发微信公众号:接收和被动回复普通消息(三)
上篇说完了如何接入微信公众号,本文说一下微信公众号的最基本功能:普通消息的接收和回复.说到普通消息,那么什么是微信公众号所定义的普通消息呢,微信开发者文档中提到的接收的普通消息包括如下几类: 1.文本 ...
- ABP框架 - 日志
文档目录 本节内容: 服务端 获取Logger(记录器) Logger的基类 配置 Abp.Castle.Log4Net 包 客户端 服务端 ABP使用Castle Windsor的日志记录工具,它可 ...
- java遇到 Check $M2_HOME 问题 解决-Dmaven.multiModuleProjectDirectory system property is not set. Check $M2_HOME environment variable and mvn script match.
步骤: 1.添加M2_HOME的环境变量 2.Preference->Java->Installed JREs->Edit 选择一个jdk 3.添加 -Dmaven.multiMod ...
- java自定义注解类
一.前言 今天阅读帆哥代码的时候,看到了之前没有见过的新东西, 比如java自定义注解类,如何获取注解,如何反射内部类,this$0是什么意思? 于是乎,学习并整理了一下. 二.代码示例 import ...
- 打造android偷懒神器———RecyclerView的万能适配器
转载请注明出处谢谢:http://www.cnblogs.com/liushilin/p/5720926.html 很不好意思让大家久等了,本来昨天就应该写这个的,无奈公司昨天任务比较紧,所以没能按时 ...
- 线上bug的解决方案--带来的全新架构设计
缘由 本人从事游戏开发很多年一直都是游戏服务器端开发. 因为个人原因吧,一直在小型公司,或者叫创业型团队工作吧.这样的环境下不得不逼迫我需要什么都会,什么做. 但是自我感觉好像什么都不精通..... ...
- scikit-learn一般实例之六:构建评估器之前进行缺失值填充
本例将会展示对确实值进行填充能比简单的对样例中缺失值进行简单的丢弃能获得更好的结果.填充不一定能提升预测精度,所以请通过交叉验证进行检验.有时删除有缺失值的记录或使用标记符号会更有效. 缺失值可以被替 ...
- Android 5.0源码编译问题
如果是自己通过repo和git直接从google官网上download的源码,请忽略这个问题,但是由于google在国内被限制登录,通过这一种方法不是每个人都能download下来源码,通常的做法就是 ...
- PALIN - The Next Palindrome 对称的数
A positive integer is called a palindrome if its representation in the decimal system is the same wh ...