SQL SERVER分区具体例子详解
在日常工作中,我们会遇到以下的情况,一个表每日数万级的增长,而查询的数据通常是在本月或今年,以前的数据偶尔会用到,但查询和插入的效率越来越慢,用数据库分区会有助于解决这个问题。关于分区的理论知识网上很多我这里就不在累赘,我从一个实际例子出发,看如何将一个已经运行了很长时间的普通表进行分区。
提出问题
需解决问题:有一个数据表数据很大,我们通常的查询是在一个季度中。我们需要将以往年份的数据按不同年份存在文件组里,当年的数据分为4个季度存,如果到了新的一年,将之前4个季度的合并到一年中,新的一年又按4个季度分区。
解决问题
好了我们将一步步的开始解决问题。
建立模拟环境
1.首先建立数据库,和创建表。
新建个数据库,新建测试表。数据文件放在一个好找的文件夹内,方便分区文件一并放在其中。
2.创建模拟数据。
我用C#程序模拟插入了一些数据,时间从2015-9-1号到2017-4-1每天一天数据。此时表的属性如下,文件组Primary,未分区。
建立分区文件

新建5个文件组,对应5个数据库文件,Y2015存放2015年的数据,Q1,Q2,Q3,Q4存放4个季度的数据,这里我们将文件都放在了同一个文件夹,如果条件允许,放在不同的磁盘上会增加读写效率。
建立分区函数
分区函数RANGE有区分LEFT和RIGHT
LEFT是第一个分区小于等于边界,第二个分区大于
RIGHT是第一个分区小于边界,第二个分区大于等于
CREATE PARTITION FUNCTION [PartitionFunc](datetime) AS RANGE RIGHT FOR VALUES (N'2016-01-01T00:00:00', N'2016-04-01T00:00:00',N'2016-07-01T00:00:00',N'2016-10-01T00:00:00',N'2017-01-01T00:00:00')
建立分区方案
这个分区函数将分为6个文件组
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [Q1],[Q2],[Q3],[Q4],[PRIMARY])
建立好的分区函数和分区方案如下:
建立分区索引完成分区
分区索引必须是聚集索引,我们建标时用SQL里的主键设置会自动将ID设置为聚集索引这里我们需要把原先的主键改为分聚集索引,在建立分区索引。
CREATE CLUSTERED INDEX [ClusteredIndex_CreateDate] ON [dbo].[SchemTest]
(
[CreateDate]
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PartitionScheme]([CreateDate])
这样表分区就完成了。

查询分区中的数据
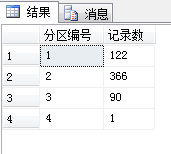
我们可以查下在不同分区中的数据,语句如下:
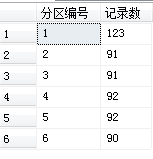
select $PARTITION.PartitionFunc(CreateDate) as 分区编号,count(ID) as 记录数 from SchemTest group by $PARTITION.PartitionFunc(CreateDate)
select * from SchemTest where $PARTITION.PartitionFunc(CreateDate)=1
这样查询所有2015年的数据。
分区新增和合并
现在 2015年的数据在2015文件组,2016年数据在4个季度的文件组,2017年数据在Primary的文件组,现在要将2016年的数据放在新增的2016文件组,4个季度的文件组放2017年的数据,Primary放2018年后的。
1.新建2016的文件组

2.分区合并
先将所有季度文件组都合并,这样2017年数据之前都在2015文件组
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-01-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-04-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-07-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-10-01T00:00:00');
可以在分区方案上查看创建SQL语句,这时的分区方案已经更改为:
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [PRIMARY])
3.分区新增
首先将2016年的数据放在Y2016文件组
--选择文件组
ALTER PARTITION SCHEME PartitionScheme
NEXT USED [Y2016] ;
--修改分区函数
ALTER PARTITION FUNCTION PartitionFunc()
SPLIT RANGE (N'2016-01-01T00:00:00.000') ;
同理将2017年的数据分别放在2017年的各个季度中
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2017-01-01T00:00:00');
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q1] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-01-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q2] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-04-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q3] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-07-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q4] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-10-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [PRIMARY] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2018-01-01T00:00:00.000') ;
现在查看分区函数和分区方案的创建语句如下:
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [Y2016], [Q1], [Q2], [Q3], [Q4], [PRIMARY])
CREATE PARTITION FUNCTION [PartitionFunc](datetime) AS RANGE RIGHT FOR VALUES (N'2016-01-01T00:00:00.000', N'2017-01-01T00:00:00.000', N'2017-04-01T00:00:00.000', N'2017-07-01T00:00:00.000', N'2017-10-01T00:00:00.000', N'2018-01-01T00:00:00.000')
分区记录如下:
如果分区变动比较大不推荐用合并和删除的方法,因为容易出错,如果分12个月建议像下面一样,先将分区表转换为普通表,再把普通表分区。
将分区表转换成普通表
1.删除分区索引
删除分区索引后,并没有编程普通表
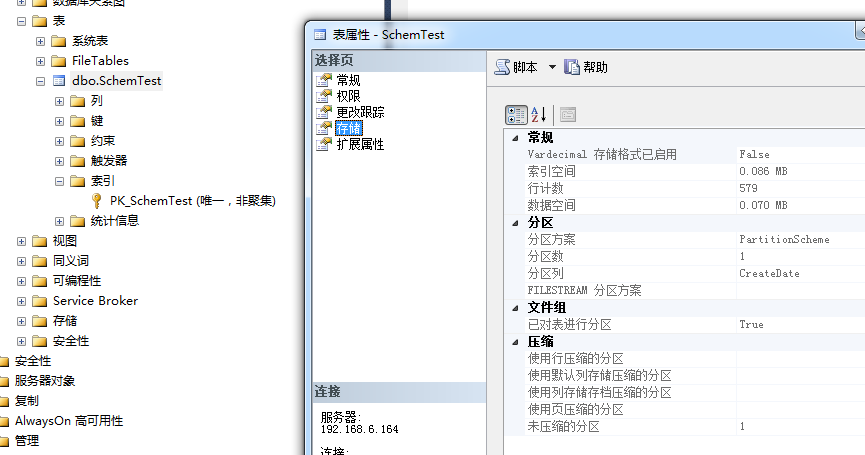
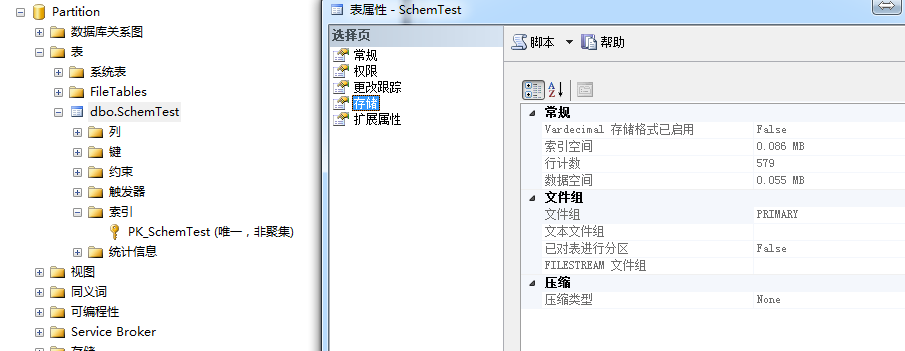
2.在原有分区索引字段,建立普通索引
CREATE CLUSTERED INDEX [IX_SchemTest] ON SchemTest(CreateDate) ON [Primary]
SQL SERVER分区具体例子详解的更多相关文章
- SQL Server 执行计划操作符详解(3)——计算标量(Compute Scalar)
接上文:SQL Server 执行计划操作符详解(2)--串联(Concatenation ) 前言: 前面两篇文章介绍了关于串联(Concatenation)和断言(Assert)操作符,本文介绍第 ...
- SQL Server 执行计划操作符详解(2)——串联(Concatenation )
本文接上文:SQL Server 执行计划操作符详解(1)--断言(Assert) 前言: 根据计划,本文开始讲述另外一个操作符串联(Concatenation),读者可以根据这个词(中英文均可)先幻 ...
- SQL Server 事务隔离级别详解
标签: SQL SEERVER/MSSQL SERVER/SQL/事务隔离级别选项/设置数据库事务级别 SQL 事务隔离级别 概述 隔离级别用于决定如果控制并发用户如何读写数据的操作,同时对性能也有一 ...
- SQL Server中的锁 详解 nolock,rowlock,tablock,xlock,paglock
摘自: http://www.myexception.cn/sql-server/385562.html 高手进 锁 nolock,rowlock,tablock,xlock,paglock 锁 no ...
- SQL Server 执行计划操作符详解(1)——断言(Assert)
前言: 很多很多地方对于语句的优化,一般比较靠谱的回复即使--把执行计划发出来看看.当然那些只看语句就说如何如何改代码,我一直都是拒绝的,因为这种算是纯蒙.根据本人经验,大量的性能问题单纯从语句来看很 ...
- 【转】SQL Server 事务隔离级别详解
SQL 事务隔离级别 概述 隔离级别用于决定如果控制并发用户如何读写数据的操作,同时对性能也有一定的影响作用. 步骤 事务隔离级别通过影响读操作来间接地影响写操作:可以在回话级别上设置事务隔离级别也可 ...
- sql server中的日期详解使用(convert)
转自:http://blog.csdn.net/hehe520347/article/details/48496853 有个字段值例如2012-07-02 00:00:00.000 转化成 2012- ...
- SQL Server:孤立用户详解
SQL Server 的用户安全管理分两层,整个SQL Server 服务器一层,每个数据库一层. 在服务器层的帐号,叫登录账户(SQL Server:服务器角色),可以设置它管理整个SQL Serv ...
- SQL Server DBA工作内容详解
在Microsoft SQL Server 2008系统中,数据库管理员(Database Administration,简称为DBA)是最重要的角色.DBA的工作目标就是确保Microsoft SQ ...
随机推荐
- Delphi 的绘图功能[10] - TFONT 类
Delphi 的绘图功能[10] - TFONT 类 ;DEFAULT_CHARSET = ;SYMBOL_CHARSET = ;SHIFTJIS_CHARSET = ;HAN ...
- SQL复习六(视图)
视图是关系数据库系统提供给用户以多角度观察数据库中数据的一种重要方法.视图是从一个或者几个表中导出的虚拟表.视图一经定义就可以被查询和删除.也可以在视图上定义视图.用视图完成数据的更新(增,删,改)操 ...
- php的autoload机制
php5版本中,当你尝试使用一个未定义的类或者接口时,会自动调用__autoload()函数 例如1 <?php function __autoload($class_name){ includ ...
- 基于LNMP的Zabbbix之Zabbix Agent源码详细安装,但不给图
基于LNMP的Zabbbix之Zabbix Server源码详细安装:http://www.cnblogs.com/losbyday/p/5828547.html wget http://jaist. ...
- LNMP的安装
一.安装Linux 安装某个linux桌面版系统,基本是ubuntu即可. 安装必要的库,如:pcre.xml.openssl.zlib等,sudo apt-get install libpcre3 ...
- ZOJ 3933 Team Formation
费用流裸题......比赛的时候少写了一句话....导致增加了很多无用的边一直在TLE #include<cstdio> #include<cstring> #include& ...
- LPC1768的看门狗定时器使用
void wwdg_init(void) { LPC_SC->PCLKSEL0 |= (3<<0);//分频数为八分频 LPC_WDT->WDCLKSEL &= ~(3 ...
- LPC1768的SPI通讯
SPI是一种全双工串行接口,可处理多个连接到指定总线上的主机和从机.在数据传输过程中总线上只能有一个主机和一个从机通信.在数据传输中,主机总是会向从机发送一帧8到16个位的数据,而从机也总会向主机发送 ...
- POJ 3991 Seinfeld
首先进行一次括号匹配,把正确匹配的全部删去. 删去之后剩下的状态肯定是 L个连续右括号+R个连续左括号. 如果L是偶数,答案是L/2+R/2: 否则答案是 (L-1)/2+(R-1)/2+2: #in ...
- PHPCMS快速建站系列之搜索功能
默认模板的搜索功能代码 <div class="bd"> <form action="{APP_PATH}index.php" method= ...