图文解析Spark2.0核心技术(转载)
导语
Spark2.0于2016-07-27正式发布,伴随着更简单、更快速、更智慧的新特性,spark 已经逐步替代 hadoop 在大数据中的地位,成为大数据处理的主流标准。本文主要以代码和绘图的方式结合,对运行架构、RDD 的实现、spark 作业原理、Sort-Based Shuffle 的存储原理、 Standalone 模式 HA 机制进行解析。
1、运行架构
Spark支持多种运行模式。单机部署下,既可以用本地(Local)模式运行,也可以使用伪分布式模式来运行;当以分布式集群部署的时候,可以根据实际情况选择Spark自带的独立(Standalone)运行模式、YARN运行模式或者Mesos模式。虽然模式多,但是Spark的运行架构基本由三部分组成,包括SparkContext(驱动程序)、ClusterManager(集群资源管理器)和Executor(任务执行进程)。
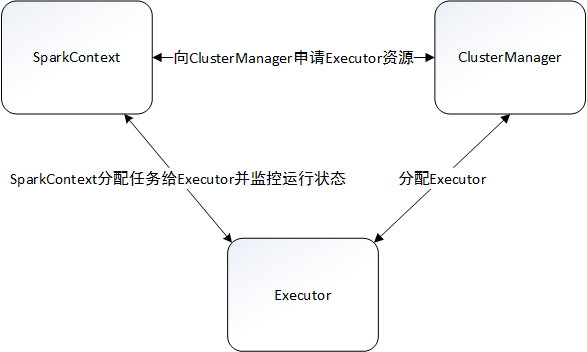
1、SparkContext提交作业,向ClusterManager申请资源;
2、ClusterManager会根据当前集群的资源使用情况,进行有条件的FIFO策略:先分配的应用程序尽可能多地获取资源,后分配的应用程序则在剩余资源中筛选,没有合适资源的应用程序只能等待其他应用程序释放资源;
3、ClusterManager默认情况下会将应用程序分布在尽可能多的Worker上,这种分配算法有利于充分利用集群资源,适合内存使用多的场景,以便更好地做到数据处理的本地性;另一种则是分布在尽可能少的Worker上,这种适合CPU密集型且内存使用较少的场景;
4、Excutor创建后与SparkContext保持通讯,SparkContext分配任务集给Excutor,Excutor按照一定的调度策略执行任务集。
2、RDD
弹性分布式数据集(Resilient Distributed Datasets,RDD)作为Spark的编程模型,相比MapReduce模型有着更好的扩展和延伸:
- 提供了抽象层次更高的API
- 高效的数据共享
- 高效的容错性
2.1、RDD 的操作类型
RDD大致可以包括四种操作类型:
- 创建操作(Creation):从内存集合和外部存储系统创建RDD,或者是通过转换操作生成RDD
- 转换操作(Transformation):转换操作是惰性操作,只是定义一个RDD并记录依赖关系,没有立即执行
- 控制操作(Control):进行RDD的持久化,通过设定不同级别对RDD进行缓存
- 行动操作(Action):触发任务提交、Spark运行的操作,操作的结果是获取到结果集或者保存至外部存储系统
2.2、RDD 的实现
2.2.1、RDD 的分区
RDD的分区是一个逻辑概念,转换操作前后的分区在物理上可能是同一块内存或者存储。在RDD操作中用户可以设定和获取分区数目,默认分区数目为该程序所分配到的cpu核数,如果是从HDFS文件创建,默认为文件的分片数。
2.2.2、RDD 的“血统”和依赖关系

“血统”和依赖关系:RDD 的容错机制是通过记录更新来实现的,且记录的是粗粒度的转换操作。我们将记录的信息称为血统(Lineage)关系,而到了源码级别,Apache Spark 记录的则是 RDD 之间的依赖(Dependency)关系。如上所示,每次转换操作产生一个新的RDD(子RDD),子RDD会记录其父RDD的信息以及相关的依赖关系。
2.2.3、依赖关系
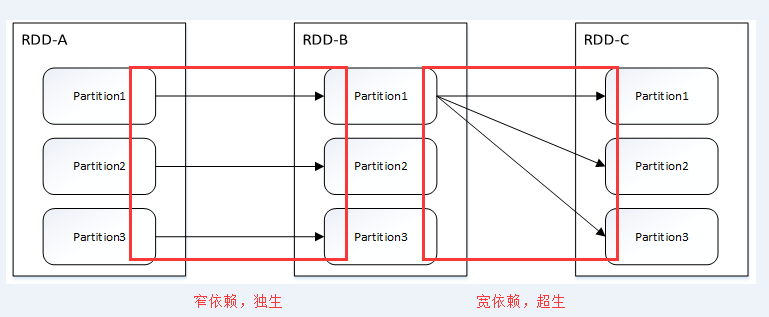
依赖关系划分为两种:窄依赖(Narrow Dependency)和 宽依赖(源码中为Shuffle Dependency)。
窄依赖指的是父 RDD 中的一个分区最多只会被子 RDD 中的一个分区使用,意味着父RDD的一个分区内的数据是不能被分割的,子RDD的任务可以跟父RDD在同一个Executor一起执行,不需要经过 Shuffle 阶段去重组数据。
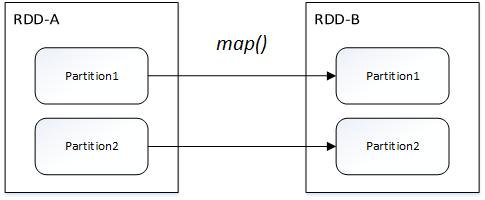
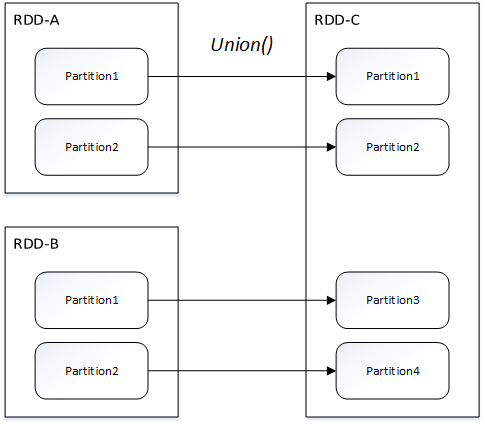
窄依赖包括两种:一对一依赖(OneToOneDependency)和范围依赖(RangeDependency)
一对一依赖:
范围依赖(仅union方法):
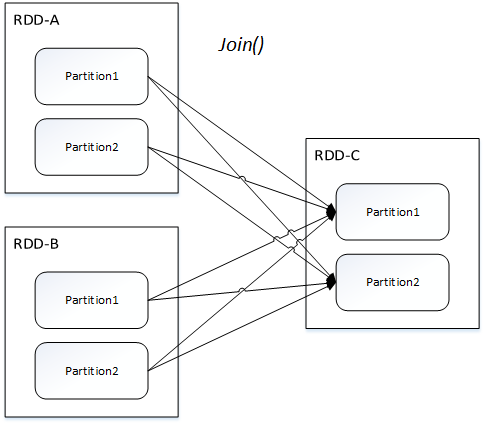
宽依赖指的是父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割,发送给子 RDD 的所有分区,因此宽依赖也意味着父 RDD 与子 RDD 之间存在着 Shuffle 过程。
宽依赖只有一种:Shuffle依赖(ShuffleDependency)
3、作业执行原理
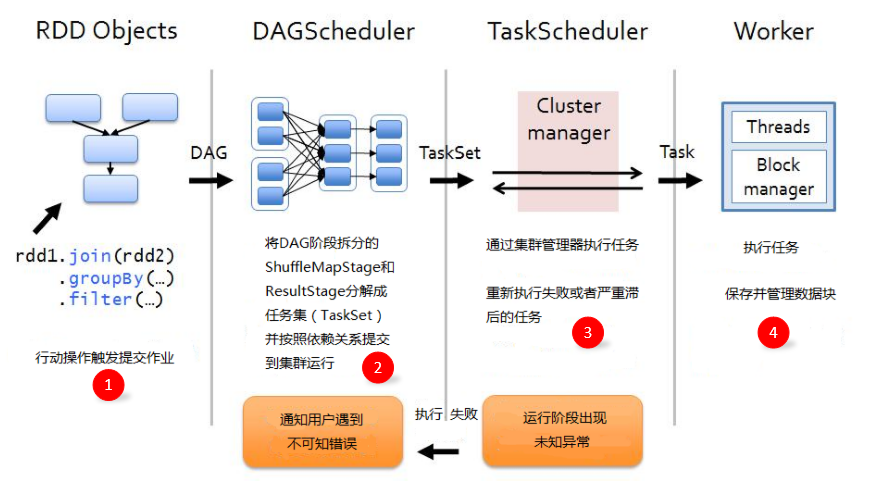
作业(Job):RDD每一个行动操作都会生成一个或者多个调度阶段 调度阶段(Stage):每个Job都会根据依赖关系,以Shuffle过程作为划分,分为Shuffle Map Stage和Result Stage。每个Stage包含多个任务集(TaskSet),TaskSet的数量与分区数相同。
任务(Task):分发到Executor上的工作任务,是Spark的最小执行单元 DAGScheduler:DAGScheduler是面向调度阶段的任务调度器,负责划分调度阶段并提交给TaskScheduler
TaskScheduler:TaskScheduler是面向任务的调度器,它负责将任务分发到Woker节点,由Executor进行执行
3.1、提交作业及作业调度策略(适用于调度阶段)

每一次行动操作都会触发SparkContext的runJob方法进行作业的提交。
这些作业之间可以没有任何依赖关系,对于多个作业之间的调度,共有两种:一种是默认的FIFO模式,另一种则是FAIR模式,该模式的调度可以通过设定minShare(最小任务数)和weight(任务的权重)来决定Job执行的优先级。
FIFO调度策略:优先比较作业优先级(作业编号越小优先级越高),再比较调度阶段优先级(调度阶段编号越小优先级越高)
FAIR调度策略:先获取两个调度的饥饿程度,是否处于饥饿状态由当前正在运行的任务是否小于最小任务决定,获取后进行如下比较:
- 优先满足处于饥饿状态的调度
- 同处于饥饿状态,优先满足资源比小的调度
- 同处于非饥饿状态,优先满足权重比小的调度
- 以上情况均相同的情况下,根据调度名称进行排序
3.2、划分调度阶段(DAG构建)
DAG构建图:
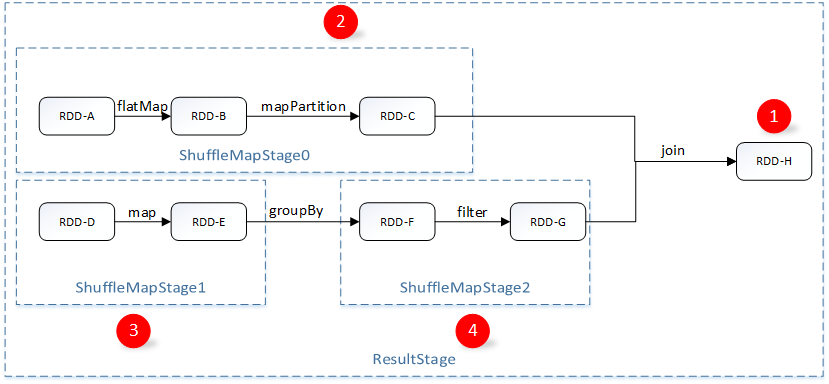
DAG的构建:主要是通过对最后一个RDD进行递归,使用广度优先遍历每个RDD跟父RDD的依赖关系(前面提到子RDD会记录依赖关系),碰到ShuffleDependency的则进行切割。切割后形成TaskSet传递给TaskScheduler进行执行。
DAG的作用:让窄依赖的RDD操作合并为同一个TaskSet,将多个任务进行合并,有利于任务执行效率的提高。
TaskSet结构图:假设数据有两个Partition时,TaskSet是一组关联的,但相互之间没有Shuffle依赖关系的Task集合,TaskSet的ShuffleMapStage数量跟Partition个数相关,主要包含task的集合,stage中的rdd信息等等。Task会被序列化和压缩
4、存储原理(Sort-Based Shuffle分析)
4.1、Shuffle过程解析(wordcount实例)
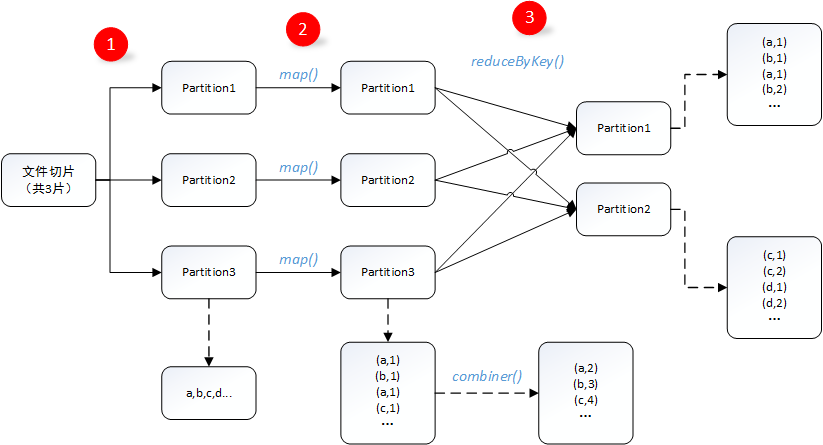
1. 数据处理:文件在hdfs中以多个切片形式存储,读取时每一个切片会被分配给一个Excutor进行处理;
2. map端操作:map端对文件数据进行处理,格式化为(key,value)键值对,每个map都可能包含a,b,c,d等多个字母,如果在map端使用了combiner,则数据会被压缩,value值会被合并;(注意:这个过程的使用需要保证对最终结果没有影响,有利于减少shuffle过程的数据传输);
3.reduce端操作:reduce过程中,假设a和b,c和d在同一个reduce端,需要将map端被分配在同一个reduce端的数据进行洗牌合并,这个过程被称之为shuffle。
4.2、map端的写操作
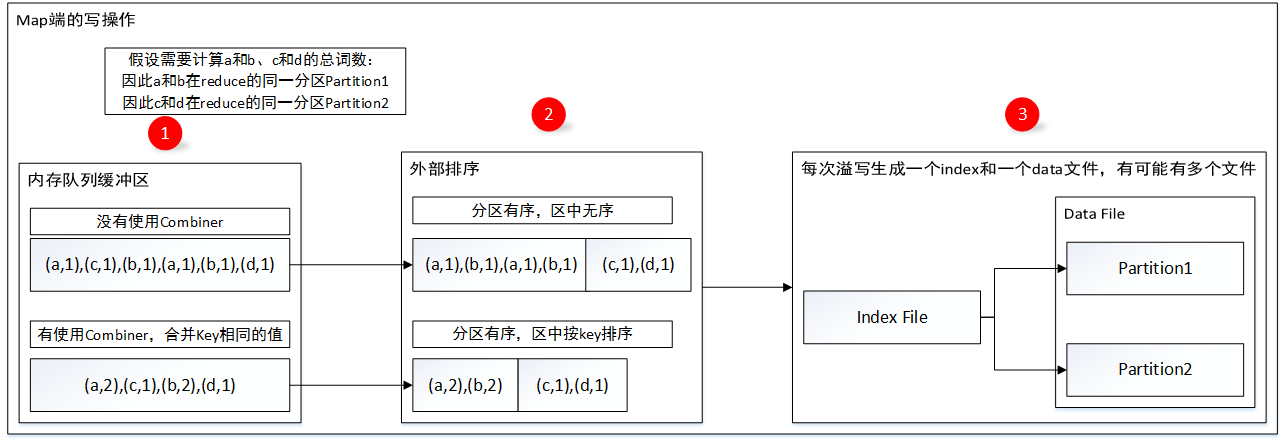
1.map端处理数据的时候,先判断这个过程是否使用了combiner,如果使用了combiner则采用PartitionedAppendOnlyMap数据结构作为内存缓冲区进行数据存储,对于相同key的数据每次都会进行更新合并;如果没有使用combiner,则采用PartitionedPairBuffer数据结构,把每次处理的数据追加到队列末尾;
2.写入数据的过程中如果出现内存不够用的情况则会发生溢写,溢写;使用combiner的则会将数据按照分区id和数据key进行排序,做到分区有序,区中按key排序,其实就是将partitionId和数据的key作为key进行排序;没有使用combiner的则只是分区有序;
3.按照排序后的数据溢写文件,文件分为data文件和index文件,index文件作为索引文件索引data文件的数据,有利于reduce端的读取;(注意:每次溢写都会形成一个index和data文件,在map完全处理完后会将多个inde和data文件Merge为一个index和data文件)
4.3、reduce端的读操作
有了map端的处理,reduce端只需要根据index文件就可以很好地获取到数据并进行相关的处理操作。这里主要讲reduce端读操作时对数据读取的策略:
如果在本地有,那么可以直接从BlockManager中获取数据;如果需要从其他的节点上获取,由于Shuffle过程的数据量可能会很大,为了减少请求数据的时间并且充分利用带宽,因此这里的网络读有以下的策略:
1.每次最多启动5个线程去最多5个节点上读取数据;
2.每次请求的数据大小不会超过spark.reducer.maxMbInFlight(默认值为48MB)/5
5、Spark的HA机制(Standalone模式)
5.1、Executor异常
当Executor发生异常退出的情况,Master会尝试获取可用的Worker节点并启动Executor,这个Worker很可能是失败之前运行Executor的Worker节点。这个过程系统会尝试10次,限定失败次数是为了避免因为应用程序存在bug而反复提交,占用集群宝贵的资源。
5.2、Worker异常
Worker会定时发送心跳给Master,Master也会定时检测注册的Worker是否超时,如果Worker异常,Master会告知Driver,并且同时将这些Executor从其应用程序列表中删除。
5.3、Master异常
1、ZooKeeper:将集群元数据持久化到ZooKeeper,由ZooKeeper通过选举机制选举出新的Master,新的Master从ZooKeeper中获取集群信息并恢复集群状态;
2、FileSystem:集群元数据持久化到本地文件系统中,当Master出现异常只需要重启Master即可;
3、Custom:通过对StandaloneRecoveryModeFactory抽象类进行实现并配置到系统中,由用户自定义恢复方式。
图文解析Spark2.0核心技术(转载)的更多相关文章
- hadoop-2.7.3.tar.gz + spark-2.0.2-bin-hadoop2.7.tgz + zeppelin-0.6.2-incubating-bin-all.tgz(master、slave1和slave2)(博主推荐)(图文详解)
不多说,直接上干货! 我这里,采取的是ubuntu 16.04系统,当然大家也可以在CentOS6.5里,这些都是小事 CentOS 6.5的安装详解 hadoop-2.6.0.tar.gz + sp ...
- 数据结构图文解析之:直接插入排序及其优化(二分插入排序)解析及C++实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:数组、单链表、双链表介绍及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:栈的简介及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:队列详解与C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:AVL树详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:树的简介及二叉排序树C++模板实现.
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
随机推荐
- 由于更换硬盘没有删除系统自启动读取挂载硬盘导致系统报错:fsck.ext4 unable to resolve 'UUID=a4a7a0f7-b54f-4774-9fb1'
由于更换硬盘没有删除系统自启动读取挂载硬盘导致系统报错:fsck.ext4 unable to resolve 'UUID=a4a7a0f7-b54f-4774-9fb1' 此时进入系统已root模式 ...
- 【转】Reason: The specified virtual disk needs repair.
转自http://tscsh.blog.163.com/blog/static/200320103201393095248828/电脑突然断电后,或者非正常关机,ubuntu打不开了,出现错误提示 打 ...
- Matlab 矩阵函数
clear; clc; A = rand() cond(A) %求矩阵A的条件数 Det(A) %求方阵A的行列式 Dot(A,B) %矩阵A与B的点积 Eig(A) %方阵A的特征值和特征向量 No ...
- android linphone中opengl显示的实现
1,java层 在界面中创建GL2JNIView(基类为GLSurfaceView). 创建对象AndroidVideoWindowImpl,将GL2JNIView作为参数传入构造函数.在该对象中监听 ...
- win8/win7中使用Git Extensions PuTTy模式提交时 git-credential-winstore.exe": No such file or directory 错误解决方案
参考:http://www.cnblogs.com/hlizard/p/3627792.html 报错类似以下错误 \"F:/GitExtensions/GitCredentialWinSt ...
- sencha touch 在线实战培训 第一期 第三节
2014.1.2晚上8点开的课 讲课进度比较快,好多同学反应说有些跟不上了... 呃,本期的课程是需要有一定的基础的. 建议大家多看看http://www.cnblogs.com/mlzs/p/346 ...
- ThinkPHP-5.0.23新的RCE漏洞测试和POC
TP5新RCE漏洞 昨天又是周五,讨厌周五曝漏洞,还得又得加班,算了,还是先验证一波.新的TP5RCE,据说发现者因为上次的RCE,于是又审计了代码,结果发现的.TP5也成了万人轮啊. 测试 环境搭建 ...
- python selenium操作表格式元素实例
很多时候,网页上的布局都是表格形式的,如出下面这样的 这种网页类型在自动化中比较头痛,需要很多判断,下面就举个例子,这里以深圳出入境网页为例,http://yysl.sz3e.com/wsyysq/s ...
- 关于Django的序列化
阅读目录 Django支持的序列化格式 Django的序列化 Django支持的序列化格式 1 2 3 4 Identifier Information xml Serializes to and f ...
- Spring Framework框架容器核心源码逐步剖析
目录 构建Spring环境 Spring 版本 5.1.3.RELEASE 测试类 Spring 配置文件 测试方法Main 快速进入Debug查看IOC容器构建源码 Spring IOC源码步骤分析 ...